 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatch-Depth Fusion: Dichotomous Image Segmentation via Fine-Grained Patch Strategy and Depth Integrity-Prior
Mar 08, 2025Dichotomous Image Segmentation (DIS) is a high-precision object segmentation task for high-resolution natural images. The current mainstream methods focus on the optimization of local details but overlook the fundamental challenge of modeling the integrity of objects. We have found that the depth integrity-prior implicit in the the pseudo-depth maps generated by Depth Anything Model v2 and the local detail features of image patches can jointly address the above dilemmas. Based on the above findings, we have designed a novel Patch-Depth Fusion Network (PDFNet) for high-precision dichotomous image segmentation. The core of PDFNet consists of three aspects. Firstly, the object perception is enhanced through multi-modal input fusion. By utilizing the patch fine-grained strategy, coupled with patch selection and enhancement, the sensitivity to details is improved. Secondly, by leveraging the depth integrity-prior distributed in the depth maps, we propose an integrity-prior loss to enhance the uniformity of the segmentation results in the depth maps. Finally, we utilize the features of the shared encoder and, through a simple depth refinement decoder, improve the ability of the shared encoder to capture subtle depth-related information in the images. Experiments on the DIS-5K dataset show that PDFNet significantly outperforms state-of-the-art non-diffusion methods. Due to the incorporation of the depth integrity-prior, PDFNet achieves or even surpassing the performance of the latest diffusion-based methods while using less than 11% of the parameters of diffusion-based methods. The source code at https://github.com/Tennine2077/PDFNet.
Promoting Segment Anything Model towards Highly Accurate Dichotomous Image Segmentation
Dec 30, 2023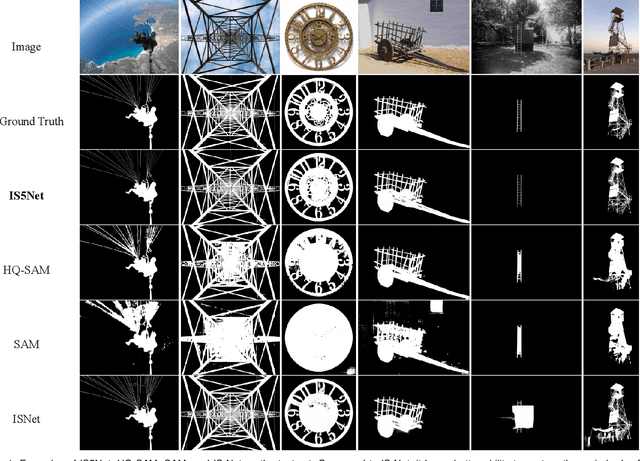
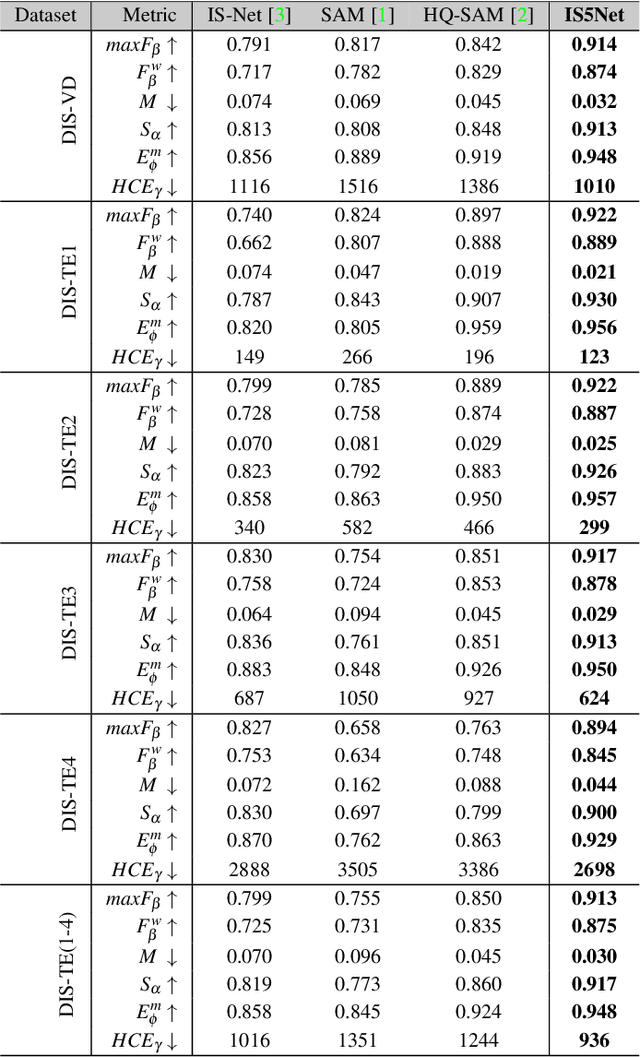


Segmenting any object represents a crucial step towards achieving artificial general intelligence, and the "Segment Anything Model" (SAM) has significantly advanced the development of foundational models in computer vision. We have high expectations regarding whether SAM can enhance highly accurate dichotomous image segmentation. In fact, the evidence presented in this article demonstrates that by inputting SAM with simple prompt boxes and utilizing the results output by SAM as input for IS5Net, we can greatly improve the effectiveness of highly accurate dichotomous image segmentation.
HGT: A Hierarchical GCN-Based Transformer for Multimodal Periprosthetic Joint Infection Diagnosis Using CT Images and Text
May 29, 2023


Prosthetic Joint Infection (PJI) is a prevalent and severe complication characterized by high diagnostic challenges. Currently, a unified diagnostic standard incorporating both computed tomography (CT) images and numerical text data for PJI remains unestablished, owing to the substantial noise in CT images and the disparity in data volume between CT images and text data. This study introduces a diagnostic method, HGT, based on deep learning and multimodal techniques. It effectively merges features from CT scan images and patients' numerical text data via a Unidirectional Selective Attention (USA) mechanism and a graph convolutional network (GCN)-based feature fusion network. We evaluated the proposed method on a custom-built multimodal PJI dataset, assessing its performance through ablation experiments and interpretability evaluations. Our method achieved an accuracy (ACC) of 91.4\% and an area under the curve (AUC) of 95.9\%, outperforming recent multimodal approaches by 2.9\% in ACC and 2.2\% in AUC, with a parameter count of only 68M. Notably, the interpretability results highlighted our model's strong focus and localization capabilities at lesion sites. This proposed method could provide clinicians with additional diagnostic tools to enhance accuracy and efficiency in clinical practice.
A multimodal method based on cross-attention and convolution for postoperative infection diagnosis
May 23, 2023



Postoperative infection diagnosis is a common and serious complication that generally poses a high diagnostic challenge. This study focuses on PJI, a type of postoperative infection. X-ray examination is an imaging examination for suspected PJI patients that can evaluate joint prostheses and adjacent tissues, and detect the cause of pain. Laboratory examination data has high sensitivity and specificity and has significant potential in PJI diagnosis. In this study, we proposed a self-supervised masked autoencoder pre-training strategy and a multimodal fusion diagnostic network MED-NVC, which effectively implements the interaction between two modal features through the feature fusion network of CrossAttention. We tested our proposed method on our collected PJI dataset and evaluated its performance and feasibility through comparison and ablation experiments. The results showed that our method achieved an ACC of 94.71% and an AUC of 98.22%, which is better than the latest method and also reduces the number of parameters. Our proposed method has the potential to provide clinicians with a powerful tool for enhancing accuracy and efficiency.
Uncertainty-informed Mutual Learning for Joint Medical Image Classification and Segmentation
Mar 30, 2023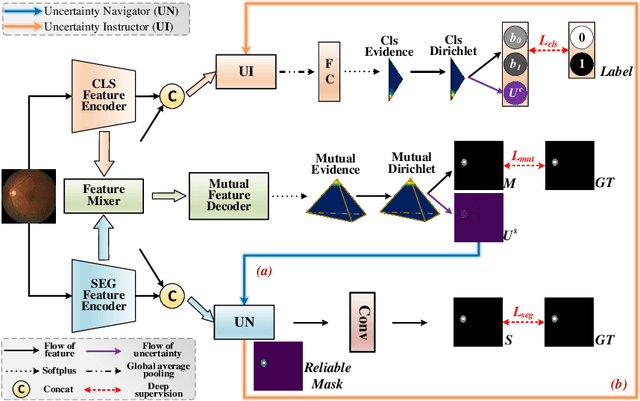



Classification and segmentation are crucial in medical image analysis as they enable accurate diagnosis and disease monitoring. However, current methods often prioritize the mutual learning features and shared model parameters, while neglecting the reliability of features and performances. In this paper, we propose a novel Uncertainty-informed Mutual Learning (UML) framework for reliable and interpretable medical image analysis. Our UML introduces reliability to joint classification and segmentation tasks, leveraging mutual learning with uncertainty to improve performance. To achieve this, we first use evidential deep learning to provide image-level and pixel-wise confidences. Then, an Uncertainty Navigator Decoder is constructed for better using mutual features and generating segmentation results. Besides, an Uncertainty Instructor is proposed to screen reliable masks for classification. Overall, UML could produce confidence estimation in features and performance for each link (classification and segmentation). The experiments on the public datasets demonstrate that our UML outperforms existing methods in terms of both accuracy and robustness. Our UML has the potential to explore the development of more reliable and explainable medical image analysis models. We will release the codes for reproduction after acceptance.