Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePromoting Segment Anything Model towards Highly Accurate Dichotomous Image Segmentation
Paper and Code
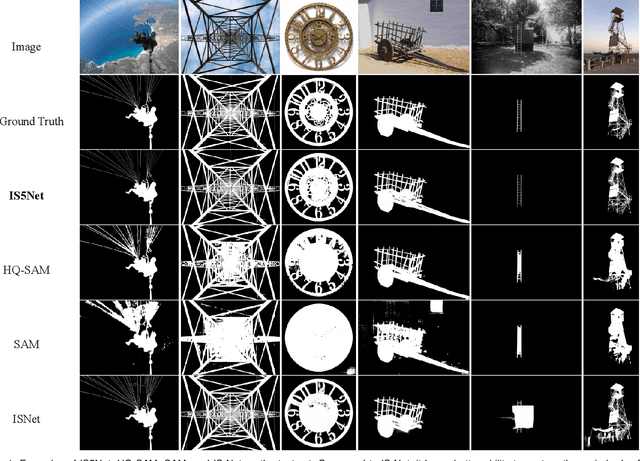
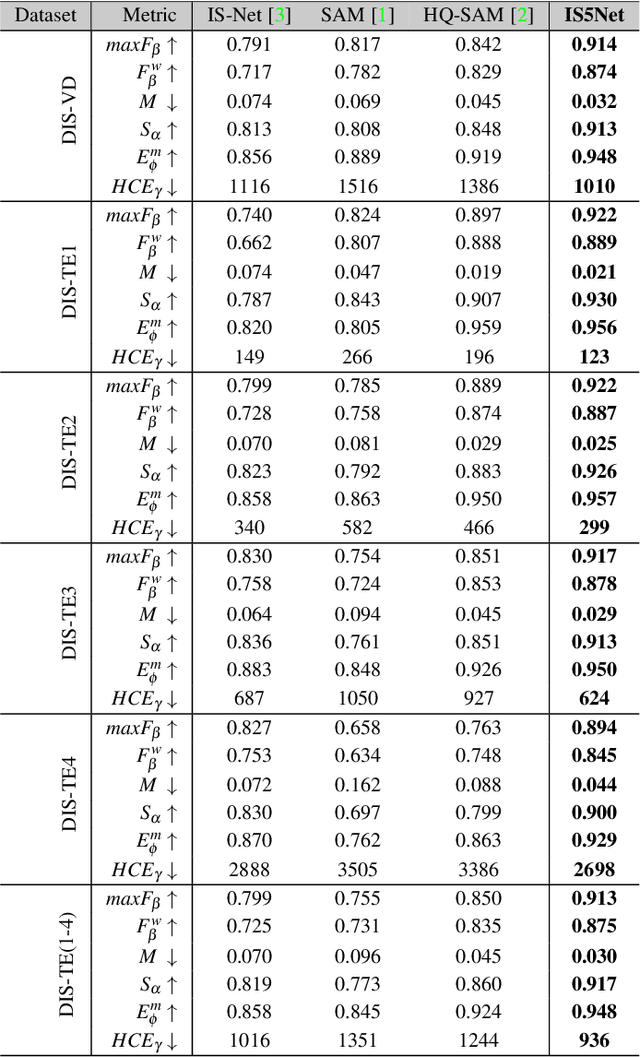


Segmenting any object represents a crucial step towards achieving artificial general intelligence, and the "Segment Anything Model" (SAM) has significantly advanced the development of foundational models in computer vision. We have high expectations regarding whether SAM can enhance highly accurate dichotomous image segmentation. In fact, the evidence presented in this article demonstrates that by inputting SAM with simple prompt boxes and utilizing the results output by SAM as input for IS5Net, we can greatly improve the effectiveness of highly accurate dichotomous image segmentation.
View paper on