 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAmbiguity Function Analysis of AFDM Under Pulse-Shaped Random ISAC Signaling
Nov 06, 2025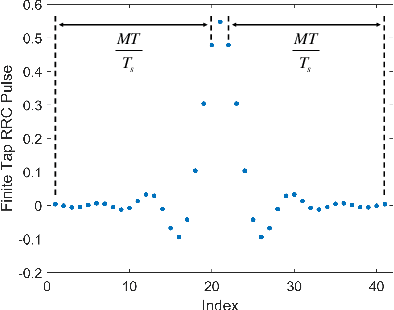
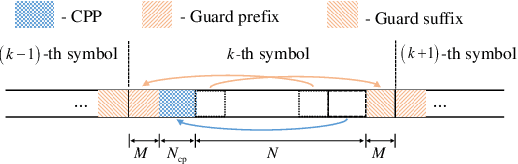
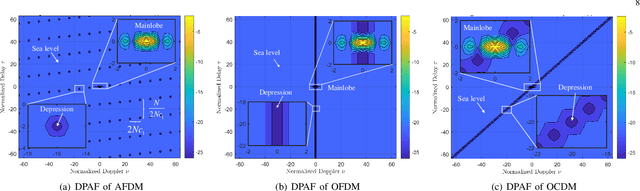
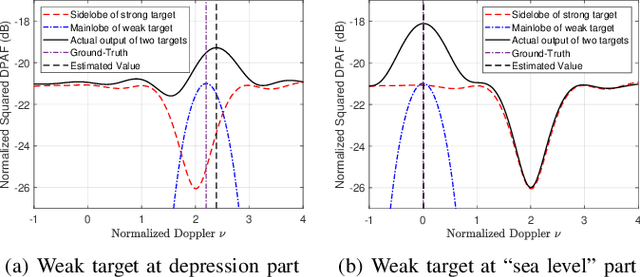
This paper investigates the ambiguity function (AF) of the emerging affine frequency division multiplexing (AFDM) waveform for Integrated Sensing and Communication (ISAC) signaling under a pulse shaping regime. Specifically, we first derive the closed-form expression of the average squared discrete period AF (DPAF) for AFDM waveform without pulse shaping, revealing that the AF depends on the parameter $c_1$ and the kurtosis of random communication data, while being independent of the parameter $c_2$. As a step further, we conduct a comprehensive analysis on the AFs of various waveforms, including AFDM, orthogonal frequency division multiplexing (OFDM) and orthogonal chirp-division multiplexing (OCDM). Our results indicate that all three waveforms exhibit the same number of regular depressions in the sidelobes of their AFs, which incurs performance loss for detecting and estimating weak targets. However, the AFDM waveform can flexibly control the positions of depressions by adjusting the parameter $c_1$, which motivates a novel design approach of the AFDM parameters to mitigate the adverse impact of depressions of the strong target on the weak target. Furthermore, a closed-form expression of the average squared DPAF for pulse-shaped random AFDM waveform is derived, which demonstrates that the pulse shaping filter generates the shaped mainlobe along the delay axis and the rapid roll-off sidelobes along the Doppler axis. Numerical results verify the effectiveness of our theoretical analysis and proposed design methodology for the AFDM modulation.
A Secure Affine Frequency Division Multiplexing for Wireless Communication Systems
Oct 02, 2025Affine frequency division multiplexing (AFDM) has garnered significant attention due to its superior performance in high-mobility scenarios, coupled with multiple waveform parameters that provide greater degrees of freedom for system design. This paper introduces a novel secure affine frequency division multiplexing (SE-AFDM) system, which advances prior designs by dynamically varying an AFDM pre-chirp parameter to enhance physical-layer security. In the SE-AFDM system, the pre-chirp parameter is dynamically generated from a codebook controlled by a long-period pseudo-noise (LPPN) sequence. Instead of applying spreading in the data domain, our parameter-domain spreading approach provides additional security while maintaining reliability and high spectrum efficiency. We also propose a synchronization framework to solve the problem of reliably and rapidly synchronizing the time-varying parameter in fast time-varying channels. The theoretical derivations prove that unsynchronized eavesdroppers cannot eliminate the nonlinear impact of the time-varying parameter and further provide useful guidance for codebook design. Simulation results demonstrate the security advantages of the proposed SE-AFDM system in high-mobility scenarios, while our hardware prototype validates the effectiveness of the proposed synchronization framework.
An Integrated Sensing and Communications System Based on Affine Frequency Division Multiplexing
Jan 31, 2025



This paper proposes an integrated sensing and communications (ISAC) system based on affine frequency division multiplexing (AFDM) waveform. To this end, a metric set is designed according to not only the maximum tolerable delay/Doppler, but also the weighted spectral efficiency as well as the outage/error probability of sensing and communications. This enables the analytical investigation of the performance trade-offs of AFDM-ISAC system using the derived analytical relation among metrics and AFDM waveform parameters. Moreover, by revealing that delay and the integral/fractional parts of normalized Doppler can be decoupled in the affine Fourier transform-Doppler domain, an efficient estimation method is proposed for our AFDM-ISAC system, whose unambiguous Doppler can break through the limitation of subcarrier spacing. Theoretical analyses and numerical results verify that our proposed AFDM-ISAC system may significantly enlarge unambiguous delay/Doppler while possessing good spectral efficiency and peak-to-sidelobe level ratio in high-mobility scenarios.
An AFDM-Based Integrated Sensing and Communications
Aug 29, 2022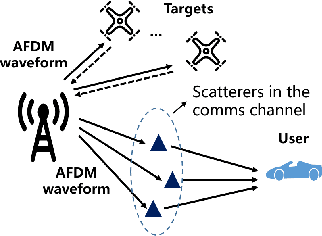
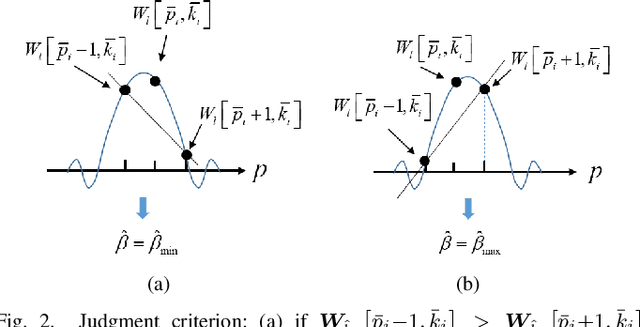
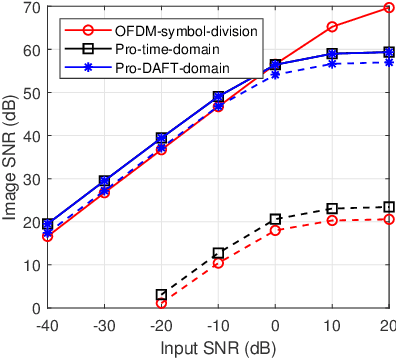
This paper considers an affine frequency division multiplexing (AFDM)-based integrated sensing and communications (ISAC) system, where the AFDM waveform is used to simultaneously carry communications information and sense targets. To realize AFDM-based sensing functionality, two parameter estimation methods are designed to process echoes in the time domain and the discrete affine Fourier transform (DAFT) domain, respectively. It allows us to decouple delay and Doppler shift in the fast time axis and can maintain good sensing performance even in large Doppler shift scenarios. Numerical results verify the effectiveness of our proposed AFDM-based system in high mobility scenarios.
Blind VQA on 360° Video via Progressively Learning from Pixels, Frames and Video
Nov 18, 2021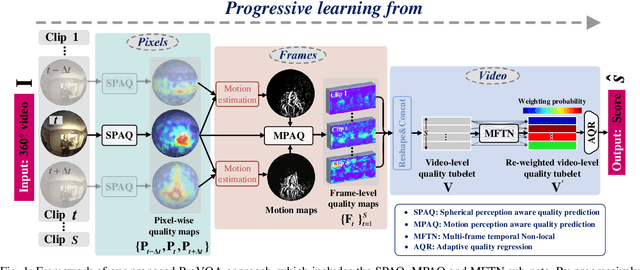
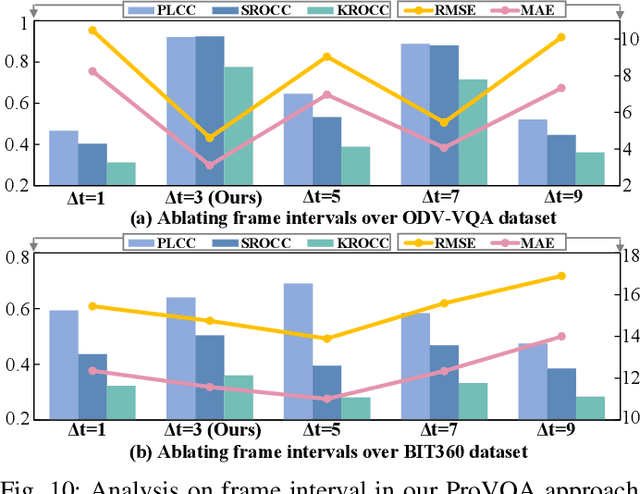
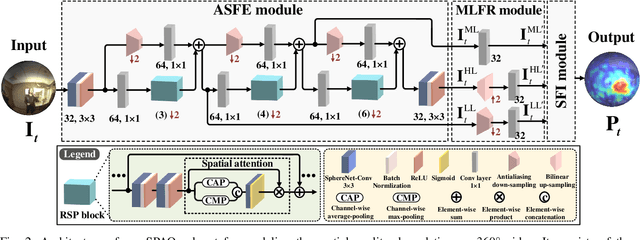

Blind visual quality assessment (BVQA) on 360{\textdegree} video plays a key role in optimizing immersive multimedia systems. When assessing the quality of 360{\textdegree} video, human tends to perceive its quality degradation from the viewport-based spatial distortion of each spherical frame to motion artifact across adjacent frames, ending with the video-level quality score, i.e., a progressive quality assessment paradigm. However, the existing BVQA approaches for 360{\textdegree} video neglect this paradigm. In this paper, we take into account the progressive paradigm of human perception towards spherical video quality, and thus propose a novel BVQA approach (namely ProVQA) for 360{\textdegree} video via progressively learning from pixels, frames and video. Corresponding to the progressive learning of pixels, frames and video, three sub-nets are designed in our ProVQA approach, i.e., the spherical perception aware quality prediction (SPAQ), motion perception aware quality prediction (MPAQ) and multi-frame temporal non-local (MFTN) sub-nets. The SPAQ sub-net first models the spatial quality degradation based on spherical perception mechanism of human. Then, by exploiting motion cues across adjacent frames, the MPAQ sub-net properly incorporates motion contextual information for quality assessment on 360{\textdegree} video. Finally, the MFTN sub-net aggregates multi-frame quality degradation to yield the final quality score, via exploring long-term quality correlation from multiple frames. The experiments validate that our approach significantly advances the state-of-the-art BVQA performance on 360{\textdegree} video over two datasets, the code of which has been public in \url{https://github.com/yanglixiaoshen/ProVQA.}
Removing Rain in Videos: A Large-scale Database and A Two-stream ConvLSTM Approach
Jun 06, 2019

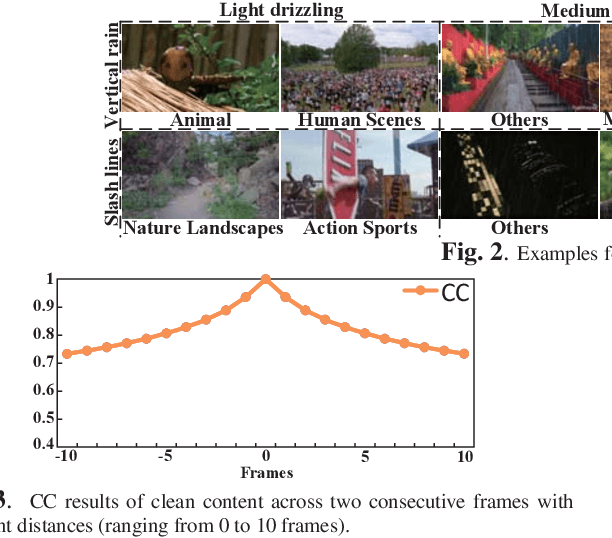
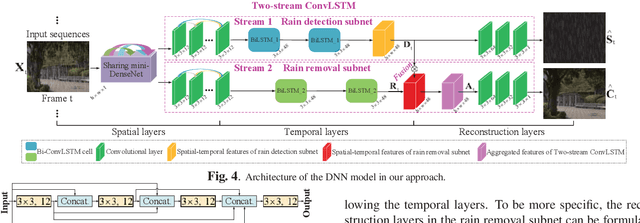
Rain removal has recently attracted increasing research attention, as it is able to enhance the visibility of rain videos. However, the existing learning based rain removal approaches for videos suffer from insufficient training data, especially when applying deep learning to remove rain. In this paper, we establish a large-scale video database for rain removal (LasVR), which consists of 316 rain videos. Then, we observe from our database that there exist the temporal correlation of clean content and similar patterns of rain across video frames. According to these two observations, we propose a two-stream convolutional long- and short- term memory (ConvLSTM) approach for rain removal in videos. The first stream is composed of the subnet for rain detection, while the second stream is the subnet of rain removal that leverages the features from the rain detection subnet. Finally, the experimental results on both synthetic and real rain videos show the proposed approach performs better than other state-of-the-art approaches.
Saliency Prediction on Omnidirectional Images with Generative Adversarial Imitation Learning
Apr 15, 2019
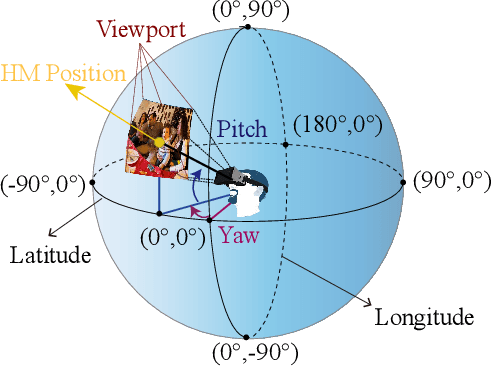


When watching omnidirectional images (ODIs), subjects can access different viewports by moving their heads. Therefore, it is necessary to predict subjects' head fixations on ODIs. Inspired by generative adversarial imitation learning (GAIL), this paper proposes a novel approach to predict saliency of head fixations on ODIs, named SalGAIL. First, we establish a dataset for attention on ODIs (AOI). In contrast to traditional datasets, our AOI dataset is large-scale, which contains the head fixations of 30 subjects viewing 600 ODIs. Next, we mine our AOI dataset and determine three findings: (1) The consistency of head fixations are consistent among subjects, and it grows alongside the increased subject number; (2) The head fixations exist with a front center bias (FCB); and (3) The magnitude of head movement is similar across subjects. According to these findings, our SalGAIL approach applies deep reinforcement learning (DRL) to predict the head fixations of one subject, in which GAIL learns the reward of DRL, rather than the traditional human-designed reward. Then, multi-stream DRL is developed to yield the head fixations of different subjects, and the saliency map of an ODI is generated via convoluting predicted head fixations. Finally, experiments validate the effectiveness of our approach in predicting saliency maps of ODIs, significantly better than 10 state-of-the-art approaches.
MFQE 2.0: A New Approach for Multi-frame Quality Enhancement on Compressed Video
Feb 26, 2019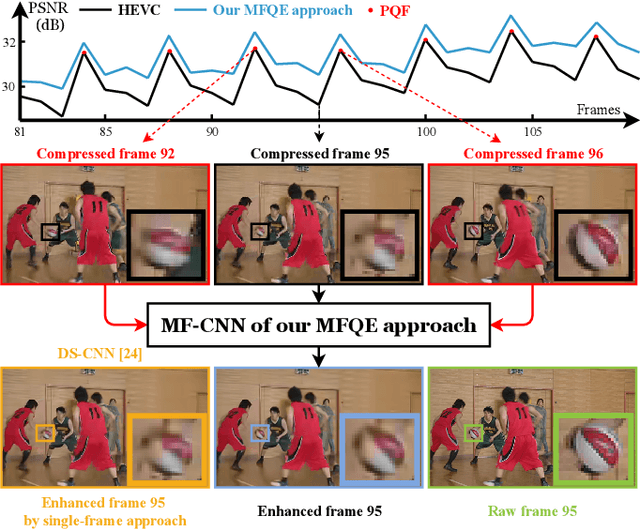

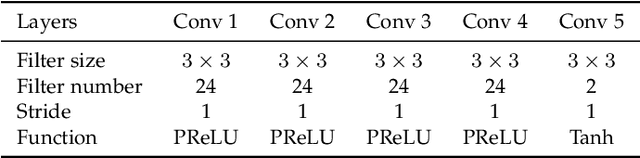
The past few years have witnessed great success in applying deep learning to enhance the quality of compressed image/video. The existing approaches mainly focus on enhancing the quality of a single frame, not considering the similarity between consecutive frames. Since heavy fluctuation exists across compressed video frames as investigated in this paper, frame similarity can be utilized for quality enhancement of low-quality frames by using their neighboring high-quality frames. This task can be seen as Multi-Frame Quality Enhancement (MFQE). Accordingly, this paper proposes an MFQE approach for compressed video, as the first attempt in this direction. In our approach, we firstly develop a Bidirectional Long Short-Term Memory (BiLSTM) based detector to locate Peak Quality Frames (PQFs) in compressed video. Then, a novel Multi-Frame Convolutional Neural Network (MF-CNN) is designed to enhance the quality of compressed video, in which the non-PQF and its nearest two PQFs are the input. In MF-CNN, motion between the non-PQF and PQFs is compensated by a motion compensation subnet. Subsequently, a quality enhancement subnet fuses the non-PQF and compensated PQFs, and then reduces the compression artifacts of the non-PQF. Finally, experiments validate the effectiveness and generalization ability of our MFQE approach in advancing the state-of-the-art quality enhancement of compressed video. The code of our MFQE approach is available at https://github.com/RyanXingQL/MFQE2.0.git.
Understanding and Predicting the Memorability of Natural Scene Images
Oct 17, 2018
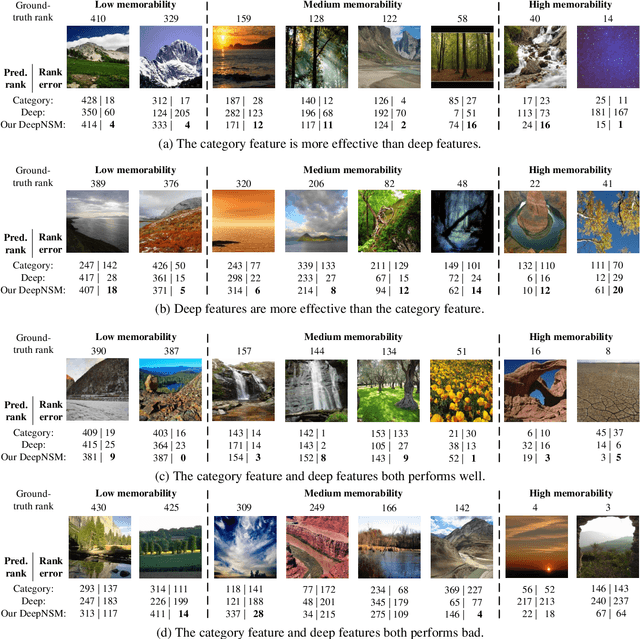

Memorability measures how easily an image is to be memorized after glancing, which may contribute to designing magazine covers, tourism publicity materials, and so forth. Recent works have shed light on the visual features that make generic images, object images or face photographs memorable. However, a clear understanding and reliable estimation of natural scene memorability remain elusive. In this paper, we provide an attempt to answer: "what exactly makes natural scene memorable". To this end, we first establish a large-scale natural scene image memorability (LNSIM) database, containing 2,632 natural scene images and their ground truth memorability scores. Then, we mine our database to investigate how low-, middle- and high-level handcrafted features affect the memorability of natural scene. In particular, we find that high-level feature of scene category is rather correlated with natural scene memorability. We also find that deep feature is effective in predicting the memorability scores. Therefore, we propose a deep neural network based natural scene memorability (DeepNSM) predictor, which takes advantage of scene category. Finally, the experimental results validate the effectiveness of our DeepNSM, exceeding the state-of-the-art methods.
Predicting Head Movement in Panoramic Video: A Deep Reinforcement Learning Approach
Sep 21, 2018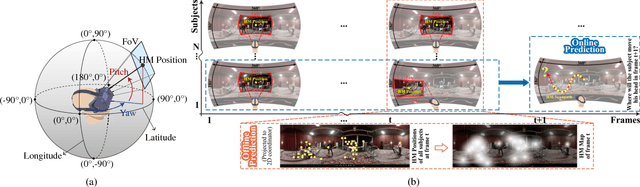

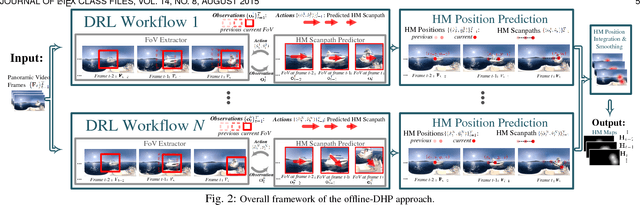
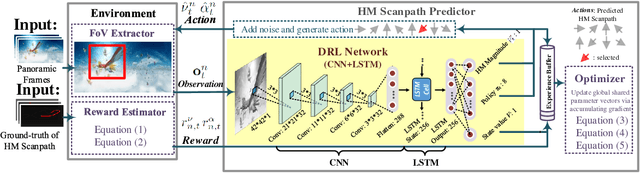
Panoramic video provides immersive and interactive experience by enabling humans to control the field of view (FoV) through head movement (HM). Thus, HM plays a key role in modeling human attention on panoramic video. This paper establishes a database collecting subjects' HM in panoramic video sequences. From this database, we find that the HM data are highly consistent across subjects. Furthermore, we find that deep reinforcement learning (DRL) can be applied to predict HM positions, via maximizing the reward of imitating human HM scanpaths through the agent's actions. Based on our findings, we propose a DRL-based HM prediction (DHP) approach with offline and online versions, called offline-DHP and online-DHP. In offline-DHP, multiple DRL workflows are run to determine potential HM positions at each panoramic frame. Then, a heat map of the potential HM positions, named the HM map, is generated as the output of offline-DHP. In online-DHP, the next HM position of one subject is estimated given the currently observed HM position, which is achieved by developing a DRL algorithm upon the learned offline-DHP model. Finally, the experiments validate that our approach is effective in both offline and online prediction of HM positions for panoramic video, and that the learned offline-DHP model can improve the performance of online-DHP.
* 15 pages, 10 figures, published on TPAMI 2018