 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSamba+: General and Accurate Salient Object Detection via A More Unified Mamba-based Framework
Feb 02, 2026Existing salient object detection (SOD) models are generally constrained by the limited receptive fields of convolutional neural networks (CNNs) and quadratic computational complexity of Transformers. Recently, the emerging state-space model, namely Mamba, has shown great potential in balancing global receptive fields and computational efficiency. As a solution, we propose Saliency Mamba (Samba), a pure Mamba-based architecture that flexibly handles various distinct SOD tasks, including RGB/RGB-D/RGB-T SOD, video SOD (VSOD), RGB-D VSOD, and visible-depth-thermal SOD. Specifically, we rethink the scanning strategy of Mamba for SOD, and introduce a saliency-guided Mamba block (SGMB) that features a spatial neighborhood scanning (SNS) algorithm to preserve the spatial continuity of salient regions. A context-aware upsampling (CAU) method is also proposed to promote hierarchical feature alignment and aggregation by modeling contextual dependencies. As one step further, to avoid the "task-specific" problem as in previous SOD solutions, we develop Samba+, which is empowered by training Samba in a multi-task joint manner, leading to a more unified and versatile model. Two crucial components that collaboratively tackle challenges encountered in input of arbitrary modalities and continual adaptation are investigated. Specifically, a hub-and-spoke graph attention (HGA) module facilitates adaptive cross-modal interactive fusion, and a modality-anchored continual learning (MACL) strategy alleviates inter-modal conflicts together with catastrophic forgetting. Extensive experiments demonstrate that Samba individually outperforms existing methods across six SOD tasks on 22 datasets with lower computational cost, whereas Samba+ achieves even superior results on these tasks and datasets by using a single trained versatile model. Additional results further demonstrate the potential of our Samba framework.
CapeNext: Rethinking and refining dynamic support information for category-agnostic pose estimation
Nov 17, 2025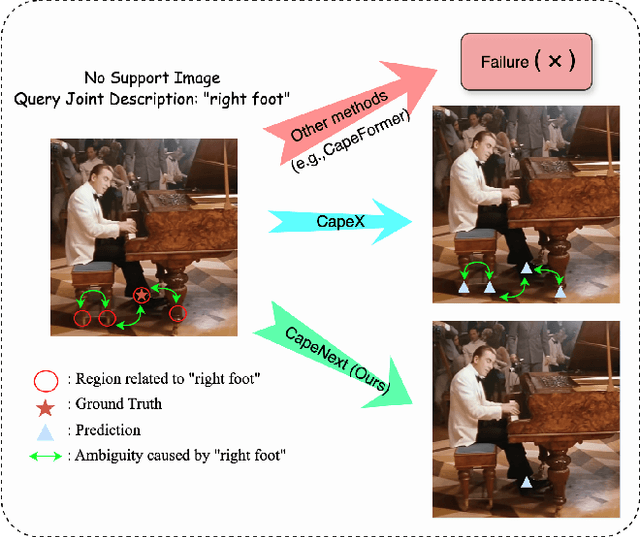
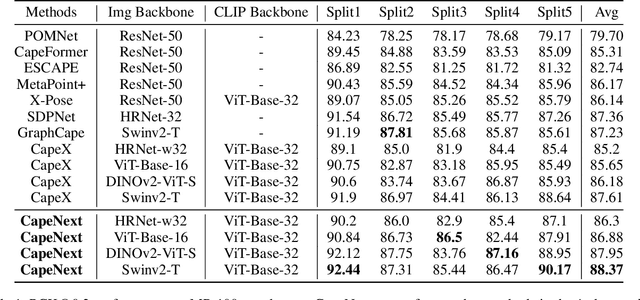
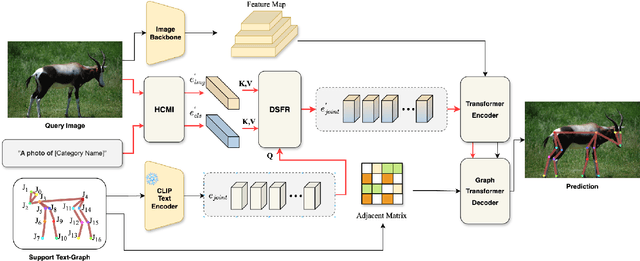
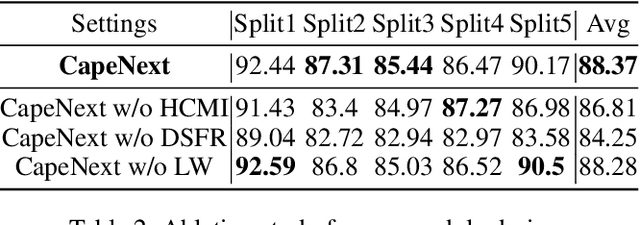
Recent research in Category-Agnostic Pose Estimation (CAPE) has adopted fixed textual keypoint description as semantic prior for two-stage pose matching frameworks. While this paradigm enhances robustness and flexibility by disentangling the dependency of support images, our critical analysis reveals two inherent limitations of static joint embedding: (1) polysemy-induced cross-category ambiguity during the matching process(e.g., the concept "leg" exhibiting divergent visual manifestations across humans and furniture), and (2) insufficient discriminability for fine-grained intra-category variations (e.g., posture and fur discrepancies between a sleeping white cat and a standing black cat). To overcome these challenges, we propose a new framework that innovatively integrates hierarchical cross-modal interaction with dual-stream feature refinement, enhancing the joint embedding with both class-level and instance-specific cues from textual description and specific images. Experiments on the MP-100 dataset demonstrate that, regardless of the network backbone, CapeNext consistently outperforms state-of-the-art CAPE methods by a large margin.
Mamba-based Efficient Spatio-Frequency Motion Perception for Video Camouflaged Object Detection
Jul 31, 2025Existing video camouflaged object detection (VCOD) methods primarily rely on spatial appearance features to perceive motion cues for breaking camouflage. However, the high similarity between foreground and background in VCOD results in limited discriminability of spatial appearance features (e.g., color and texture), restricting detection accuracy and completeness. Recent studies demonstrate that frequency features can not only enhance feature representation to compensate for appearance limitations but also perceive motion through dynamic variations in frequency energy. Furthermore, the emerging state space model called Mamba, enables efficient perception of motion cues in frame sequences due to its linear-time long-sequence modeling capability. Motivated by this, we propose a novel visual camouflage Mamba (Vcamba) based on spatio-frequency motion perception that integrates frequency and spatial features for efficient and accurate VCOD. Specifically, we propose a receptive field visual state space (RFVSS) module to extract multi-scale spatial features after sequence modeling. For frequency learning, we introduce an adaptive frequency component enhancement (AFE) module with a novel frequency-domain sequential scanning strategy to maintain semantic consistency. Then we propose a space-based long-range motion perception (SLMP) module and a frequency-based long-range motion perception (FLMP) module to model spatio-temporal and frequency-temporal sequences in spatial and frequency phase domains. Finally, the space and frequency motion fusion module (SFMF) integrates dual-domain features for unified motion representation. Experimental results show that our Vcamba outperforms state-of-the-art methods across 6 evaluation metrics on 2 datasets with lower computation cost, confirming the superiority of Vcamba. Our code is available at: https://github.com/BoydeLi/Vcamba.
Unleashing the Power of Motion and Depth: A Selective Fusion Strategy for RGB-D Video Salient Object Detection
Jul 29, 2025Applying salient object detection (SOD) to RGB-D videos is an emerging task called RGB-D VSOD and has recently gained increasing interest, due to considerable performance gains of incorporating motion and depth and that RGB-D videos can be easily captured now in daily life. Existing RGB-D VSOD models have different attempts to derive motion cues, in which extracting motion information explicitly from optical flow appears to be a more effective and promising alternative. Despite this, there remains a key issue that how to effectively utilize optical flow and depth to assist the RGB modality in SOD. Previous methods always treat optical flow and depth equally with respect to model designs, without explicitly considering their unequal contributions in individual scenarios, limiting the potential of motion and depth. To address this issue and unleash the power of motion and depth, we propose a novel selective cross-modal fusion framework (SMFNet) for RGB-D VSOD, incorporating a pixel-level selective fusion strategy (PSF) that achieves optimal fusion of optical flow and depth based on their actual contributions. Besides, we propose a multi-dimensional selective attention module (MSAM) to integrate the fused features derived from PSF with the remaining RGB modality at multiple dimensions, effectively enhancing feature representation to generate refined features. We conduct comprehensive evaluation of SMFNet against 19 state-of-the-art models on both RDVS and DVisal datasets, making the evaluation the most comprehensive RGB-D VSOD benchmark up to date, and it also demonstrates the superiority of SMFNet over other models. Meanwhile, evaluation on five video benchmark datasets incorporating synthetic depth validates the efficacy of SMFNet as well. Our code and benchmark results are made publicly available at https://github.com/Jia-hao999/SMFNet.
QEMesh: Employing A Quadric Error Metrics-Based Representation for Mesh Generation
Apr 08, 2025Mesh generation plays a crucial role in 3D content creation, as mesh is widely used in various industrial applications. Recent works have achieved impressive results but still face several issues, such as unrealistic patterns or pits on surfaces, thin parts missing, and incomplete structures. Most of these problems stem from the choice of shape representation or the capabilities of the generative network. To alleviate these, we extend PoNQ, a Quadric Error Metrics (QEM)-based representation, and propose a novel model, QEMesh, for high-quality mesh generation. PoNQ divides the shape surface into tiny patches, each represented by a point with its normal and QEM matrix, which preserves fine local geometry information. In our QEMesh, we regard these elements as generable parameters and design a unique latent diffusion model containing a novel multi-decoder VAE for PoNQ parameters generation. Given the latent code generated by the diffusion model, three parameter decoders produce several PoNQ parameters within each voxel cell, and an occupancy decoder predicts which voxel cells containing parameters to form the final shape. Extensive evaluations demonstrate that our method generates results with watertight surfaces and is comparable to state-of-the-art methods in several main metrics.
CamoSAM2: Motion-Appearance Induced Auto-Refining Prompts for Video Camouflaged Object Detection
Apr 01, 2025The Segment Anything Model 2 (SAM2), a prompt-guided video foundation model, has remarkably performed in video object segmentation, drawing significant attention in the community. Due to the high similarity between camouflaged objects and their surroundings, which makes them difficult to distinguish even by the human eye, the application of SAM2 for automated segmentation in real-world scenarios faces challenges in camouflage perception and reliable prompts generation. To address these issues, we propose CamoSAM2, a motion-appearance prompt inducer (MAPI) and refinement framework to automatically generate and refine prompts for SAM2, enabling high-quality automatic detection and segmentation in VCOD task. Initially, we introduce a prompt inducer that simultaneously integrates motion and appearance cues to detect camouflaged objects, delivering more accurate initial predictions than existing methods. Subsequently, we propose a video-based adaptive multi-prompts refinement (AMPR) strategy tailored for SAM2, aimed at mitigating prompt error in initial coarse masks and further producing good prompts. Specifically, we introduce a novel three-step process to generate reliable prompts by camouflaged object determination, pivotal prompting frame selection, and multi-prompts formation. Extensive experiments conducted on two benchmark datasets demonstrate that our proposed model, CamoSAM2, significantly outperforms existing state-of-the-art methods, achieving increases of 8.0% and 10.1% in mIoU metric. Additionally, our method achieves the fastest inference speed compared to current VCOD models.
Patch-Depth Fusion: Dichotomous Image Segmentation via Fine-Grained Patch Strategy and Depth Integrity-Prior
Mar 08, 2025Dichotomous Image Segmentation (DIS) is a high-precision object segmentation task for high-resolution natural images. The current mainstream methods focus on the optimization of local details but overlook the fundamental challenge of modeling the integrity of objects. We have found that the depth integrity-prior implicit in the the pseudo-depth maps generated by Depth Anything Model v2 and the local detail features of image patches can jointly address the above dilemmas. Based on the above findings, we have designed a novel Patch-Depth Fusion Network (PDFNet) for high-precision dichotomous image segmentation. The core of PDFNet consists of three aspects. Firstly, the object perception is enhanced through multi-modal input fusion. By utilizing the patch fine-grained strategy, coupled with patch selection and enhancement, the sensitivity to details is improved. Secondly, by leveraging the depth integrity-prior distributed in the depth maps, we propose an integrity-prior loss to enhance the uniformity of the segmentation results in the depth maps. Finally, we utilize the features of the shared encoder and, through a simple depth refinement decoder, improve the ability of the shared encoder to capture subtle depth-related information in the images. Experiments on the DIS-5K dataset show that PDFNet significantly outperforms state-of-the-art non-diffusion methods. Due to the incorporation of the depth integrity-prior, PDFNet achieves or even surpassing the performance of the latest diffusion-based methods while using less than 11% of the parameters of diffusion-based methods. The source code at https://github.com/Tennine2077/PDFNet.
Learning Adaptive and View-Invariant Vision Transformer with Multi-Teacher Knowledge Distillation for Real-Time UAV Tracking
Dec 28, 2024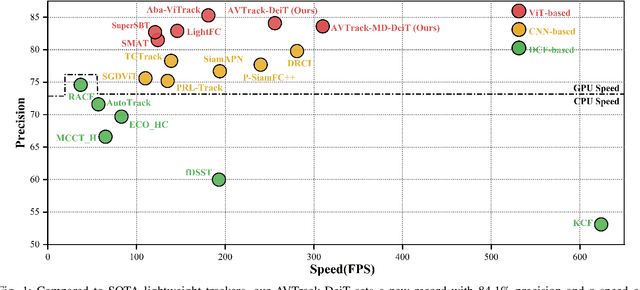
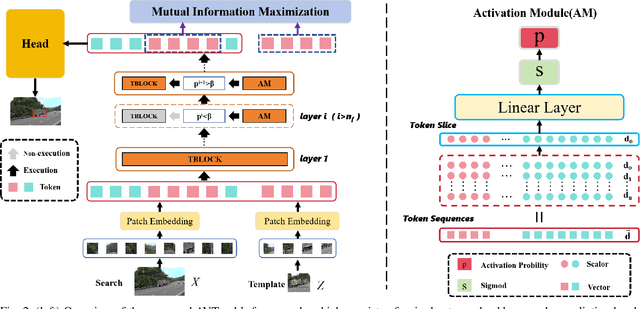
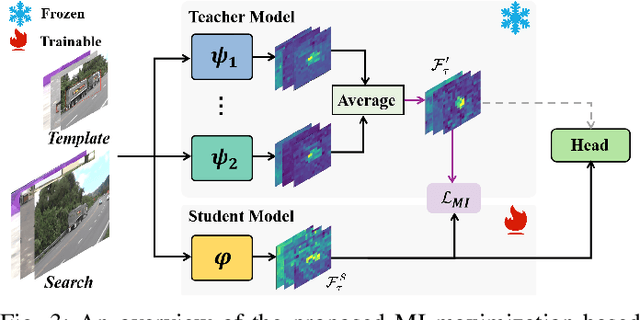
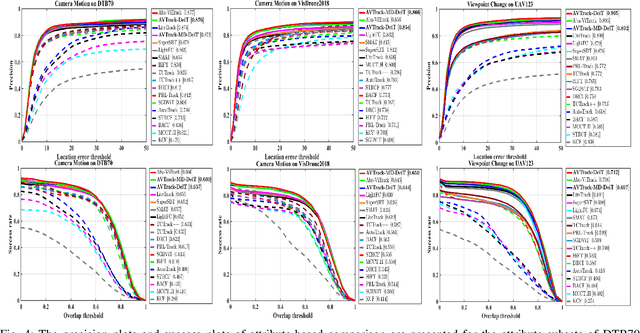
Visual tracking has made significant strides due to the adoption of transformer-based models. Most state-of-the-art trackers struggle to meet real-time processing demands on mobile platforms with constrained computing resources, particularly for real-time unmanned aerial vehicle (UAV) tracking. To achieve a better balance between performance and efficiency, we introduce AVTrack, an adaptive computation framework designed to selectively activate transformer blocks for real-time UAV tracking. The proposed Activation Module (AM) dynamically optimizes the ViT architecture by selectively engaging relevant components, thereby enhancing inference efficiency without significant compromise to tracking performance. Furthermore, to tackle the challenges posed by extreme changes in viewing angles often encountered in UAV tracking, the proposed method enhances ViTs' effectiveness by learning view-invariant representations through mutual information (MI) maximization. Two effective design principles are proposed in the AVTrack. Building on it, we propose an improved tracker, dubbed AVTrack-MD, which introduces the novel MI maximization-based multi-teacher knowledge distillation (MD) framework. It harnesses the benefits of multiple teachers, specifically the off-the-shelf tracking models from the AVTrack, by integrating and refining their outputs, thereby guiding the learning process of the compact student network. Specifically, we maximize the MI between the softened feature representations from the multi-teacher models and the student model, leading to improved generalization and performance of the student model, particularly in noisy conditions. Extensive experiments on multiple UAV tracking benchmarks demonstrate that AVTrack-MD not only achieves performance comparable to the AVTrack baseline but also reduces model complexity, resulting in a significant 17\% increase in average tracking speed.
MTFusion: Reconstructing Any 3D Object from Single Image Using Multi-word Textual Inversion
Nov 19, 2024Reconstructing 3D models from single-view images is a long-standing problem in computer vision. The latest advances for single-image 3D reconstruction extract a textual description from the input image and further utilize it to synthesize 3D models. However, existing methods focus on capturing a single key attribute of the image (e.g., object type, artistic style) and fail to consider the multi-perspective information required for accurate 3D reconstruction, such as object shape and material properties. Besides, the reliance on Neural Radiance Fields hinders their ability to reconstruct intricate surfaces and texture details. In this work, we propose MTFusion, which leverages both image data and textual descriptions for high-fidelity 3D reconstruction. Our approach consists of two stages. First, we adopt a novel multi-word textual inversion technique to extract a detailed text description capturing the image's characteristics. Then, we use this description and the image to generate a 3D model with FlexiCubes. Additionally, MTFusion enhances FlexiCubes by employing a special decoder network for Signed Distance Functions, leading to faster training and finer surface representation. Extensive evaluations demonstrate that our MTFusion surpasses existing image-to-3D methods on a wide range of synthetic and real-world images. Furthermore, the ablation study proves the effectiveness of our network designs.
* PRCV 2024
GenUDC: High Quality 3D Mesh Generation with Unsigned Dual Contouring Representation
Oct 23, 2024Generating high-quality meshes with complex structures and realistic surfaces is the primary goal of 3D generative models. Existing methods typically employ sequence data or deformable tetrahedral grids for mesh generation. However, sequence-based methods have difficulty producing complex structures with many faces due to memory limits. The deformable tetrahedral grid-based method MeshDiffusion fails to recover realistic surfaces due to the inherent ambiguity in deformable grids. We propose the GenUDC framework to address these challenges by leveraging the Unsigned Dual Contouring (UDC) as the mesh representation. UDC discretizes a mesh in a regular grid and divides it into the face and vertex parts, recovering both complex structures and fine details. As a result, the one-to-one mapping between UDC and mesh resolves the ambiguity problem. In addition, GenUDC adopts a two-stage, coarse-to-fine generative process for 3D mesh generation. It first generates the face part as a rough shape and then the vertex part to craft a detailed shape. Extensive evaluations demonstrate the superiority of UDC as a mesh representation and the favorable performance of GenUDC in mesh generation. The code and trained models are available at https://github.com/TrepangCat/GenUDC.