 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeography According to ChatGPT -- How Generative AI Represents and Reasons about Geography
Mar 19, 2026Understanding how AI will represent and reason about geography should be a key concern for all of us, as the broader public increasingly interacts with spaces and places through these systems. Similarly, in line with the nature of foundation models, our own research often relies on pre-trained models. Hence, understanding what world AI systems construct is as important as evaluating their accuracy, including factual recall. To motivate the need for such studies, we provide three illustrative vignettes, i.e., exploratory probes, in the hope that they will spark lively discussions and follow-up work: (1) Do models form strong defaults, and how brittle are model outputs to minute syntactic variations? (2) Can distributional shifts resurface from the composition of individually benign tasks, e.g., when using AI systems to create personas? (3) Do we overlook deeper questions of understanding when solely focusing on the ability of systems to recall facts such as geographic principles?
Intellicise Wireless Networks Meet Agentic AI: A Security and Privacy Perspective
Feb 17, 2026Intellicise (Intelligent and Concise) wireless network is the main direction of the evolution of future mobile communication systems, a perspective now widely acknowledged across academia and industry. As a key technology within it, Agentic AI has garnered growing attention due to its advanced cognitive capabilities, enabled through continuous perception-memory-reasoning-action cycles. This paper first analyses the unique advantages that Agentic AI introduces to intellicise wireless networks. We then propose a structured taxonomy for Agentic AI-enhanced secure intellicise wireless networks. Building on this framework, we identify emerging security and privacy challenges introduced by Agentic AI and summarize targeted strategies to address these vulnerabilities. A case study further demonstrates Agentic AI's efficacy in defending against intelligent eavesdropping attacks. Finally, we outline key open research directions to guide future exploration in this field.
S-MDMA: Sensitivity-Aware Model Division Multiple Access for Satellite-Ground Semantic Communication
Jan 25, 2026Satellite-ground semantic communication (SemCom) is expected to play a pivotal role in convergence of communication and AI (ComAI), particularly in enabling intelligent and efficient multi-user data transmission. However, the inherent bandwidth constraints and user interference in satellite-ground systems pose significant challenges to semantic fidelity and transmission robustness. To address these issues, we propose a sensitivity-aware model division multiple access (S-MDMA) framework tailored for bandwidth-limited multi-user scenarios. The proposed framework first performs semantic extraction and merging based on the MDMA architecture to consolidate redundant information. To further improve transmission efficiency, a semantic sensitivity sorting algorithm is presented, which can selectively retain key semantic features. In addition, to mitigate inter-user interference, the framework incorporates orthogonal embedding of semantic features and introduces a multi-user reconstruction loss function to guide joint optimization. Experimental results on open-source datasets demonstrate that S-MDMA consistently outperforms existing methods, achieving robust and high-fidelity reconstruction across diverse signal-to-noise ratio (SNR) conditions and user configurations.
Secure Intellicise Wireless Network: Agentic AI for Coverless Semantic Steganography Communication
Jan 23, 2026Semantic Communication (SemCom), leveraging its significant advantages in transmission efficiency and reliability, has emerged as a core technology for constructing future intellicise (intelligent and concise) wireless networks. However, intelligent attacks represented by semantic eavesdropping pose severe challenges to the security of SemCom. To address this challenge, Semantic Steganographic Communication (SemSteCom) achieves ``invisible'' encryption by implicitly embedding private semantic information into cover modality carriers. The state-of-the-art study has further introduced generative diffusion models to directly generate stega images without relying on original cover images, effectively enhancing steganographic capacity. Nevertheless, the recovery process of private images is highly dependent on the guidance of private semantic keys, which may be inferred by intelligent eavesdroppers, thereby introducing new security threats. To address this issue, we propose an Agentic AI-driven SemSteCom (AgentSemSteCom) scheme, which includes semantic extraction, digital token controlled reference image generation, coverless steganography, semantic codec, and optional task-oriented enhancement modules. The proposed AgentSemSteCom scheme obviates the need for both cover images and private semantic keys, thereby boosting steganographic capacity while reinforcing transmission security. The simulation results on open-source datasets verify that, AgentSemSteCom achieves better transmission quality and higher security levels than the baseline scheme.
Preparation and Motion Study of Magnetically Driven Micro Soft Robot Mimicking the Cownose Ray
Jan 21, 2026In narrow, unstructured underwater environments such as environmental monitoring and minimally invasive medical procedures, micro soft robots exhibit unique advantages due to their flexible movement capabilities and small size. At the same time, applying bionic technology to the structural design of micro soft robots can significantly improve their swimming performance. However, limited by their miniaturization, these robots are difficult to power internally and usually adopt a wireless power supply method. This study designs and fabricates a magnetically responsive, cownose ray-inspired micro soft robot based on the swimming principle of the cownose ray. The robot is made of a certain proportion of NdFeB and PDMS. Then, a three-dimensional Helmholtz coil is used to generate an oscillating harmonic magnetic field to conduct swimming experiments on the robot, exploring the influence of magnetic field parameters on the robot's swimming performance. The experimental results show that the swimming speed is the fastest at B = 5 mT and f = 11 Hz, reaching 5.25 mm/s, which is about 0.5 body lengths per second. In addition, by adjusting the current direction and frequency of the coil, the robot can perform different swimming modes such as straight swimming, turning swimming, and directional swimming. By employing a stepwise adjustment method, the impact of response errors on the robot's trajectory can be effectively reduced. This study demonstrates a method for magnetically driven micro soft robots, laying a foundation for the application of wireless-driven robots in underwater narrow spaces.
Physics-Inspired Modeling and Content Adaptive Routing in an Infrared Gas Leak Detection Network
Dec 29, 2025Detecting infrared gas leaks is critical for environmental monitoring and industrial safety, yet remains difficult because plumes are faint, small, semitransparent, and have weak, diffuse boundaries. We present physics-edge hybrid gas dynamic routing network (PEG-DRNet). First, we introduce the Gas Block, a diffusion-convection unit modeling gas transport: a local branch captures short-range variations, while a large-kernel branch captures long-range propagation. An edge-gated learnable fusion module balances local detail and global context, strengthening weak-contrast plume and contour cues. Second, we propose the adaptive gradient and phase edge operator (AGPEO), computing reliable edge priors from multi-directional gradients and phase-consistent responses. These are transformed by a multi-scale edge perception module (MSEPM) into hierarchical edge features that reinforce boundaries. Finally, the content-adaptive sparse routing path aggregation network (CASR-PAN), with adaptive information modulation modules for fusion and self, selectively propagates informative features across scales based on edge and content cues, improving cross-scale discriminability while reducing redundancy. Experiments on the IIG dataset show that PEG-DRNet achieves an overall AP of 29.8\%, an AP$_{50}$ of 84.3\%, and a small-object AP of 25.3\%, surpassing the RT-DETR-R18 baseline by 3.0\%, 6.5\%, and 5.3\%, respectively, while requiring only 43.7 Gflops and 14.9 M parameters. The proposed PEG-DRNet achieves superior overall performance with the best balance of accuracy and computational efficiency, outperforming existing CNN and Transformer detectors in AP and AP$_{50}$ on the IIG and LangGas dataset.
Semantic Radio Access Networks: Architecture, State-of-the-Art, and Future Directions
Dec 24, 2025Radio Access Network (RAN) is a bridge between user devices and the core network in mobile communication systems, responsible for the transmission and reception of wireless signals and air interface management. In recent years, Semantic Communication (SemCom) has represented a transformative communication paradigm that prioritizes meaning-level transmission over conventional bit-level delivery, thus providing improved spectrum efficiency, anti-interference ability in complex environments, flexible resource allocation, and enhanced user experience for RAN. However, there is still a lack of comprehensive reviews on the integration of SemCom into RAN. Motivated by this, we systematically explore recent advancements in Semantic RAN (SemRAN). We begin by introducing the fundamentals of RAN and SemCom, identifying the limitations of conventional RAN, and outlining the overall architecture of SemRAN. Subsequently, we review representative techniques of SemRAN across physical layer, data link layer, network layer, and security plane. Furthermore, we envision future services and applications enabled by SemRAN, alongside its current standardization progress. Finally, we conclude by identifying critical research challenges and outlining forward-looking directions to guide subsequent investigations in this burgeoning field.
SREC: Encrypted Semantic Super-Resolution Enhanced Communication
Sep 05, 2025Semantic communication (SemCom), as a typical paradigm of deep integration between artificial intelligence (AI) and communication technology, significantly improves communication efficiency and resource utilization efficiency. However, the security issues of SemCom are becoming increasingly prominent. Semantic features transmitted in plaintext over physical channels are easily intercepted by eavesdroppers. To address this issue, this paper proposes Encrypted Semantic Super-Resolution Enhanced Communication (SREC) to secure SemCom. SREC uses the modulo-256 encryption method to encrypt semantic features, and employs super-resolution reconstruction method to improve the reconstruction quality of images. The simulation results show that in the additive Gaussian white noise (AWGN) channel, when different modulation methods are used, SREC can not only stably guarantee security, but also achieve better transmission performance under low signal-to-noise ratio (SNR) conditions.
SemSteDiff: Generative Diffusion Model-based Coverless Semantic Steganography Communication
Sep 05, 2025Semantic communication (SemCom), as a novel paradigm for future communication systems, has recently attracted much attention due to its superiority in communication efficiency. However, similar to traditional communication, it also suffers from eavesdropping threats. Intelligent eavesdroppers could launch advanced semantic analysis techniques to infer secret semantic information. Therefore, some researchers have designed Semantic Steganography Communication (SemSteCom) scheme to confuse semantic eavesdroppers. However, the state-of-the-art SemSteCom schemes for image transmission rely on the pre-selected cover image, which limits the universality. To address this issue, we propose a Generative Diffusion Model-based Coverless Semantic Steganography Communication (SemSteDiff) scheme to hide secret images into generated stego images. The semantic related private and public keys enable legitimate receiver to decode secret images correctly while the eavesdropper without completely true key-pairs fail to obtain them. Simulation results demonstrate the effectiveness of the plug-and-play design in different Joint Source-Channel Coding (JSCC) frameworks. The comparison results under different eavesdroppers' threats show that, when Signal-to-Noise Ratio (SNR) = 0 dB, the peak signal-to-noise ratio (PSNR) of the legitimate receiver is 4.14 dB higher than that of the eavesdropper.
KGRAG-SC: Knowledge Graph RAG-Assisted Semantic Communication
Sep 05, 2025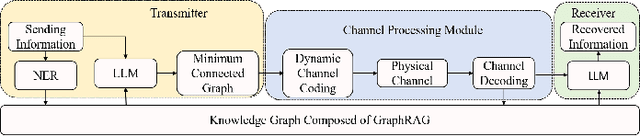
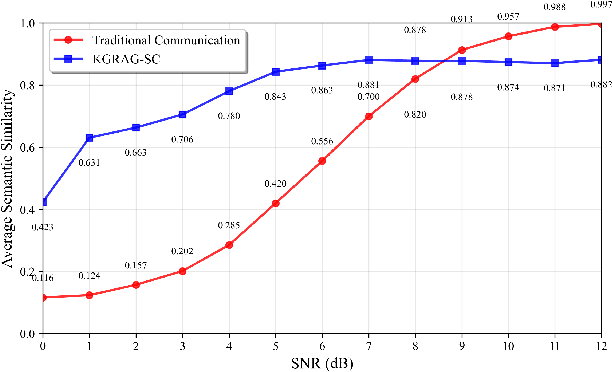
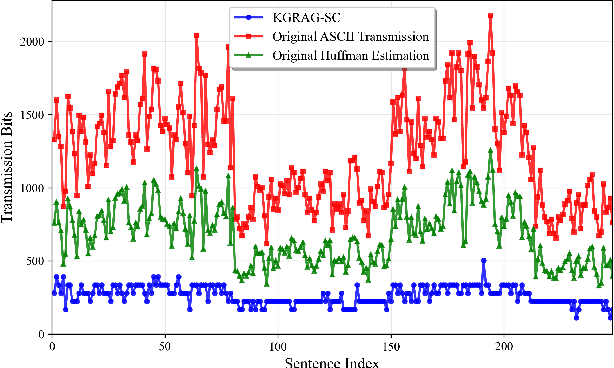
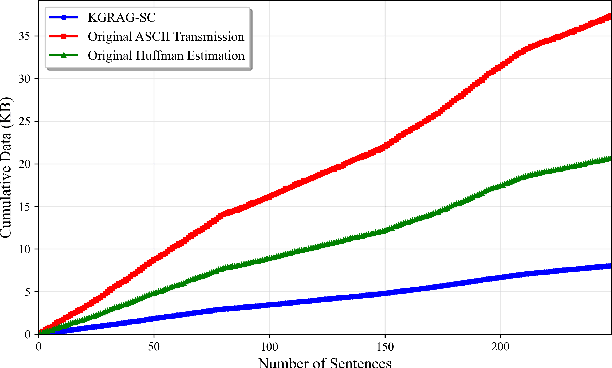
The state-of-the-art semantic communication (SC) schemes typically rely on end-to-end deep learning frameworks that lack interpretability and struggle with robust semantic selection and reconstruction under noisy conditions. To address this issue, this paper presents KGRAG-SC, a knowledge graph-assisted SC framework that leverages retrieval-augmented generation principles. KGRAG-SC employs a multi-dimensional knowledge graph, enabling efficient semantic extraction through community-guided entity linking and GraphRAG-assisted processing. The transmitter constructs minimal connected subgraphs that capture essential semantic relationships and transmits only compact entity indices rather than full text or semantic triples. An importance-aware adaptive transmission strategy provides unequal error protection based on structural centrality metrics, prioritizing critical semantic elements under adverse channel conditions. At the receiver, large language models perform knowledge-driven text reconstruction using the shared knowledge graph as structured context, ensuring robust semantic recovery even with partial information loss. Experimental results demonstrate that KGRAG-SC achieves superior semantic fidelity in low Signal-to-Noise Ratio (SNR) conditions while significantly reducing transmission overhead compared to traditional communication methods, highlighting the effectiveness of integrating structured knowledge representation with generative language models for SC systems.