 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhole-Body Constrained Learning for Legged Locomotion via Hierarchical Optimization
Jun 05, 2025Reinforcement learning (RL) has demonstrated impressive performance in legged locomotion over various challenging environments. However, due to the sim-to-real gap and lack of explainability, unconstrained RL policies deployed in the real world still suffer from inevitable safety issues, such as joint collisions, excessive torque, or foot slippage in low-friction environments. These problems limit its usage in missions with strict safety requirements, such as planetary exploration, nuclear facility inspection, and deep-sea operations. In this paper, we design a hierarchical optimization-based whole-body follower, which integrates both hard and soft constraints into RL framework to make the robot move with better safety guarantees. Leveraging the advantages of model-based control, our approach allows for the definition of various types of hard and soft constraints during training or deployment, which allows for policy fine-tuning and mitigates the challenges of sim-to-real transfer. Meanwhile, it preserves the robustness of RL when dealing with locomotion in complex unstructured environments. The trained policy with introduced constraints was deployed in a hexapod robot and tested in various outdoor environments, including snow-covered slopes and stairs, demonstrating the great traversability and safety of our approach.
Feature-Aware Noise Contrastive Learning For Unsupervised Red Panda Re-Identification
May 01, 2024



To facilitate the re-identification (Re-ID) of individual animals, existing methods primarily focus on maximizing feature similarity within the same individual and enhancing distinctiveness between different individuals. However, most of them still rely on supervised learning and require substantial labeled data, which is challenging to obtain. To avoid this issue, we propose a Feature-Aware Noise Contrastive Learning (FANCL) method to explore an unsupervised learning solution, which is then validated on the task of red panda re-ID. FANCL employs a Feature-Aware Noise Addition module to produce noised images that conceal critical features and designs two contrastive learning modules to calculate the losses. Firstly, a feature consistency module is designed to bridge the gap between the original and noised features. Secondly, the neural networks are trained through a cluster contrastive learning module. Through these more challenging learning tasks, FANCL can adaptively extract deeper representations of red pandas. The experimental results on a set of red panda images collected in both indoor and outdoor environments prove that FANCL outperforms several related state-of-the-art unsupervised methods, achieving high performance comparable to supervised learning methods.
From Function to Distribution Modeling: A PAC-Generative Approach to Offline Optimization
Jan 04, 2024



This paper considers the problem of offline optimization, where the objective function is unknown except for a collection of ``offline" data examples. While recent years have seen a flurry of work on applying various machine learning techniques to the offline optimization problem, the majority of these work focused on learning a surrogate of the unknown objective function and then applying existing optimization algorithms. While the idea of modeling the unknown objective function is intuitive and appealing, from the learning point of view it also makes it very difficult to tune the objective of the learner according to the objective of optimization. Instead of learning and then optimizing the unknown objective function, in this paper we take on a less intuitive but more direct view that optimization can be thought of as a process of sampling from a generative model. To learn an effective generative model from the offline data examples, we consider the standard technique of ``re-weighting", and our main technical contribution is a probably approximately correct (PAC) lower bound on the natural optimization objective, which allows us to jointly learn a weight function and a score-based generative model. The robustly competitive performance of the proposed approach is demonstrated via empirical studies using the standard offline optimization benchmarks.
Exactly Tight Information-Theoretic Generalization Error Bound for the Quadratic Gaussian Problem
May 01, 2023We provide a new information-theoretic generalization error bound that is exactly tight (i.e., matching even the constant) for the canonical quadratic Gaussian mean estimation problem. Despite considerable existing efforts in deriving information-theoretic generalization error bounds, applying them to this simple setting where sample average is used as the estimate of the mean value of Gaussian data has not yielded satisfying results. In fact, most existing bounds are order-wise loose in this setting, which has raised concerns about the fundamental capability of information-theoretic bounds in reasoning the generalization behavior for machine learning. The proposed new bound adopts the individual-sample-based approach proposed by Bu et al., but also has several key new ingredients. Firstly, instead of applying the change of measure inequality on the loss function, we apply it to the generalization error function itself; secondly, the bound is derived in a conditional manner; lastly, a reference distribution, which bears a certain similarity to the prior distribution in the Bayesian setting, is introduced. The combination of these components produces a general KL-divergence-based generalization error bound. We further show that although the conditional bounding and the reference distribution can make the bound exactly tight, removing them does not significantly degrade the bound, which leads to a mutual-information-based bound that is also asymptotically tight in this setting.
Learning to Predict 3D Lane Shape and Camera Pose from a Single Image via Geometry Constraints
Dec 31, 2021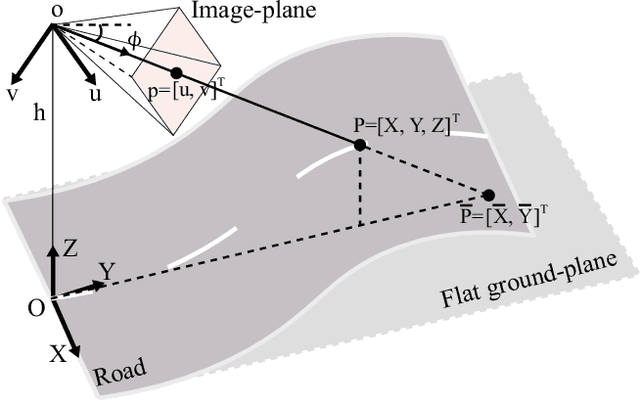
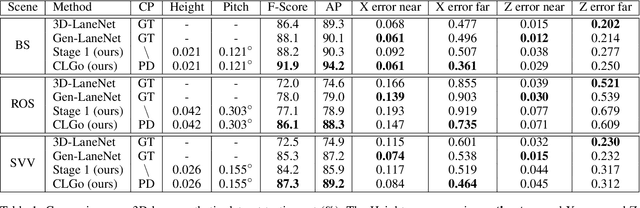
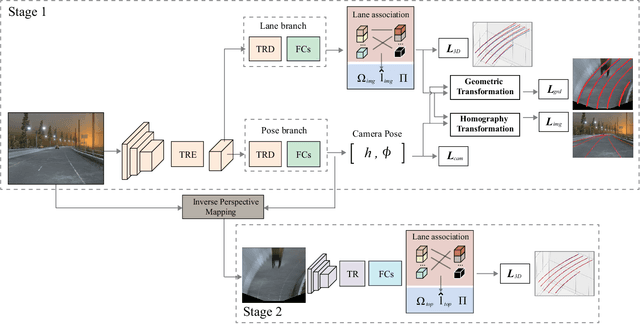
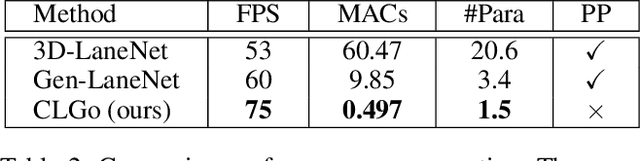
Detecting 3D lanes from the camera is a rising problem for autonomous vehicles. In this task, the correct camera pose is the key to generating accurate lanes, which can transform an image from perspective-view to the top-view. With this transformation, we can get rid of the perspective effects so that 3D lanes would look similar and can accurately be fitted by low-order polynomials. However, mainstream 3D lane detectors rely on perfect camera poses provided by other sensors, which is expensive and encounters multi-sensor calibration issues. To overcome this problem, we propose to predict 3D lanes by estimating camera pose from a single image with a two-stage framework. The first stage aims at the camera pose task from perspective-view images. To improve pose estimation, we introduce an auxiliary 3D lane task and geometry constraints to benefit from multi-task learning, which enhances consistencies between 3D and 2D, as well as compatibility in the above two tasks. The second stage targets the 3D lane task. It uses previously estimated pose to generate top-view images containing distance-invariant lane appearances for predicting accurate 3D lanes. Experiments demonstrate that, without ground truth camera pose, our method outperforms the state-of-the-art perfect-camera-pose-based methods and has the fewest parameters and computations. Codes are available at https://github.com/liuruijin17/CLGo.
Individually Conditional Individual Mutual Information Bound on Generalization Error
Dec 29, 2020
We propose a new information-theoretic bound on generalization error based on a combination of the error decomposition technique of Bu et al. and the conditional mutual information (CMI) construction of Steinke and Zakynthinou. In a previous work, Haghifam et al. proposed a different bound combining the two aforementioned techniques, which we refer to as the conditional individual mutual information (CIMI) bound. However, in a simple Gaussian setting, both the CMI and the CIMI bounds are order-wise worse than that by Bu et al.. This observation motivated us to propose the new bound, which overcomes this issue by reducing the conditioning terms in the conditional mutual information. In the process of establishing this bound, a conditional decoupling lemma is established, which also leads to a meaningful dichotomy and comparison among these information-theoretic bounds.
End-to-end Lane Shape Prediction with Transformers
Nov 09, 2020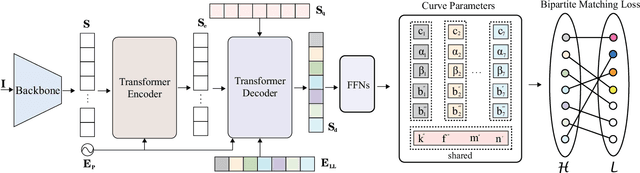
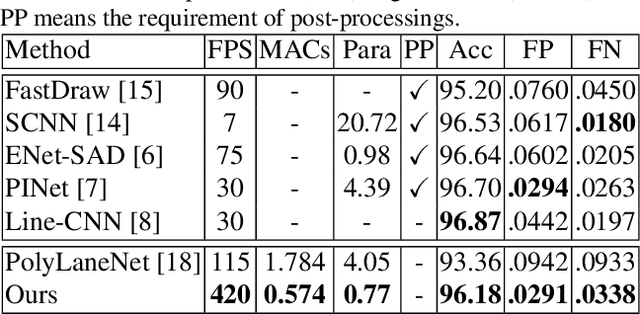
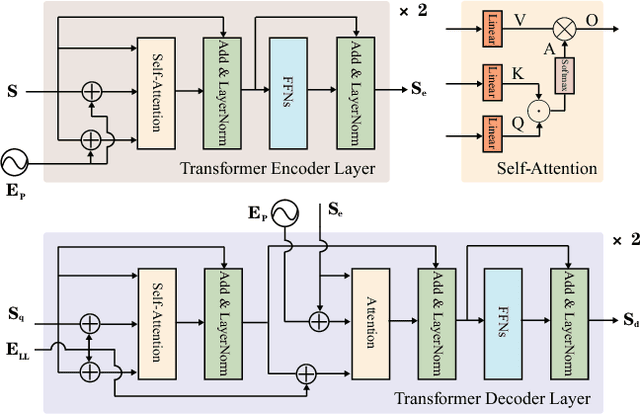

Lane detection, the process of identifying lane markings as approximated curves, is widely used for lane departure warning and adaptive cruise control in autonomous vehicles. The popular pipeline that solves it in two steps---feature extraction plus post-processing, while useful, is too inefficient and flawed in learning the global context and lanes' long and thin structures. To tackle these issues, we propose an end-to-end method that directly outputs parameters of a lane shape model, using a network built with a transformer to learn richer structures and context. The lane shape model is formulated based on road structures and camera pose, providing physical interpretation for parameters of network output. The transformer models non-local interactions with a self-attention mechanism to capture slender structures and global context. The proposed method is validated on the TuSimple benchmark and shows state-of-the-art accuracy with the most lightweight model size and fastest speed. Additionally, our method shows excellent adaptability to a challenging self-collected lane detection dataset, showing its powerful deployment potential in real applications. Codes are available at https://github.com/liuruijin17/LSTR.
Multiple Sample Clustering
Oct 24, 2019



The clustering algorithms that view each object data as a single sample drawn from a certain distribution, Gaussian distribution, for example, has been a hot topic for decades. Many clustering algorithms: such as k-means and spectral clustering are proposed based on the single sample assumption. However, in real life, each input object can usually be the multiple samples drawn from a certain hidden distribution. The traditional clustering algorithms cannot handle such a situation. This calls for the multiple sample clustering algorithm. But the traditional multiple sample clustering algorithms can only handle scalar samples or samples from Gaussian distribution. This constrains the application field of multiple sample clustering algorithms. In this paper, we purpose a general framework for multiple sample clustering. Various algorithms can be generated by this framework. We apply two specific cases of this framework: Wasserstein distance version and Bhattacharyya distance version on both synthetic data and stock price data. The simulation results show that the sufficient statistic can greatly improve the clustering accuracy and stability.
Removing Rain in Videos: A Large-scale Database and A Two-stream ConvLSTM Approach
Jun 06, 2019

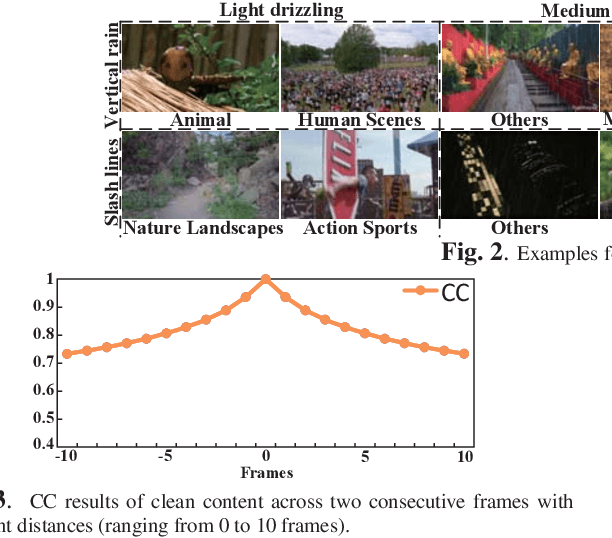
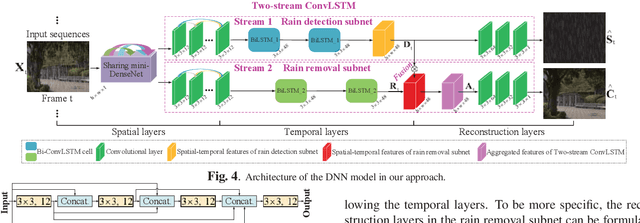
Rain removal has recently attracted increasing research attention, as it is able to enhance the visibility of rain videos. However, the existing learning based rain removal approaches for videos suffer from insufficient training data, especially when applying deep learning to remove rain. In this paper, we establish a large-scale video database for rain removal (LasVR), which consists of 316 rain videos. Then, we observe from our database that there exist the temporal correlation of clean content and similar patterns of rain across video frames. According to these two observations, we propose a two-stream convolutional long- and short- term memory (ConvLSTM) approach for rain removal in videos. The first stream is composed of the subnet for rain detection, while the second stream is the subnet of rain removal that leverages the features from the rain detection subnet. Finally, the experimental results on both synthetic and real rain videos show the proposed approach performs better than other state-of-the-art approaches.
MFQE 2.0: A New Approach for Multi-frame Quality Enhancement on Compressed Video
Feb 26, 2019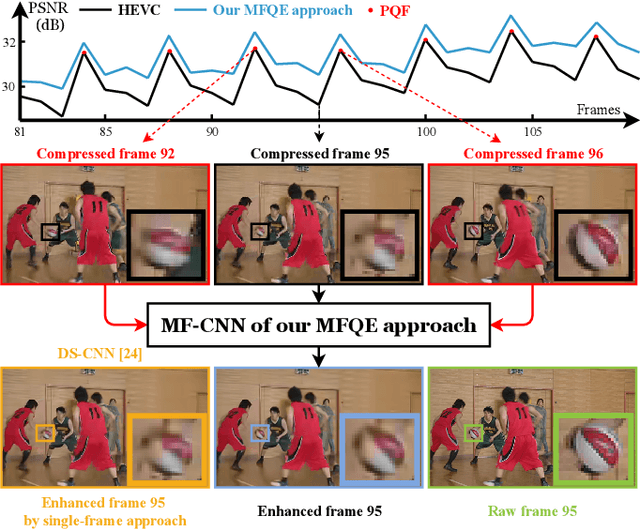
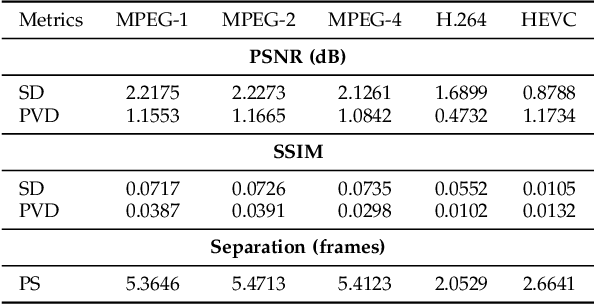

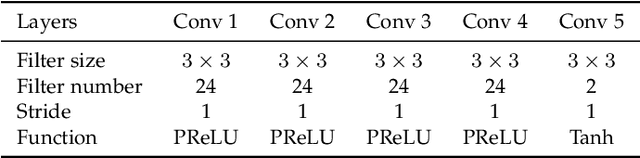
The past few years have witnessed great success in applying deep learning to enhance the quality of compressed image/video. The existing approaches mainly focus on enhancing the quality of a single frame, not considering the similarity between consecutive frames. Since heavy fluctuation exists across compressed video frames as investigated in this paper, frame similarity can be utilized for quality enhancement of low-quality frames by using their neighboring high-quality frames. This task can be seen as Multi-Frame Quality Enhancement (MFQE). Accordingly, this paper proposes an MFQE approach for compressed video, as the first attempt in this direction. In our approach, we firstly develop a Bidirectional Long Short-Term Memory (BiLSTM) based detector to locate Peak Quality Frames (PQFs) in compressed video. Then, a novel Multi-Frame Convolutional Neural Network (MF-CNN) is designed to enhance the quality of compressed video, in which the non-PQF and its nearest two PQFs are the input. In MF-CNN, motion between the non-PQF and PQFs is compensated by a motion compensation subnet. Subsequently, a quality enhancement subnet fuses the non-PQF and compensated PQFs, and then reduces the compression artifacts of the non-PQF. Finally, experiments validate the effectiveness and generalization ability of our MFQE approach in advancing the state-of-the-art quality enhancement of compressed video. The code of our MFQE approach is available at https://github.com/RyanXingQL/MFQE2.0.git.