 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Spatially Masked Adaptive Gated Network for multimodal post-flood water extent mapping using SAR and incomplete multispectral data
Dec 31, 2025Mapping water extent during a flood event is essential for effective disaster management throughout all phases: mitigation, preparedness, response, and recovery. In particular, during the response stage, when timely and accurate information is important, Synthetic Aperture Radar (SAR) data are primarily employed to produce water extent maps. Recently, leveraging the complementary characteristics of SAR and MSI data through a multimodal approach has emerged as a promising strategy for advancing water extent mapping using deep learning models. This approach is particularly beneficial when timely post-flood observations, acquired during or shortly after the flood peak, are limited, as it enables the use of all available imagery for more accurate post-flood water extent mapping. However, the adaptive integration of partially available MSI data into the SAR-based post-flood water extent mapping process remains underexplored. To bridge this research gap, we propose the Spatially Masked Adaptive Gated Network (SMAGNet), a multimodal deep learning model that utilizes SAR data as the primary input for post-flood water extent mapping and integrates complementary MSI data through feature fusion. In experiments on the C2S-MS Floods dataset, SMAGNet consistently outperformed other multimodal deep learning models in prediction performance across varying levels of MSI data availability. Furthermore, we found that even when MSI data were completely missing, the performance of SMAGNet remained statistically comparable to that of a U-Net model trained solely on SAR data. These findings indicate that SMAGNet enhances the model robustness to missing data as well as the applicability of multimodal deep learning in real-world flood management scenarios.
* 50 pages, 12 figures, 6 tables
How AI Agents Follow the Herd of AI? Network Effects, History, and Machine Optimism
Dec 12, 2025Understanding decision-making in multi-AI-agent frameworks is crucial for analyzing strategic interactions in network-effect-driven contexts. This study investigates how AI agents navigate network-effect games, where individual payoffs depend on peer participatio--a context underexplored in multi-agent systems despite its real-world prevalence. We introduce a novel workflow design using large language model (LLM)-based agents in repeated decision-making scenarios, systematically manipulating price trajectories (fixed, ascending, descending, random) and network-effect strength. Our key findings include: First, without historical data, agents fail to infer equilibrium. Second, ordered historical sequences (e.g., escalating prices) enable partial convergence under weak network effects but strong effects trigger persistent "AI optimism"--agents overestimate participation despite contradictory evidence. Third, randomized history disrupts convergence entirely, demonstrating that temporal coherence in data shapes LLMs' reasoning, unlike humans. These results highlight a paradigm shift: in AI-mediated systems, equilibrium outcomes depend not just on incentives, but on how history is curated, which is impossible for human.
Landslide Hazard Mapping with Geospatial Foundation Models: Geographical Generalizability, Data Scarcity, and Band Adaptability
Nov 06, 2025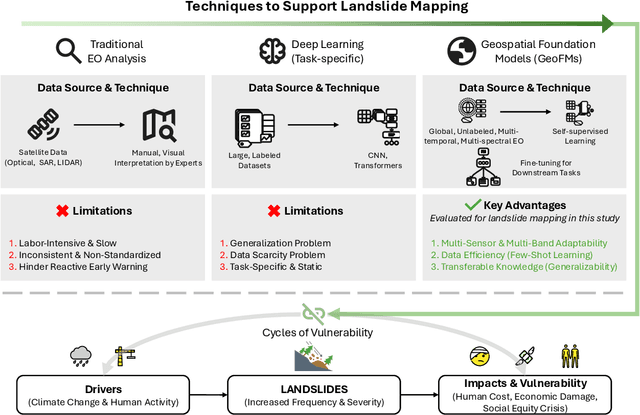
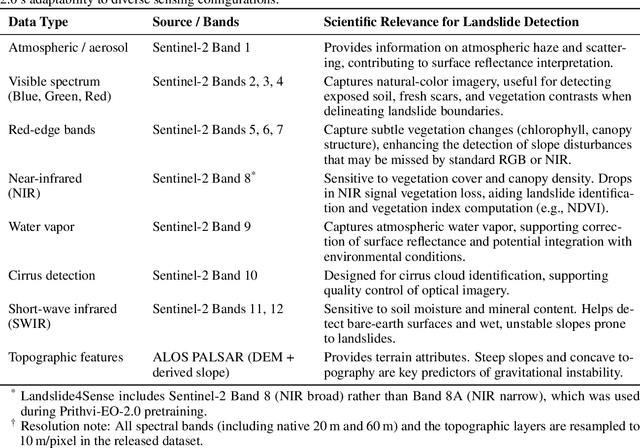
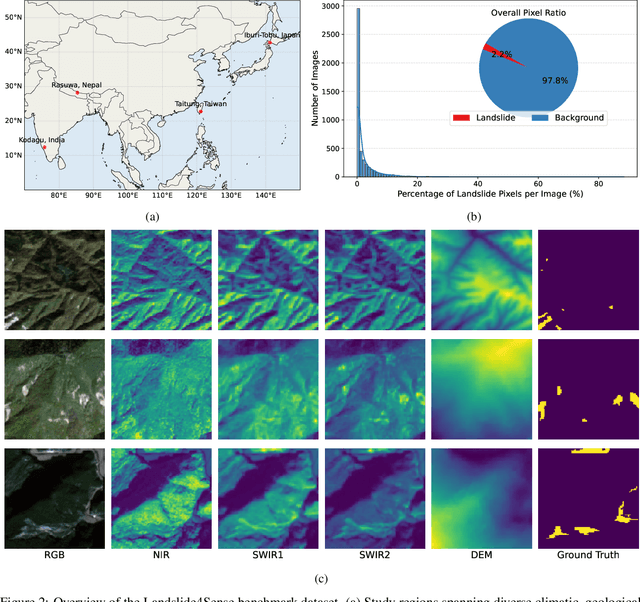
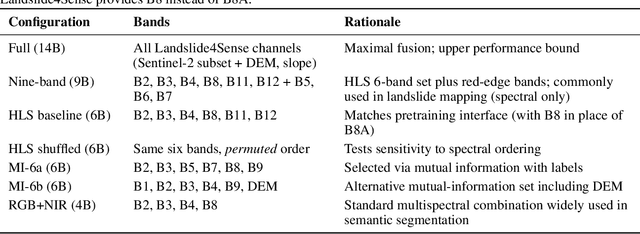
Landslides cause severe damage to lives, infrastructure, and the environment, making accurate and timely mapping essential for disaster preparedness and response. However, conventional deep learning models often struggle when applied across different sensors, regions, or under conditions of limited training data. To address these challenges, we present a three-axis analytical framework of sensor, label, and domain for adapting geospatial foundation models (GeoFMs), focusing on Prithvi-EO-2.0 for landslide mapping. Through a series of experiments, we show that it consistently outperforms task-specific CNNs (U-Net, U-Net++), vision transformers (Segformer, SwinV2-B), and other GeoFMs (TerraMind, SatMAE). The model, built on global pretraining, self-supervision, and adaptable fine-tuning, proved resilient to spectral variation, maintained accuracy under label scarcity, and generalized more reliably across diverse datasets and geographic settings. Alongside these strengths, we also highlight remaining challenges such as computational cost and the limited availability of reusable AI-ready training data for landslide research. Overall, our study positions GeoFMs as a step toward more robust and scalable approaches for landslide risk reduction and environmental monitoring.
Bayesian Optimization on Networks
Oct 31, 2025This paper studies optimization on networks modeled as metric graphs. Motivated by applications where the objective function is expensive to evaluate or only available as a black box, we develop Bayesian optimization algorithms that sequentially update a Gaussian process surrogate model of the objective to guide the acquisition of query points. To ensure that the surrogates are tailored to the network's geometry, we adopt Whittle-Mat\'ern Gaussian process prior models defined via stochastic partial differential equations on metric graphs. In addition to establishing regret bounds for optimizing sufficiently smooth objective functions, we analyze the practical case in which the smoothness of the objective is unknown and the Whittle-Mat\'ern prior is represented using finite elements. Numerical results demonstrate the effectiveness of our algorithms for optimizing benchmark objective functions on a synthetic metric graph and for Bayesian inversion via maximum a posteriori estimation on a telecommunication network.
A multi-scale vision transformer-based multimodal GeoAI model for mapping Arctic permafrost thaw
Apr 23, 2025



Retrogressive Thaw Slumps (RTS) in Arctic regions are distinct permafrost landforms with significant environmental impacts. Mapping these RTS is crucial because their appearance serves as a clear indication of permafrost thaw. However, their small scale compared to other landform features, vague boundaries, and spatiotemporal variation pose significant challenges for accurate detection. In this paper, we employed a state-of-the-art deep learning model, the Cascade Mask R-CNN with a multi-scale vision transformer-based backbone, to delineate RTS features across the Arctic. Two new strategies were introduced to optimize multimodal learning and enhance the model's predictive performance: (1) a feature-level, residual cross-modality attention fusion strategy, which effectively integrates feature maps from multiple modalities to capture complementary information and improve the model's ability to understand complex patterns and relationships within the data; (2) pre-trained unimodal learning followed by multimodal fine-tuning to alleviate high computing demand while achieving strong model performance. Experimental results demonstrated that our approach outperformed existing models adopting data-level fusion, feature-level convolutional fusion, and various attention fusion strategies, providing valuable insights into the efficient utilization of multimodal data for RTS mapping. This research contributes to our understanding of permafrost landforms and their environmental implications.
Geospatial Artificial Intelligence for Satellite-based Flood Extent Mapping: Concepts, Advances, and Future Perspectives
Apr 03, 2025
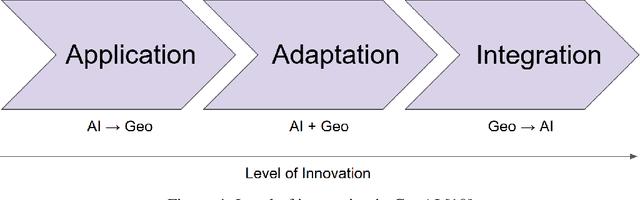

Geospatial Artificial Intelligence (GeoAI) for satellite-based flood extent mapping systematically integrates artificial intelligence techniques with satellite data to identify flood events and assess their impacts, for disaster management and spatial decision-making. The primary output often includes flood extent maps, which delineate the affected areas, along with additional analytical outputs such as uncertainty estimation and change detection.
GIScience in the Era of Artificial Intelligence: A Research Agenda Towards Autonomous GIS
Apr 01, 2025The advent of generative AI exemplified by large language models (LLMs) opens new ways to represent and compute geographic information and transcend the process of geographic knowledge production, driving geographic information systems (GIS) towards autonomous GIS. Leveraging LLMs as the decision core, autonomous GIS can independently generate and execute geoprocessing workflows to perform spatial analysis. In this vision paper, we elaborate on the concept of autonomous GIS and present a framework that defines its five autonomous goals, five levels of autonomy, five core functions, and three operational scales. We demonstrate how autonomous GIS could perform geospatial data retrieval, spatial analysis, and map making with four proof-of-concept GIS agents. We conclude by identifying critical challenges and future research directions, including fine-tuning and self-growing decision cores, autonomous modeling, and examining the ethical and practical implications of autonomous GIS. By establishing the groundwork for a paradigm shift in GIScience, this paper envisions a future where GIS moves beyond traditional workflows to autonomously reason, derive, innovate, and advance solutions to pressing global challenges.
Prithvi-EO-2.0: A Versatile Multi-Temporal Foundation Model for Earth Observation Applications
Dec 03, 2024
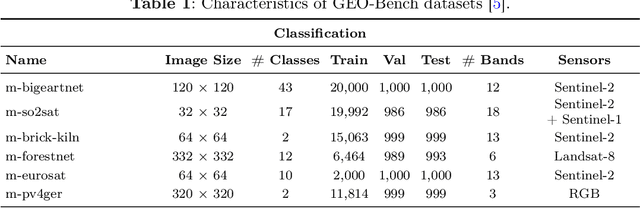
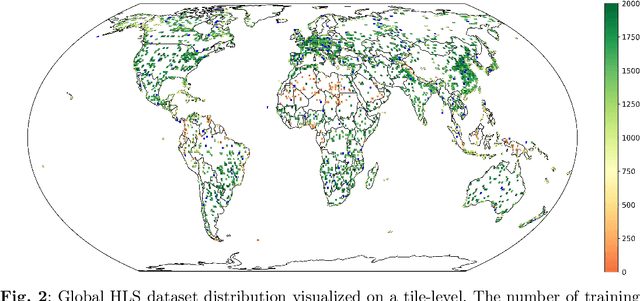
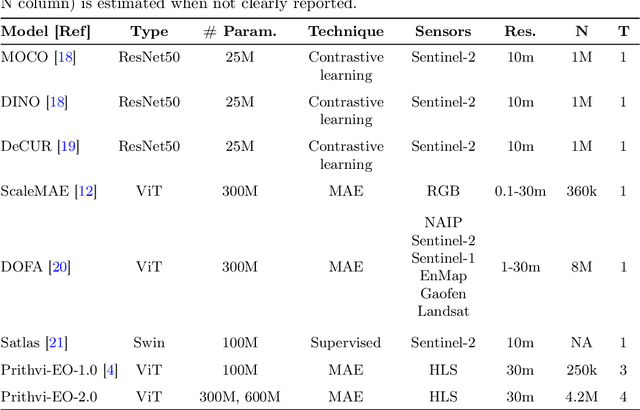
This technical report presents Prithvi-EO-2.0, a new geospatial foundation model that offers significant improvements over its predecessor, Prithvi-EO-1.0. Trained on 4.2M global time series samples from NASA's Harmonized Landsat and Sentinel-2 data archive at 30m resolution, the new 300M and 600M parameter models incorporate temporal and location embeddings for enhanced performance across various geospatial tasks. Through extensive benchmarking with GEO-Bench, the 600M version outperforms the previous Prithvi-EO model by 8\% across a range of tasks. It also outperforms six other geospatial foundation models when benchmarked on remote sensing tasks from different domains and resolutions (i.e. from 0.1m to 15m). The results demonstrate the versatility of the model in both classical earth observation and high-resolution applications. Early involvement of end-users and subject matter experts (SMEs) are among the key factors that contributed to the project's success. In particular, SME involvement allowed for constant feedback on model and dataset design, as well as successful customization for diverse SME-led applications in disaster response, land use and crop mapping, and ecosystem dynamics monitoring. Prithvi-EO-2.0 is available on Hugging Face and IBM terratorch, with additional resources on GitHub. The project exemplifies the Trusted Open Science approach embraced by all involved organizations.
Enhancing GeoAI and location encoding with spatial point pattern statistics: A Case Study of Terrain Feature Classification
Nov 21, 2024


This study introduces a novel approach to terrain feature classification by incorporating spatial point pattern statistics into deep learning models. Inspired by the concept of location encoding, which aims to capture location characteristics to enhance GeoAI decision-making capabilities, we improve the GeoAI model by a knowledge driven approach to integrate both first-order and second-order effects of point patterns. This paper investigates how these spatial contexts impact the accuracy of terrain feature predictions. The results show that incorporating spatial point pattern statistics notably enhances model performance by leveraging different representations of spatial relationships.
Advancing Large Language Models for Spatiotemporal and Semantic Association Mining of Similar Environmental Events
Nov 19, 2024



Retrieval and recommendation are two essential tasks in modern search tools. This paper introduces a novel retrieval-reranking framework leveraging Large Language Models (LLMs) to enhance the spatiotemporal and semantic associated mining and recommendation of relevant unusual climate and environmental events described in news articles and web posts. This framework uses advanced natural language processing techniques to address the limitations of traditional manual curation methods in terms of high labor cost and lack of scalability. Specifically, we explore an optimized solution to employ cutting-edge embedding models for semantically analyzing spatiotemporal events (news) and propose a Geo-Time Re-ranking (GT-R) strategy that integrates multi-faceted criteria including spatial proximity, temporal association, semantic similarity, and category-instructed similarity to rank and identify similar spatiotemporal events. We apply the proposed framework to a dataset of four thousand Local Environmental Observer (LEO) Network events, achieving top performance in recommending similar events among multiple cutting-edge dense retrieval models. The search and recommendation pipeline can be applied to a wide range of similar data search tasks dealing with geospatial and temporal data. We hope that by linking relevant events, we can better aid the general public to gain an enhanced understanding of climate change and its impact on different communities.