 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSounDiT: Geo-Contextual Soundscape-to-Landscape Generation
May 19, 2025We present a novel and practically significant problem-Geo-Contextual Soundscape-to-Landscape (GeoS2L) generation-which aims to synthesize geographically realistic landscape images from environmental soundscapes. Prior audio-to-image generation methods typically rely on general-purpose datasets and overlook geographic and environmental contexts, resulting in unrealistic images that are misaligned with real-world environmental settings. To address this limitation, we introduce a novel geo-contextual computational framework that explicitly integrates geographic knowledge into multimodal generative modeling. We construct two large-scale geo-contextual multimodal datasets, SoundingSVI and SonicUrban, pairing diverse soundscapes with real-world landscape images. We propose SounDiT, a novel Diffusion Transformer (DiT)-based model that incorporates geo-contextual scene conditioning to synthesize geographically coherent landscape images. Furthermore, we propose a practically-informed geo-contextual evaluation framework, the Place Similarity Score (PSS), across element-, scene-, and human perception-levels to measure consistency between input soundscapes and generated landscape images. Extensive experiments demonstrate that SounDiT outperforms existing baselines in both visual fidelity and geographic settings. Our work not only establishes foundational benchmarks for GeoS2L generation but also highlights the importance of incorporating geographic domain knowledge in advancing multimodal generative models, opening new directions at the intersection of generative AI, geography, urban planning, and environmental sciences.
Intelligent Bear Prevention System Based on Computer Vision: An Approach to Reduce Human-Bear Conflicts in the Tibetan Plateau Area, China
Mar 29, 2025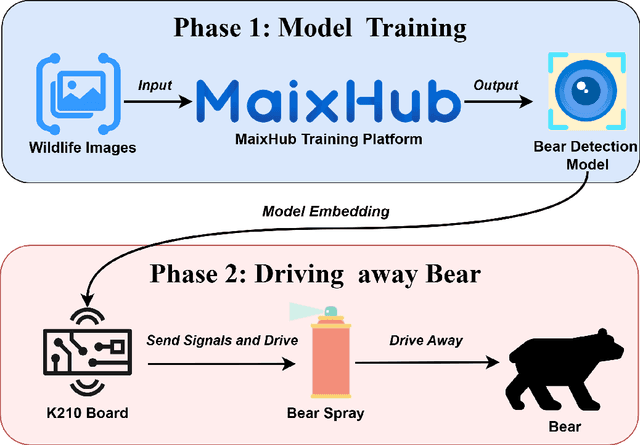
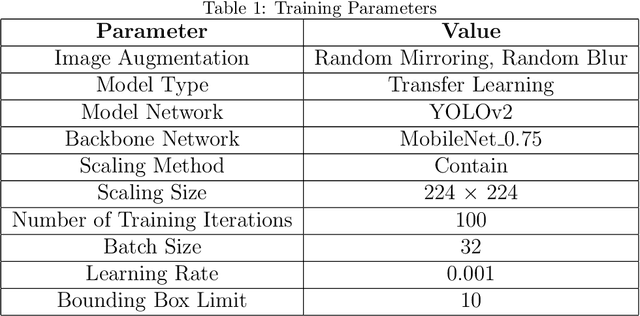
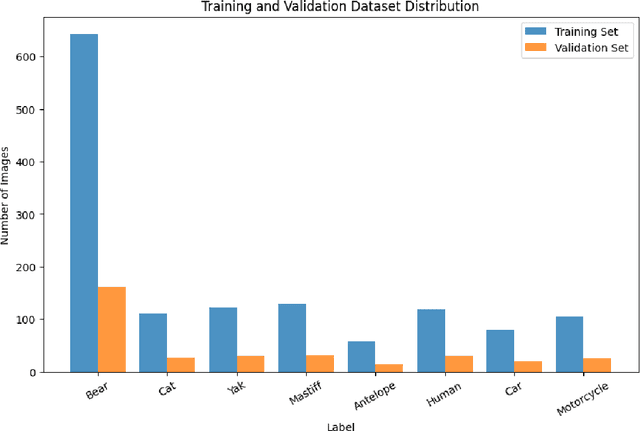

Conflicts between humans and bears on the Tibetan Plateau present substantial threats to local communities and hinder wildlife preservation initiatives. This research introduces a novel strategy that incorporates computer vision alongside Internet of Things (IoT) technologies to alleviate these issues. Tailored specifically for the harsh environment of the Tibetan Plateau, the approach utilizes the K210 development board paired with the YOLO object detection framework along with a tailored bear-deterrent mechanism, offering minimal energy usage and real-time efficiency in bear identification and deterrence. The model's performance was evaluated experimentally, achieving a mean Average Precision (mAP) of 91.4%, demonstrating excellent precision and dependability. By integrating energy-efficient components, the proposed system effectively surpasses the challenges of remote and off-grid environments, ensuring uninterrupted operation in secluded locations. This study provides a viable, eco-friendly, and expandable solution to mitigate human-bear conflicts, thereby improving human safety and promoting bear conservation in isolated areas like Yushu, China.
GRU-PFG: Extract Inter-Stock Correlation from Stock Factors with Graph Neural Network
Nov 28, 2024



The complexity of stocks and industries presents challenges for stock prediction. Currently, stock prediction models can be divided into two categories. One category, represented by GRU and ALSTM, relies solely on stock factors for prediction, with limited effectiveness. The other category, represented by HIST and TRA, incorporates not only stock factors but also industry information, industry financial reports, public sentiment, and other inputs for prediction. The second category of models can capture correlations between stocks by introducing additional information, but the extra data is difficult to standardize and generalize. Considering the current state and limitations of these two types of models, this paper proposes the GRU-PFG (Project Factors into Graph) model. This model only takes stock factors as input and extracts inter-stock correlations using graph neural networks. It achieves prediction results that not only outperform the others models relies solely on stock factors, but also achieve comparable performance to the second category models. The experimental results show that on the CSI300 dataset, the IC of GRU-PFG is 0.134, outperforming HIST's 0.131 and significantly surpassing GRU and Transformer, achieving results better than the second category models. Moreover as a model that relies solely on stock factors, it has greater potential for generalization.
STICC: A multivariate spatial clustering method for repeated geographic pattern discovery with consideration of spatial contiguity
Mar 31, 2022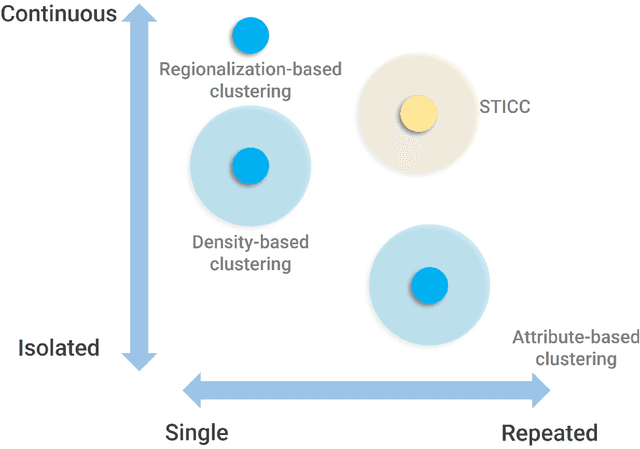

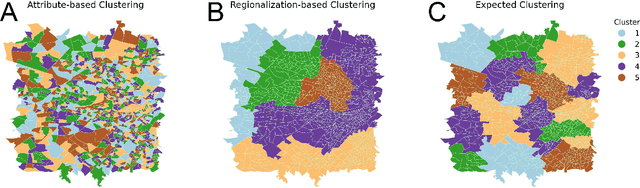

Spatial clustering has been widely used for spatial data mining and knowledge discovery. An ideal multivariate spatial clustering should consider both spatial contiguity and aspatial attributes. Existing spatial clustering approaches may face challenges for discovering repeated geographic patterns with spatial contiguity maintained. In this paper, we propose a Spatial Toeplitz Inverse Covariance-Based Clustering (STICC) method that considers both attributes and spatial relationships of geographic objects for multivariate spatial clustering. A subregion is created for each geographic object serving as the basic unit when performing clustering. A Markov random field is then constructed to characterize the attribute dependencies of subregions. Using a spatial consistency strategy, nearby objects are encouraged to belong to the same cluster. To test the performance of the proposed STICC algorithm, we apply it in two use cases. The comparison results with several baseline methods show that the STICC outperforms others significantly in terms of adjusted rand index and macro-F1 score. Join count statistics is also calculated and shows that the spatial contiguity is well preserved by STICC. Such a spatial clustering method may benefit various applications in the fields of geography, remote sensing, transportation, and urban planning, etc.
Extracting human emotions at different places based on facial expressions and spatial clustering analysis
May 06, 2019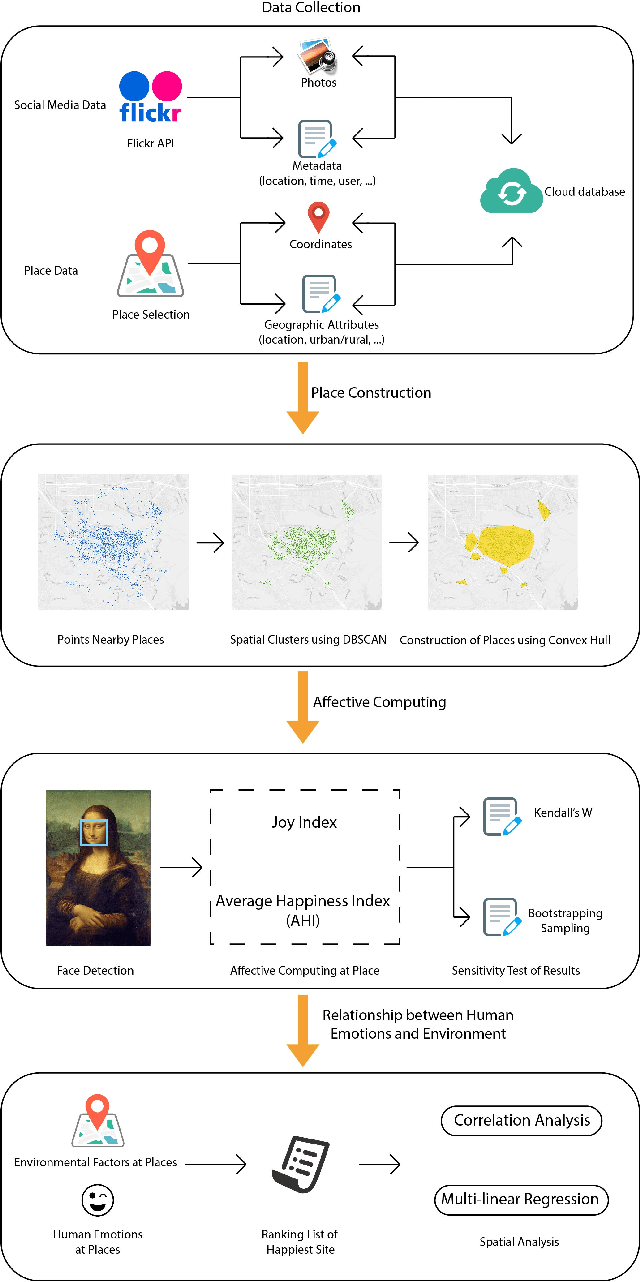
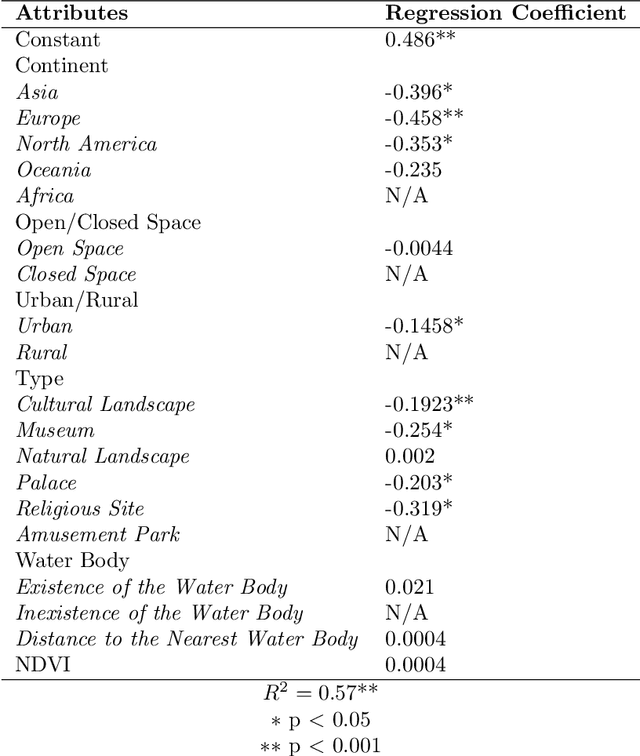
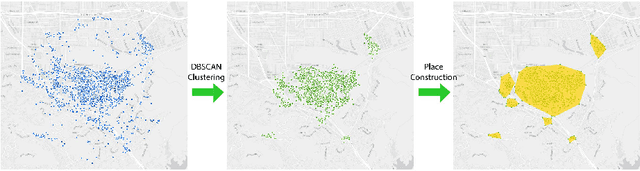
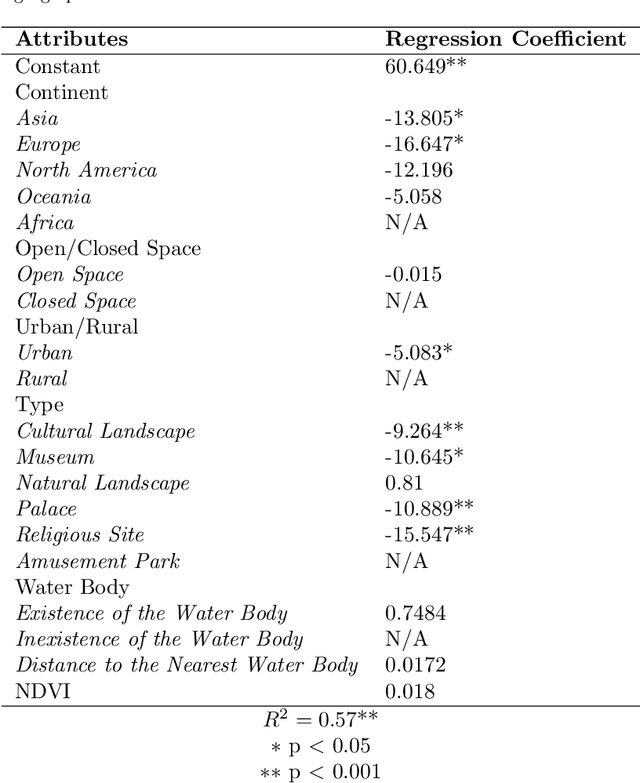
The emergence of big data enables us to evaluate the various human emotions at places from a statistic perspective by applying affective computing. In this study, a novel framework for extracting human emotions from large-scale georeferenced photos at different places is proposed. After the construction of places based on spatial clustering of user generated footprints collected in social media websites, online cognitive services are utilized to extract human emotions from facial expressions using the state-of-the-art computer vision techniques. And two happiness metrics are defined for measuring the human emotions at different places. To validate the feasibility of the framework, we take 80 tourist attractions around the world as an example and a happiness ranking list of places is generated based on human emotions calculated over 2 million faces detected out from over 6 million photos. Different kinds of geographical contexts are taken into consideration to find out the relationship between human emotions and environmental factors. Results show that much of the emotional variation at different places can be explained by a few factors such as openness. The research may offer insights on integrating human emotions to enrich the understanding of sense of place in geography and in place-based GIS.
* 40 pages; 9 figures