 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSDD-YOLO: A Small-Target Detection Framework for Ground-to-Air Anti-UAV Surveillance with Edge-Efficient Deployment
Mar 26, 2026Detecting small unmanned aerial vehicles (UAVs) from a ground-to-air (G2A) perspective presents significant challenges, including extremely low pixel occupancy, cluttered aerial backgrounds, and strict real-time constraints. Existing YOLO-based detectors are primarily optimized for general object detection and often lack adequate feature resolution for sub-pixel targets, while introducing complexities during deployment. In this paper, we propose SDD-YOLO, a small-target detection framework tailored for G2A anti-UAV surveillance. To capture fine-grained spatial details critical for micro-targets, SDD-YOLO introduces a P2 high-resolution detection head operating at 4 times downsampling. Furthermore, we integrate the recent architectural advancements from YOLO26, including a DFL-free, NMS-free architecture for streamlined inference, and the MuSGD hybrid training strategy with ProgLoss and STAL, which substantially mitigates gradient oscillation on sparse small-target signals. To support our evaluation, we construct DroneSOD-30K, a large-scale G2A dataset comprising approximately 30,000 annotated images covering diverse meteorological conditions. Experiments demonstrate that SDD-YOLO-n achieves a mAP@0.5 of 86.0% on DroneSOD-30K, surpassing the YOLOv5n baseline by 7.8 percentage points. Extensive inference analysis shows our model attains 226 FPS on an NVIDIA RTX 5090 and 35 FPS on an Intel Xeon CPU, demonstrating exceptional efficiency for future edge deployment.
SAMAS: A Spectrum-Guided Multi-Agent System for Achieving Style Fidelity in Literary Translation
Feb 23, 2026Modern large language models (LLMs) excel at generating fluent and faithful translations. However, they struggle to preserve an author's unique literary style, often producing semantically correct but generic outputs. This limitation stems from the inability of current single-model and static multi-agent systems to perceive and adapt to stylistic variations. To address this, we introduce the Style-Adaptive Multi-Agent System (SAMAS), a novel framework that treats style preservation as a signal processing task. Specifically, our method quantifies literary style into a Stylistic Feature Spectrum (SFS) using the wavelet packet transform. This SFS serves as a control signal to dynamically assemble a tailored workflow of specialized translation agents based on the source text's structural patterns. Extensive experiments on translation benchmarks show that SAMAS achieves competitive semantic accuracy against strong baselines, primarily by leveraging its statistically significant advantage in style fidelity.
ExoGS: A 4D Real-to-Sim-to-Real Framework for Scalable Manipulation Data Collection
Jan 26, 2026Real-to-Sim-to-Real technique is gaining increasing interest for robotic manipulation, as it can generate scalable data in simulation while having narrower sim-to-real gap. However, previous methods mainly focused on environment-level visual real-to-sim transfer, ignoring the transfer of interactions, which could be challenging and inefficient to obtain purely in simulation especially for contact-rich tasks. We propose ExoGS, a robot-free 4D Real-to-Sim-to-Real framework that captures both static environments and dynamic interactions in the real world and transfers them seamlessly to a simulated environment. It provides a new solution for scalable manipulation data collection and policy learning. ExoGS employs a self-designed robot-isomorphic passive exoskeleton AirExo-3 to capture kinematically consistent trajectories with millimeter-level accuracy and synchronized RGB observations during direct human demonstrations. The robot, objects, and environment are reconstructed as editable 3D Gaussian Splatting assets, enabling geometry-consistent replay and large-scale data augmentation. Additionally, a lightweight Mask Adapter injects instance-level semantics into the policy to enhance robustness under visual domain shifts. Real-world experiments demonstrate that ExoGS significantly improves data efficiency and policy generalization compared to teleoperation-based baselines. Code and hardware files have been released on https://github.com/zaixiabalala/ExoGS.
Foundation Model for Skeleton-Based Human Action Understanding
Aug 18, 2025Human action understanding serves as a foundational pillar in the field of intelligent motion perception. Skeletons serve as a modality- and device-agnostic representation for human modeling, and skeleton-based action understanding has potential applications in humanoid robot control and interaction. \RED{However, existing works often lack the scalability and generalization required to handle diverse action understanding tasks. There is no skeleton foundation model that can be adapted to a wide range of action understanding tasks}. This paper presents a Unified Skeleton-based Dense Representation Learning (USDRL) framework, which serves as a foundational model for skeleton-based human action understanding. USDRL consists of a Transformer-based Dense Spatio-Temporal Encoder (DSTE), Multi-Grained Feature Decorrelation (MG-FD), and Multi-Perspective Consistency Training (MPCT). The DSTE module adopts two parallel streams to learn temporal dynamic and spatial structure features. The MG-FD module collaboratively performs feature decorrelation across temporal, spatial, and instance domains to reduce dimensional redundancy and enhance information extraction. The MPCT module employs both multi-view and multi-modal self-supervised consistency training. The former enhances the learning of high-level semantics and mitigates the impact of low-level discrepancies, while the latter effectively facilitates the learning of informative multimodal features. We perform extensive experiments on 25 benchmarks across across 9 skeleton-based action understanding tasks, covering coarse prediction, dense prediction, and transferred prediction. Our approach significantly outperforms the current state-of-the-art methods. We hope that this work would broaden the scope of research in skeleton-based action understanding and encourage more attention to dense prediction tasks.
Iterative pseudo-labeling based adaptive copy-paste supervision for semi-supervised tumor segmentation
Aug 06, 2025Semi-supervised learning (SSL) has attracted considerable attention in medical image processing. The latest SSL methods use a combination of consistency regularization and pseudo-labeling to achieve remarkable success. However, most existing SSL studies focus on segmenting large organs, neglecting the challenging scenarios where there are numerous tumors or tumors of small volume. Furthermore, the extensive capabilities of data augmentation strategies, particularly in the context of both labeled and unlabeled data, have yet to be thoroughly investigated. To tackle these challenges, we introduce a straightforward yet effective approach, termed iterative pseudo-labeling based adaptive copy-paste supervision (IPA-CP), for tumor segmentation in CT scans. IPA-CP incorporates a two-way uncertainty based adaptive augmentation mechanism, aiming to inject tumor uncertainties present in the mean teacher architecture into adaptive augmentation. Additionally, IPA-CP employs an iterative pseudo-label transition strategy to generate more robust and informative pseudo labels for the unlabeled samples. Extensive experiments on both in-house and public datasets show that our framework outperforms state-of-the-art SSL methods in medical image segmentation. Ablation study results demonstrate the effectiveness of our technical contributions.
SounDiT: Geo-Contextual Soundscape-to-Landscape Generation
May 19, 2025


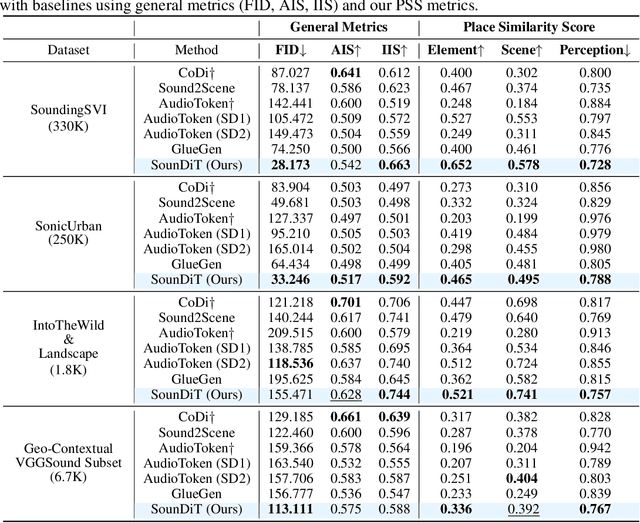
We present a novel and practically significant problem-Geo-Contextual Soundscape-to-Landscape (GeoS2L) generation-which aims to synthesize geographically realistic landscape images from environmental soundscapes. Prior audio-to-image generation methods typically rely on general-purpose datasets and overlook geographic and environmental contexts, resulting in unrealistic images that are misaligned with real-world environmental settings. To address this limitation, we introduce a novel geo-contextual computational framework that explicitly integrates geographic knowledge into multimodal generative modeling. We construct two large-scale geo-contextual multimodal datasets, SoundingSVI and SonicUrban, pairing diverse soundscapes with real-world landscape images. We propose SounDiT, a novel Diffusion Transformer (DiT)-based model that incorporates geo-contextual scene conditioning to synthesize geographically coherent landscape images. Furthermore, we propose a practically-informed geo-contextual evaluation framework, the Place Similarity Score (PSS), across element-, scene-, and human perception-levels to measure consistency between input soundscapes and generated landscape images. Extensive experiments demonstrate that SounDiT outperforms existing baselines in both visual fidelity and geographic settings. Our work not only establishes foundational benchmarks for GeoS2L generation but also highlights the importance of incorporating geographic domain knowledge in advancing multimodal generative models, opening new directions at the intersection of generative AI, geography, urban planning, and environmental sciences.
ForceMimic: Force-Centric Imitation Learning with Force-Motion Capture System for Contact-Rich Manipulation
Oct 11, 2024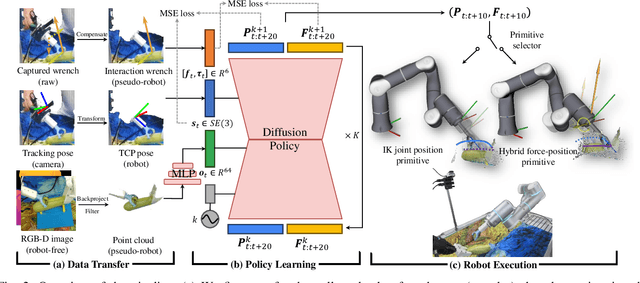
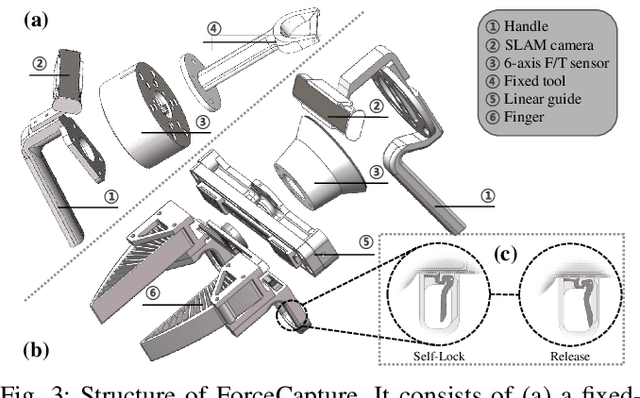
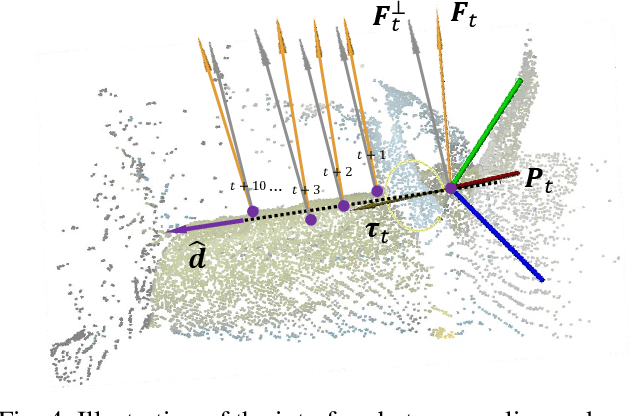
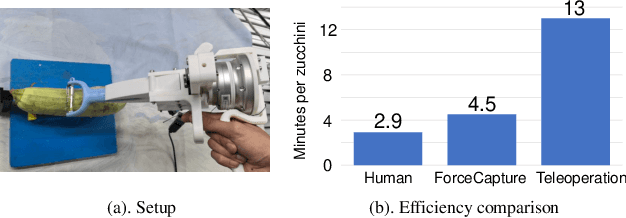
In most contact-rich manipulation tasks, humans apply time-varying forces to the target object, compensating for inaccuracies in the vision-guided hand trajectory. However, current robot learning algorithms primarily focus on trajectory-based policy, with limited attention given to learning force-related skills. To address this limitation, we introduce ForceMimic, a force-centric robot learning system, providing a natural, force-aware and robot-free robotic demonstration collection system, along with a hybrid force-motion imitation learning algorithm for robust contact-rich manipulation. Using the proposed ForceCapture system, an operator can peel a zucchini in 5 minutes, while force-feedback teleoperation takes over 13 minutes and struggles with task completion. With the collected data, we propose HybridIL to train a force-centric imitation learning model, equipped with hybrid force-position control primitive to fit the predicted wrench-position parameters during robot execution. Experiments demonstrate that our approach enables the model to learn a more robust policy under the contact-rich task of vegetable peeling, increasing the success rates by 54.5% relatively compared to state-of-the-art pure-vision-based imitation learning. Hardware, code, data and more results would be open-sourced on the project website at https://forcemimic.github.io.
Force-Centric Imitation Learning with Force-Motion Capture System for Contact-Rich Manipulation
Oct 10, 2024In most contact-rich manipulation tasks, humans apply time-varying forces to the target object, compensating for inaccuracies in the vision-guided hand trajectory. However, current robot learning algorithms primarily focus on trajectory-based policy, with limited attention given to learning force-related skills. To address this limitation, we introduce ForceMimic, a force-centric robot learning system, providing a natural, force-aware and robot-free robotic demonstration collection system, along with a hybrid force-motion imitation learning algorithm for robust contact-rich manipulation. Using the proposed ForceCapture system, an operator can peel a zucchini in 5 minutes, while force-feedback teleoperation takes over 13 minutes and struggles with task completion. With the collected data, we propose HybridIL to train a force-centric imitation learning model, equipped with hybrid force-position control primitive to fit the predicted wrench-position parameters during robot execution. Experiments demonstrate that our approach enables the model to learn a more robust policy under the contact-rich task of vegetable peeling, increasing the success rates by 54.5% relatively compared to state-of-the-art pure-vision-based imitation learning. Hardware, code, data and more results would be open-sourced on the project website at https://forcemimic.github.io.
UniAff: A Unified Representation of Affordances for Tool Usage and Articulation with Vision-Language Models
Sep 30, 2024



Previous studies on robotic manipulation are based on a limited understanding of the underlying 3D motion constraints and affordances. To address these challenges, we propose a comprehensive paradigm, termed UniAff, that integrates 3D object-centric manipulation and task understanding in a unified formulation. Specifically, we constructed a dataset labeled with manipulation-related key attributes, comprising 900 articulated objects from 19 categories and 600 tools from 12 categories. Furthermore, we leverage MLLMs to infer object-centric representations for manipulation tasks, including affordance recognition and reasoning about 3D motion constraints. Comprehensive experiments in both simulation and real-world settings indicate that UniAff significantly improves the generalization of robotic manipulation for tools and articulated objects. We hope that UniAff will serve as a general baseline for unified robotic manipulation tasks in the future. Images, videos, dataset, and code are published on the project website at:https://sites.google.com/view/uni-aff/home
Efficient Model Compression for Hierarchical Federated Learning
May 27, 2024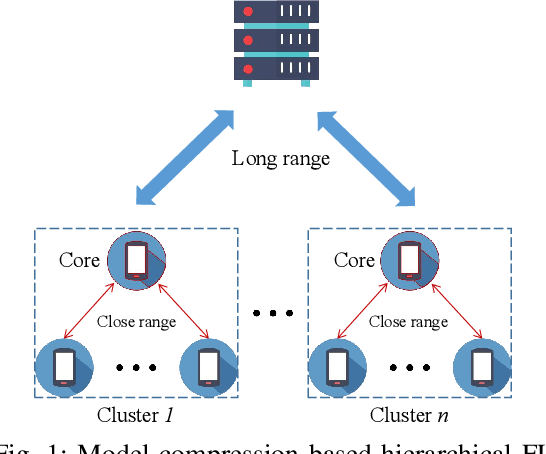
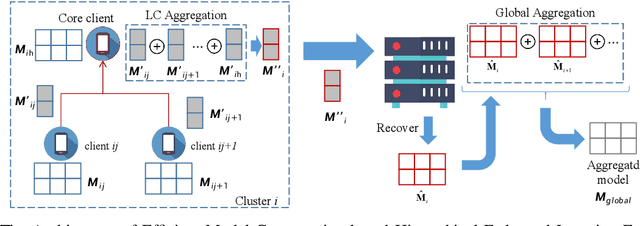
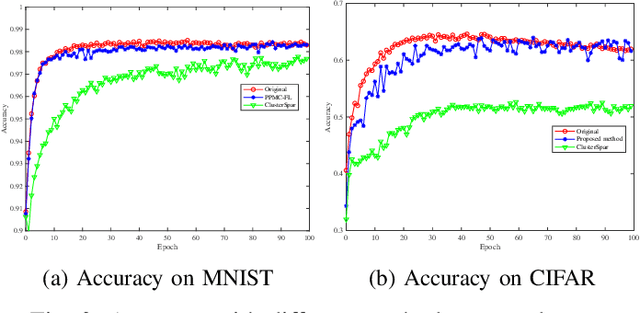
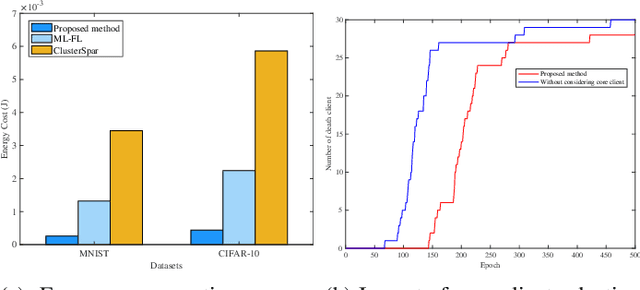
Federated learning (FL), as an emerging collaborative learning paradigm, has garnered significant attention due to its capacity to preserve privacy within distributed learning systems. In these systems, clients collaboratively train a unified neural network model using their local datasets and share model parameters rather than raw data, enhancing privacy. Predominantly, FL systems are designed for mobile and edge computing environments where training typically occurs over wireless networks. Consequently, as model sizes increase, the conventional FL frameworks increasingly consume substantial communication resources. To address this challenge and improve communication efficiency, this paper introduces a novel hierarchical FL framework that integrates the benefits of clustered FL and model compression. We present an adaptive clustering algorithm that identifies a core client and dynamically organizes clients into clusters. Furthermore, to enhance transmission efficiency, each core client implements a local aggregation with compression (LC aggregation) algorithm after collecting compressed models from other clients within the same cluster. Simulation results affirm that our proposed algorithms not only maintain comparable predictive accuracy but also significantly reduce energy consumption relative to existing FL mechanisms.