 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHUMOTO: A 4D Dataset of Mocap Human Object Interactions
Apr 14, 2025We present Human Motions with Objects (HUMOTO), a high-fidelity dataset of human-object interactions for motion generation, computer vision, and robotics applications. Featuring 736 sequences (7,875 seconds at 30 fps), HUMOTO captures interactions with 63 precisely modeled objects and 72 articulated parts. Our innovations include a scene-driven LLM scripting pipeline creating complete, purposeful tasks with natural progression, and a mocap-and-camera recording setup to effectively handle occlusions. Spanning diverse activities from cooking to outdoor picnics, HUMOTO preserves both physical accuracy and logical task flow. Professional artists rigorously clean and verify each sequence, minimizing foot sliding and object penetrations. We also provide benchmarks compared to other datasets. HUMOTO's comprehensive full-body motion and simultaneous multi-object interactions address key data-capturing challenges and provide opportunities to advance realistic human-object interaction modeling across research domains with practical applications in animation, robotics, and embodied AI systems. Project: https://jiaxin-lu.github.io/humoto/ .
A Survey on Computational Solutions for Reconstructing Complete Objects by Reassembling Their Fractured Parts
Oct 18, 2024Reconstructing a complete object from its parts is a fundamental problem in many scientific domains. The purpose of this article is to provide a systematic survey on this topic. The reassembly problem requires understanding the attributes of individual pieces and establishing matches between different pieces. Many approaches also model priors of the underlying complete object. Existing approaches are tightly connected problems of shape segmentation, shape matching, and learning shape priors. We provide existing algorithms in this context and emphasize their similarities and differences to general-purpose approaches. We also survey the trends from early non-deep learning approaches to more recent deep learning approaches. In addition to algorithms, this survey will also describe existing datasets, open-source software packages, and applications. To the best of our knowledge, this is the first comprehensive survey on this topic in computer graphics.
Jigsaw++: Imagining Complete Shape Priors for Object Reassembly
Oct 15, 2024



The automatic assembly problem has attracted increasing interest due to its complex challenges that involve 3D representation. This paper introduces Jigsaw++, a novel generative method designed to tackle the multifaceted challenges of reconstruction for the reassembly problem. Existing approach focusing primarily on piecewise information for both part and fracture assembly, often overlooking the integration of complete object prior. Jigsaw++ distinguishes itself by learning a category-agnostic shape prior of complete objects. It employs the proposed "retargeting" strategy that effectively leverages the output of any existing assembly method to generate complete shape reconstructions. This capability allows it to function orthogonally to the current methods. Through extensive evaluations on Breaking Bad dataset and PartNet, Jigsaw++ has demonstrated its effectiveness, reducing reconstruction errors and enhancing the precision of shape reconstruction, which sets a new direction for future reassembly model developments.
UGG: Unified Generative Grasping
Nov 28, 2023Dexterous grasping aims to produce diverse grasping postures with a high grasping success rate. Regression-based methods that directly predict grasping parameters given the object may achieve a high success rate but often lack diversity. Generation-based methods that generate grasping postures conditioned on the object can often produce diverse grasping, but they are insufficient for high grasping success due to lack of discriminative information. To mitigate, we introduce a unified diffusion-based dexterous grasp generation model, dubbed the name UGG, which operates within the object point cloud and hand parameter spaces. Our all-transformer architecture unifies the information from the object, the hand, and the contacts, introducing a novel representation of contact points for improved contact modeling. The flexibility and quality of our model enable the integration of a lightweight discriminator, benefiting from simulated discriminative data, which pushes for a high success rate while preserving high diversity. Beyond grasp generation, our model can also generate objects based on hand information, offering valuable insights into object design and studying how the generative model perceives objects. Our model achieves state-of-the-art dexterous grasping on the large-scale DexGraspNet dataset while facilitating human-centric object design, marking a significant advancement in dexterous grasping research. Our project page is https://jiaxin-lu.github.io/ugg/ .
M3C: A Framework towards Convergent, Flexible, and Unsupervised Learning of Mixture Graph Matching and Clustering
Oct 27, 2023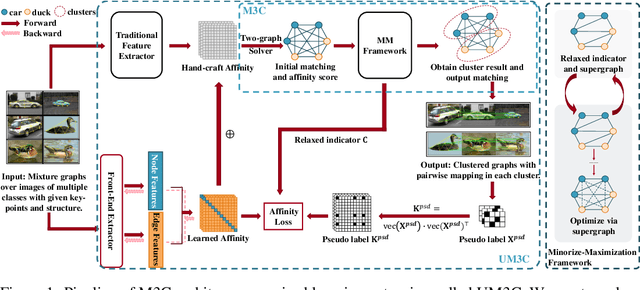
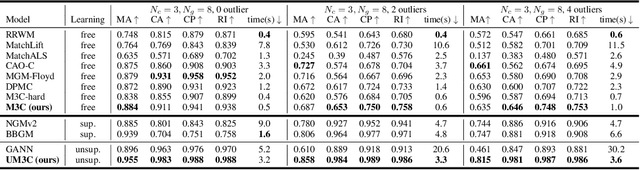
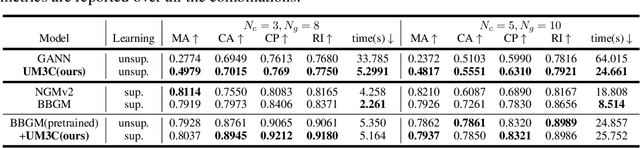
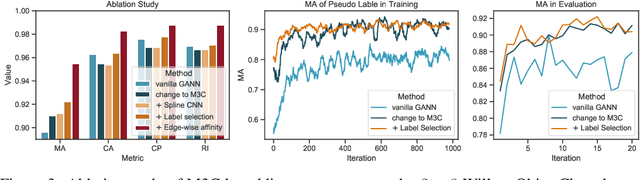
Existing graph matching methods typically assume that there are similar structures between graphs and they are matchable. However, these assumptions do not align with real-world applications. This work addresses a more realistic scenario where graphs exhibit diverse modes, requiring graph grouping before or along with matching, a task termed mixture graph matching and clustering. We introduce Minorize-Maximization Matching and Clustering (M3C), a learning-free algorithm that guarantees theoretical convergence through the Minorize-Maximization framework and offers enhanced flexibility via relaxed clustering. Building on M3C, we develop UM3C, an unsupervised model that incorporates novel edge-wise affinity learning and pseudo label selection. Extensive experimental results on public benchmarks demonstrate that our method outperforms state-of-the-art graph matching and mixture graph matching and clustering approaches in both accuracy and efficiency. Source code will be made publicly available.
Jigsaw: Learning to Assemble Multiple Fractured Objects
May 29, 2023



Automated assembly of 3D fractures is essential in orthopedics, archaeology, and our daily life. This paper presents Jigsaw, a novel framework for assembling physically broken 3D objects from multiple pieces. Our approach leverages hierarchical features of global and local geometry to match and align the fracture surfaces. Our framework consists of three components: (1) surface segmentation to separate fracture and original parts, (2) multi-parts matching to find correspondences among fracture surface points, and (3) robust global alignment to recover the global poses of the pieces. We show how to jointly learn segmentation and matching and seamlessly integrate feature matching and rigidity constraints. We evaluate Jigsaw on the Breaking Bad dataset and achieve superior performance compared to state-of-the-art methods. Our method also generalizes well to diverse fracture modes, objects, and unseen instances. To the best of our knowledge, this is the first learning-based method designed specifically for 3D fracture assembly over multiple pieces.
Learning Universe Model for Partial Matching Networks over Multiple Graphs
Oct 19, 2022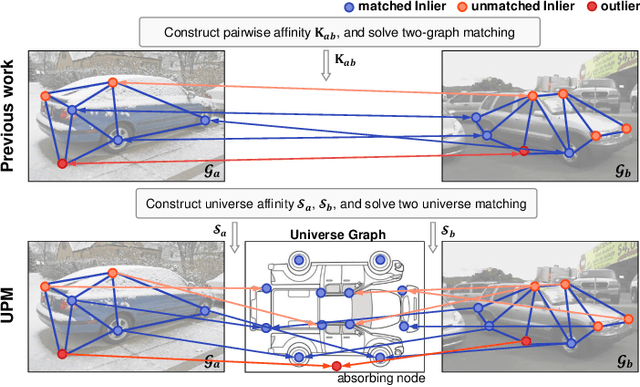



We consider the general setting for partial matching of two or multiple graphs, in the sense that not necessarily all the nodes in one graph can find their correspondences in another graph and vice versa. We take a universe matching perspective to this ubiquitous problem, whereby each node is either matched into an anchor in a virtual universe graph or regarded as an outlier. Such a universe matching scheme enjoys a few important merits, which have not been adopted in existing learning-based graph matching (GM) literature. First, the subtle logic for inlier matching and outlier detection can be clearly modeled, which is otherwise less convenient to handle in the pairwise matching scheme. Second, it enables end-to-end learning especially for universe level affinity metric learning for inliers matching, and loss design for gathering outliers together. Third, the resulting matching model can easily handle new arriving graphs under online matching, or even the graphs coming from different categories of the training set. To our best knowledge, this is the first deep learning network that can cope with two-graph matching, multiple-graph matching, online matching, and mixture graph matching simultaneously. Extensive experimental results show the state-of-the-art performance of our method in these settings.
HDI-Forest: Highest Density Interval Regression Forest
May 24, 2019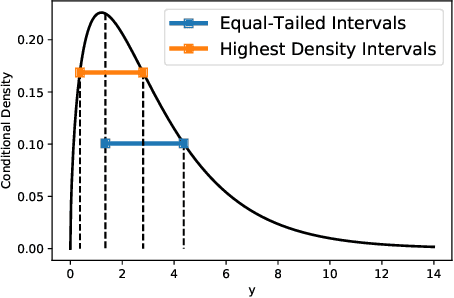

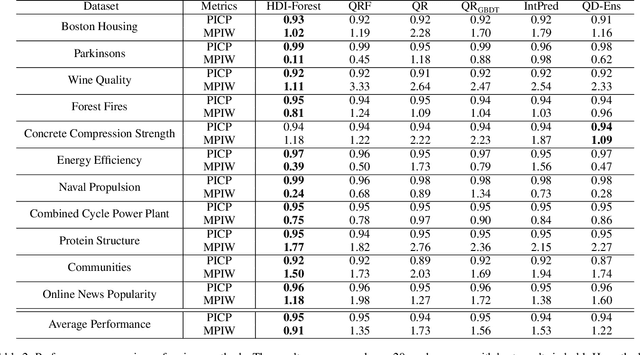
By seeking the narrowest prediction intervals (PIs) that satisfy the specified coverage probability requirements, the recently proposed quality-based PI learning principle can extract high-quality PIs that better summarize the predictive certainty in regression tasks, and has been widely applied to solve many practical problems. Currently, the state-of-the-art quality-based PI estimation methods are based on deep neural networks or linear models. In this paper, we propose Highest Density Interval Regression Forest (HDI-Forest), a novel quality-based PI estimation method that is instead based on Random Forest. HDI-Forest does not require additional model training, and directly reuses the trees learned in a standard Random Forest model. By utilizing the special properties of Random Forest, HDI-Forest could efficiently and more directly optimize the PI quality metrics. Extensive experiments on benchmark datasets show that HDI-Forest significantly outperforms previous approaches, reducing the average PI width by over 30\% while achieving the same or better coverage probability.
Understanding and Predicting the Memorability of Natural Scene Images
Oct 17, 2018
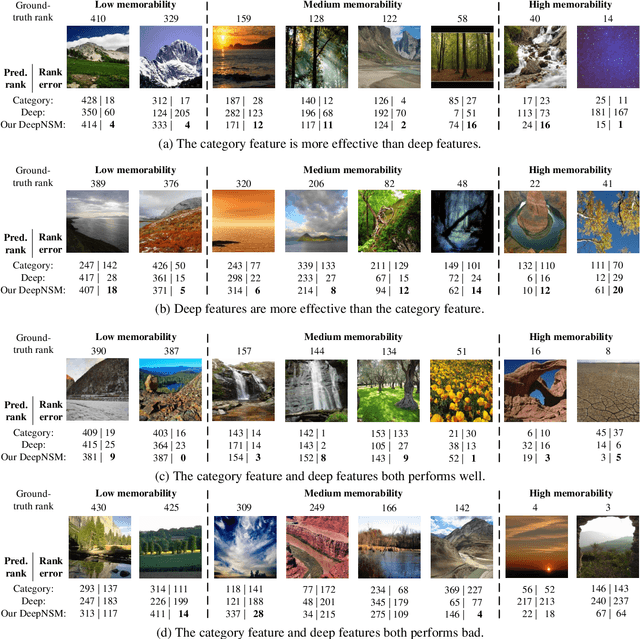

Memorability measures how easily an image is to be memorized after glancing, which may contribute to designing magazine covers, tourism publicity materials, and so forth. Recent works have shed light on the visual features that make generic images, object images or face photographs memorable. However, a clear understanding and reliable estimation of natural scene memorability remain elusive. In this paper, we provide an attempt to answer: "what exactly makes natural scene memorable". To this end, we first establish a large-scale natural scene image memorability (LNSIM) database, containing 2,632 natural scene images and their ground truth memorability scores. Then, we mine our database to investigate how low-, middle- and high-level handcrafted features affect the memorability of natural scene. In particular, we find that high-level feature of scene category is rather correlated with natural scene memorability. We also find that deep feature is effective in predicting the memorability scores. Therefore, we propose a deep neural network based natural scene memorability (DeepNSM) predictor, which takes advantage of scene category. Finally, the experimental results validate the effectiveness of our DeepNSM, exceeding the state-of-the-art methods.
What Makes Natural Scene Memorable?
Aug 27, 2018

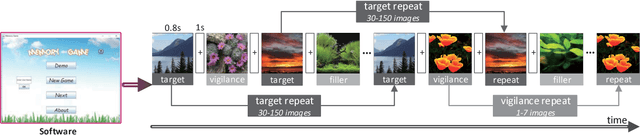

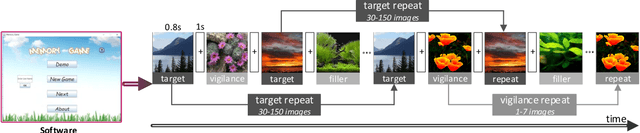
Recent studies on image memorability have shed light on the visual features that make generic images, object images or face photographs memorable. However, a clear understanding and reliable estimation of natural scene memorability remain elusive. In this paper, we provide an attempt to answer: "what exactly makes natural scene memorable". Specifically, we first build LNSIM, a large-scale natural scene image memorability database (containing 2,632 images and memorability annotations). Then, we mine our database to investigate how low-, middle- and high-level handcrafted features affect the memorability of natural scene. In particular, we find that high-level feature of scene category is rather correlated with natural scene memorability. Thus, we propose a deep neural network based natural scene memorability (DeepNSM) predictor, which takes advantage of scene category. Finally, the experimental results validate the effectiveness of DeepNSM.