 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMining Attribute Subspaces for Efficient Fine-tuning of 3D Foundation Models
Apr 11, 2026With the emergence of 3D foundation models, there is growing interest in fine-tuning them for downstream tasks, where LoRA is the dominant fine-tuning paradigm. As 3D datasets exhibit distinct variations in texture, geometry, camera motion, and lighting, there are interesting fundamental questions: 1) Are there LoRA subspaces associated with each type of variation? 2) Are these subspaces disentangled (i.e., orthogonal to each other)? 3) How do we compute them effectively? This paper provides answers to all these questions. We introduce a robust approach that generates synthetic datasets with controlled variations, fine-tunes a LoRA adapter on each dataset, and extracts a LoRA sub-space associated with each type of variation. We show that these subspaces are approximately disentangled. Integrating them leads to a reduced LoRA subspace that enables efficient LoRA fine-tuning with improved prediction accuracy for downstream tasks. In particular, we show that such a reduced LoRA subspace, despite being derived entirely from synthetic data, generalizes to real datasets. An ablation study validates the effectiveness of the choices in our approach.
Information-Regularized Constrained Inversion for Stable Avatar Editing from Sparse Supervision
Apr 03, 2026Editing animatable human avatars typically relies on sparse supervision, often a few edited keyframes, yet naively fitting a reconstructed avatar to these edits frequently causes identity leakage and pose-dependent temporal flicker. We argue that these failures are best understood as an ill-conditioned inversion: the available edited constraints do not sufficiently determine the latent directions responsible for the intended edit. We propose a conditioning-guided edited reconstruction framework that performs editing as a constrained inversion in a structured avatar latent space, restricting updates to a low-dimensional, part-specific edit subspace to prevent unintended identity changes. Crucially, we design the editing constraints during inversion by optimizing a conditioning objective derived from a local linearization of the full decoding-and-rendering pipeline, yielding an edit-subspace information matrix whose spectrum predicts stability and drives frame reweighting / keyframe activation. The resulting method operates on small subspace matrices and can be implemented efficiently (e.g., via Hessian-vector products), and improves stability under limited edited supervision.
Learning Convex Decomposition via Feature Fields
Mar 10, 2026This work proposes a new formulation to the long-standing problem of convex decomposition through learning feature fields, enabling the first feed-forward model for open-world convex decomposition. Our method produces high-quality decompositions of 3D shapes into a union of convex bodies, which are essential to accelerate collision detection in physical simulation, amongst many other applications. The key insight is to adopt a feature learning approach and learn a continuous feature field that can later be clustered to yield a good convex decomposition via our self-supervised, purely-geometric objective derived from the classical definition of convexity. Our formulation can be used for single shape optimization, but more importantly, feature prediction unlocks scalable, self-supervised learning on large datasets resulting in the first learned open-world model for convex decomposition. Experiments show that our decompositions are higher-quality than alternatives and generalize across open-world objects as well as across representations to meshes, CAD models, and even Gaussian splats. https://research.nvidia.com/labs/sil/projects/learning-convex-decomp/
ShapeGaussian: High-Fidelity 4D Human Reconstruction in Monocular Videos via Vision Priors
Feb 05, 2026We introduce ShapeGaussian, a high-fidelity, template-free method for 4D human reconstruction from casual monocular videos. Generic reconstruction methods lacking robust vision priors, such as 4DGS, struggle to capture high-deformation human motion without multi-view cues. While template-based approaches, primarily relying on SMPL, such as HUGS, can produce photorealistic results, they are highly susceptible to errors in human pose estimation, often leading to unrealistic artifacts. In contrast, ShapeGaussian effectively integrates template-free vision priors to achieve both high-fidelity and robust scene reconstructions. Our method follows a two-step pipeline: first, we learn a coarse, deformable geometry using pretrained models that estimate data-driven priors, providing a foundation for reconstruction. Then, we refine this geometry using a neural deformation model to capture fine-grained dynamic details. By leveraging 2D vision priors, we mitigate artifacts from erroneous pose estimation in template-based methods and employ multiple reference frames to resolve the invisibility issue of 2D keypoints in a template-free manner. Extensive experiments demonstrate that ShapeGaussian surpasses template-based methods in reconstruction accuracy, achieving superior visual quality and robustness across diverse human motions in casual monocular videos.
LiteGE: Lightweight Geodesic Embedding for Efficient Geodesics Computation and Non-Isometric Shape Correspondence
Dec 23, 2025Computing geodesic distances on 3D surfaces is fundamental to many tasks in 3D vision and geometry processing, with deep connections to tasks such as shape correspondence. Recent learning-based methods achieve strong performance but rely on large 3D backbones, leading to high memory usage and latency, which limit their use in interactive or resource-constrained settings. We introduce LiteGE, a lightweight approach that constructs compact, category-aware shape descriptors by applying Principal Component Analysis (PCA) to unsigned distance field (UDFs) samples at informative voxels. This descriptor is efficient to compute and removes the need for high-capacity networks. LiteGE remains robust on sparse point clouds, supporting inputs with as few as 300 points, where prior methods fail. Extensive experiments show that LiteGE reduces memory usage and inference time by up to 300$\times$ compared to existing neural approaches. In addition, by exploiting the intrinsic relationship between geodesic distance and shape correspondence, LiteGE enables fast and accurate shape matching. Our method achieves up to 1000$\times$ speedup over state-of-the-art mesh-based approaches while maintaining comparable accuracy on non-isometric shape pairs, including evaluations on point-cloud inputs.
Decoupled Generative Modeling for Human-Object Interaction Synthesis
Dec 22, 2025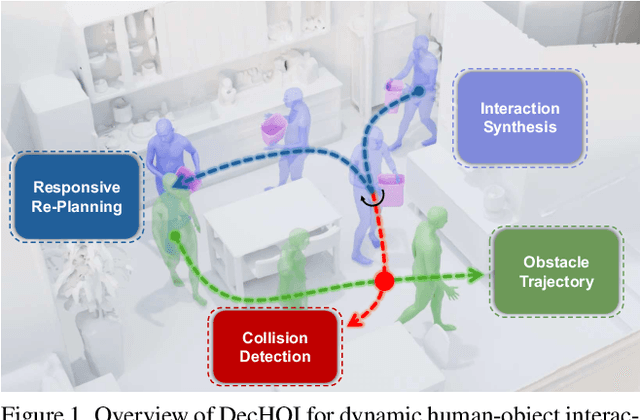
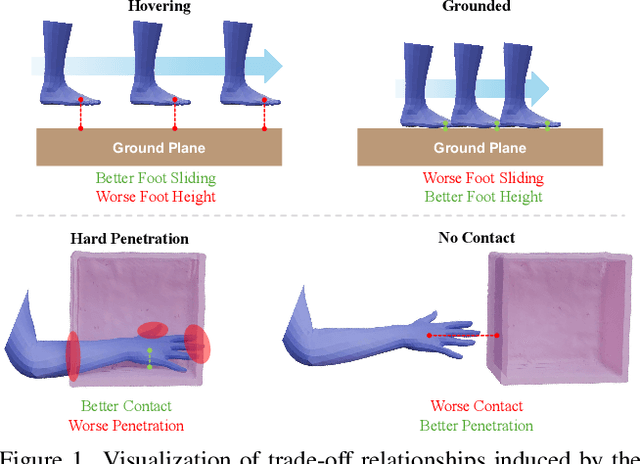
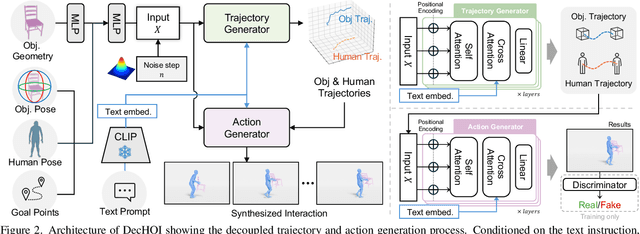
Synthesizing realistic human-object interaction (HOI) is essential for 3D computer vision and robotics, underpinning animation and embodied control. Existing approaches often require manually specified intermediate waypoints and place all optimization objectives on a single network, which increases complexity, reduces flexibility, and leads to errors such as unsynchronized human and object motion or penetration. To address these issues, we propose Decoupled Generative Modeling for Human-Object Interaction Synthesis (DecHOI), which separates path planning and action synthesis. A trajectory generator first produces human and object trajectories without prescribed waypoints, and an action generator conditions on these paths to synthesize detailed motions. To further improve contact realism, we employ adversarial training with a discriminator that focuses on the dynamics of distal joints. The framework also models a moving counterpart and supports responsive, long-sequence planning in dynamic scenes, while preserving plan consistency. Across two benchmarks, FullBodyManipulation and 3D-FUTURE, DecHOI surpasses prior methods on most quantitative metrics and qualitative evaluations, and perceptual studies likewise prefer our results.
WorldReel: 4D Video Generation with Consistent Geometry and Motion Modeling
Dec 08, 2025Recent video generators achieve striking photorealism, yet remain fundamentally inconsistent in 3D. We present WorldReel, a 4D video generator that is natively spatio-temporally consistent. WorldReel jointly produces RGB frames together with 4D scene representations, including pointmaps, camera trajectory, and dense flow mapping, enabling coherent geometry and appearance modeling over time. Our explicit 4D representation enforces a single underlying scene that persists across viewpoints and dynamic content, yielding videos that remain consistent even under large non-rigid motion and significant camera movement. We train WorldReel by carefully combining synthetic and real data: synthetic data providing precise 4D supervision (geometry, motion, and camera), while real videos contribute visual diversity and realism. This blend allows WorldReel to generalize to in-the-wild footage while preserving strong geometric fidelity. Extensive experiments demonstrate that WorldReel sets a new state-of-the-art for consistent video generation with dynamic scenes and moving cameras, improving metrics of geometric consistency, motion coherence, and reducing view-time artifacts over competing methods. We believe that WorldReel brings video generation closer to 4D-consistent world modeling, where agents can render, interact, and reason about scenes through a single and stable spatiotemporal representation.
Positional Encoding Field
Oct 23, 2025Diffusion Transformers (DiTs) have emerged as the dominant architecture for visual generation, powering state-of-the-art image and video models. By representing images as patch tokens with positional encodings (PEs), DiTs combine Transformer scalability with spatial and temporal inductive biases. In this work, we revisit how DiTs organize visual content and discover that patch tokens exhibit a surprising degree of independence: even when PEs are perturbed, DiTs still produce globally coherent outputs, indicating that spatial coherence is primarily governed by PEs. Motivated by this finding, we introduce the Positional Encoding Field (PE-Field), which extends positional encodings from the 2D plane to a structured 3D field. PE-Field incorporates depth-aware encodings for volumetric reasoning and hierarchical encodings for fine-grained sub-patch control, enabling DiTs to model geometry directly in 3D space. Our PE-Field-augmented DiT achieves state-of-the-art performance on single-image novel view synthesis and generalizes to controllable spatial image editing.
SounDiT: Geo-Contextual Soundscape-to-Landscape Generation
May 19, 2025


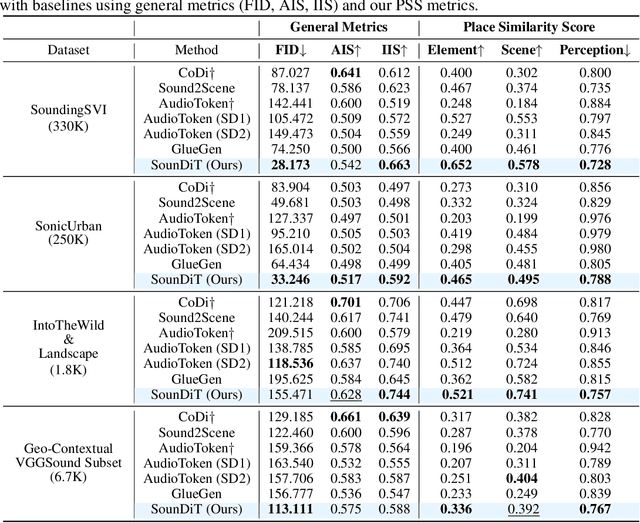
We present a novel and practically significant problem-Geo-Contextual Soundscape-to-Landscape (GeoS2L) generation-which aims to synthesize geographically realistic landscape images from environmental soundscapes. Prior audio-to-image generation methods typically rely on general-purpose datasets and overlook geographic and environmental contexts, resulting in unrealistic images that are misaligned with real-world environmental settings. To address this limitation, we introduce a novel geo-contextual computational framework that explicitly integrates geographic knowledge into multimodal generative modeling. We construct two large-scale geo-contextual multimodal datasets, SoundingSVI and SonicUrban, pairing diverse soundscapes with real-world landscape images. We propose SounDiT, a novel Diffusion Transformer (DiT)-based model that incorporates geo-contextual scene conditioning to synthesize geographically coherent landscape images. Furthermore, we propose a practically-informed geo-contextual evaluation framework, the Place Similarity Score (PSS), across element-, scene-, and human perception-levels to measure consistency between input soundscapes and generated landscape images. Extensive experiments demonstrate that SounDiT outperforms existing baselines in both visual fidelity and geographic settings. Our work not only establishes foundational benchmarks for GeoS2L generation but also highlights the importance of incorporating geographic domain knowledge in advancing multimodal generative models, opening new directions at the intersection of generative AI, geography, urban planning, and environmental sciences.
RayZer: A Self-supervised Large View Synthesis Model
May 01, 2025



We present RayZer, a self-supervised multi-view 3D Vision model trained without any 3D supervision, i.e., camera poses and scene geometry, while exhibiting emerging 3D awareness. Concretely, RayZer takes unposed and uncalibrated images as input, recovers camera parameters, reconstructs a scene representation, and synthesizes novel views. During training, RayZer relies solely on its self-predicted camera poses to render target views, eliminating the need for any ground-truth camera annotations and allowing RayZer to be trained with 2D image supervision. The emerging 3D awareness of RayZer is attributed to two key factors. First, we design a self-supervised framework, which achieves 3D-aware auto-encoding of input images by disentangling camera and scene representations. Second, we design a transformer-based model in which the only 3D prior is the ray structure, connecting camera, pixel, and scene simultaneously. RayZer demonstrates comparable or even superior novel view synthesis performance than ``oracle'' methods that rely on pose annotations in both training and testing. Project: https://hwjiang1510.github.io/RayZer/