 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLandslide Hazard Mapping with Geospatial Foundation Models: Geographical Generalizability, Data Scarcity, and Band Adaptability
Nov 06, 2025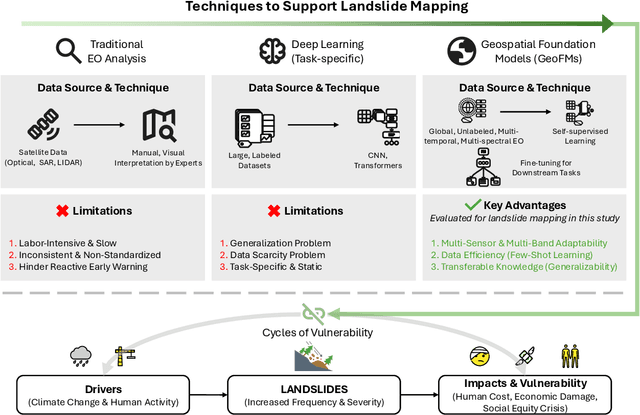
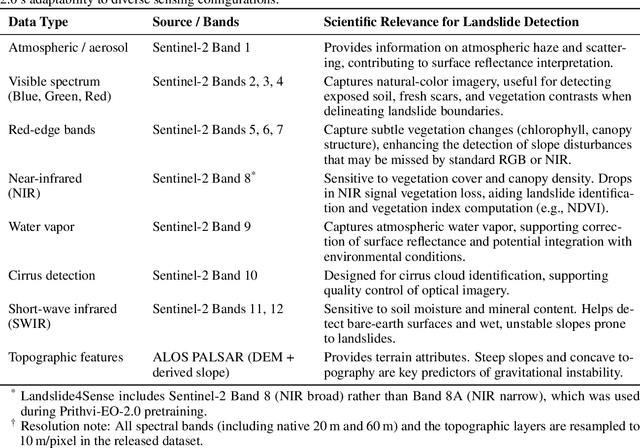
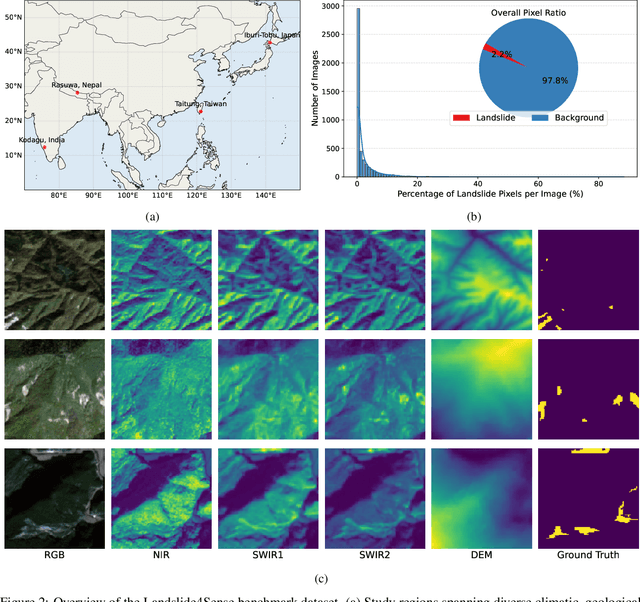
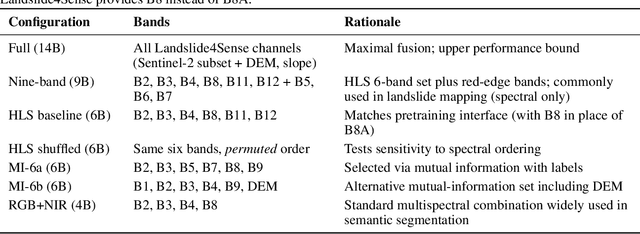
Landslides cause severe damage to lives, infrastructure, and the environment, making accurate and timely mapping essential for disaster preparedness and response. However, conventional deep learning models often struggle when applied across different sensors, regions, or under conditions of limited training data. To address these challenges, we present a three-axis analytical framework of sensor, label, and domain for adapting geospatial foundation models (GeoFMs), focusing on Prithvi-EO-2.0 for landslide mapping. Through a series of experiments, we show that it consistently outperforms task-specific CNNs (U-Net, U-Net++), vision transformers (Segformer, SwinV2-B), and other GeoFMs (TerraMind, SatMAE). The model, built on global pretraining, self-supervision, and adaptable fine-tuning, proved resilient to spectral variation, maintained accuracy under label scarcity, and generalized more reliably across diverse datasets and geographic settings. Alongside these strengths, we also highlight remaining challenges such as computational cost and the limited availability of reusable AI-ready training data for landslide research. Overall, our study positions GeoFMs as a step toward more robust and scalable approaches for landslide risk reduction and environmental monitoring.
A multi-scale vision transformer-based multimodal GeoAI model for mapping Arctic permafrost thaw
Apr 23, 2025



Retrogressive Thaw Slumps (RTS) in Arctic regions are distinct permafrost landforms with significant environmental impacts. Mapping these RTS is crucial because their appearance serves as a clear indication of permafrost thaw. However, their small scale compared to other landform features, vague boundaries, and spatiotemporal variation pose significant challenges for accurate detection. In this paper, we employed a state-of-the-art deep learning model, the Cascade Mask R-CNN with a multi-scale vision transformer-based backbone, to delineate RTS features across the Arctic. Two new strategies were introduced to optimize multimodal learning and enhance the model's predictive performance: (1) a feature-level, residual cross-modality attention fusion strategy, which effectively integrates feature maps from multiple modalities to capture complementary information and improve the model's ability to understand complex patterns and relationships within the data; (2) pre-trained unimodal learning followed by multimodal fine-tuning to alleviate high computing demand while achieving strong model performance. Experimental results demonstrated that our approach outperformed existing models adopting data-level fusion, feature-level convolutional fusion, and various attention fusion strategies, providing valuable insights into the efficient utilization of multimodal data for RTS mapping. This research contributes to our understanding of permafrost landforms and their environmental implications.
Prithvi-EO-2.0: A Versatile Multi-Temporal Foundation Model for Earth Observation Applications
Dec 03, 2024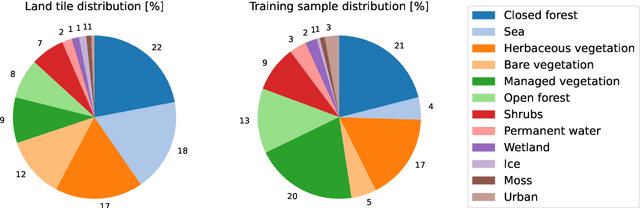
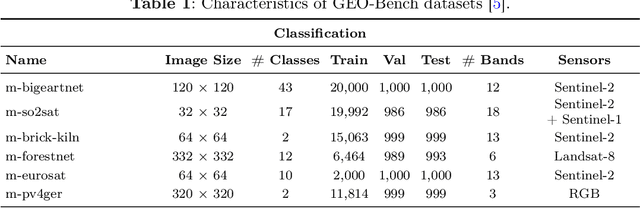
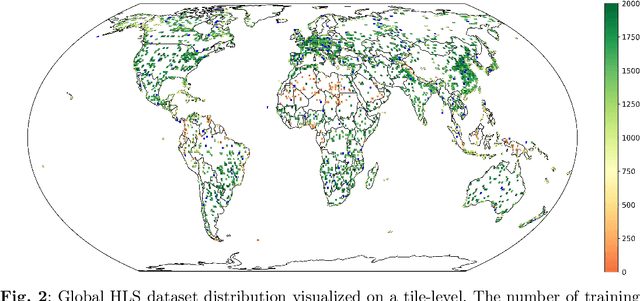
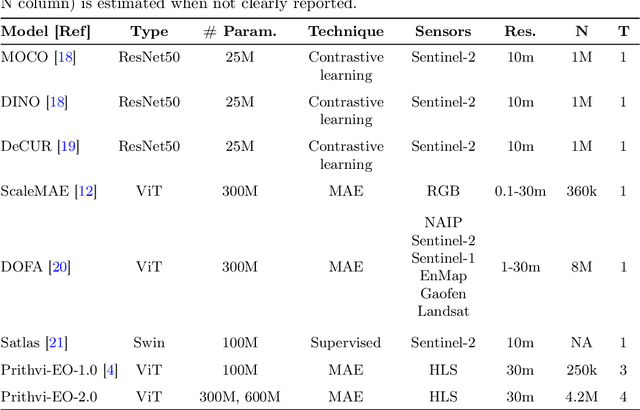
This technical report presents Prithvi-EO-2.0, a new geospatial foundation model that offers significant improvements over its predecessor, Prithvi-EO-1.0. Trained on 4.2M global time series samples from NASA's Harmonized Landsat and Sentinel-2 data archive at 30m resolution, the new 300M and 600M parameter models incorporate temporal and location embeddings for enhanced performance across various geospatial tasks. Through extensive benchmarking with GEO-Bench, the 600M version outperforms the previous Prithvi-EO model by 8\% across a range of tasks. It also outperforms six other geospatial foundation models when benchmarked on remote sensing tasks from different domains and resolutions (i.e. from 0.1m to 15m). The results demonstrate the versatility of the model in both classical earth observation and high-resolution applications. Early involvement of end-users and subject matter experts (SMEs) are among the key factors that contributed to the project's success. In particular, SME involvement allowed for constant feedback on model and dataset design, as well as successful customization for diverse SME-led applications in disaster response, land use and crop mapping, and ecosystem dynamics monitoring. Prithvi-EO-2.0 is available on Hugging Face and IBM terratorch, with additional resources on GitHub. The project exemplifies the Trusted Open Science approach embraced by all involved organizations.
Geospatial foundation models for image analysis: evaluating and enhancing NASA-IBM Prithvi's domain adaptability
Aug 31, 2024



Research on geospatial foundation models (GFMs) has become a trending topic in geospatial artificial intelligence (AI) research due to their potential for achieving high generalizability and domain adaptability, reducing model training costs for individual researchers. Unlike large language models, such as ChatGPT, constructing visual foundation models for image analysis, particularly in remote sensing, encountered significant challenges such as formulating diverse vision tasks into a general problem framework. This paper evaluates the recently released NASA-IBM GFM Prithvi for its predictive performance on high-level image analysis tasks across multiple benchmark datasets. Prithvi was selected because it is one of the first open-source GFMs trained on time-series of high-resolution remote sensing imagery. A series of experiments were designed to assess Prithvi's performance as compared to other pre-trained task-specific AI models in geospatial image analysis. New strategies, including band adaptation, multi-scale feature generation, and fine-tuning techniques, are introduced and integrated into an image analysis pipeline to enhance Prithvi's domain adaptation capability and improve model performance. In-depth analyses reveal Prithvi's strengths and weaknesses, offering insights for both improving Prithvi and developing future visual foundation models for geospatial tasks.
GeoAI Reproducibility and Replicability: a computational and spatial perspective
Apr 15, 2024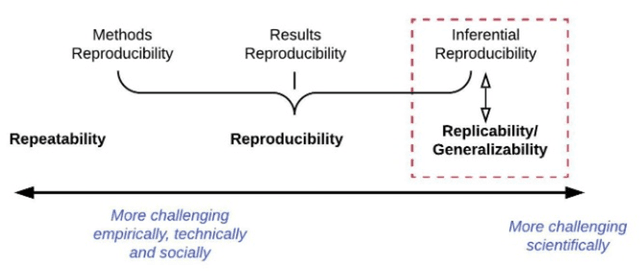
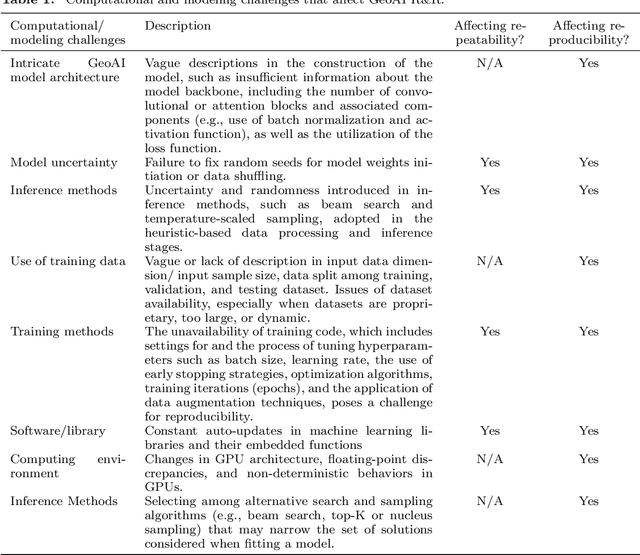

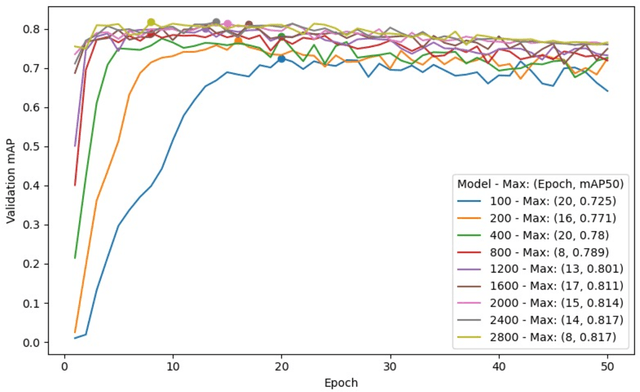
GeoAI has emerged as an exciting interdisciplinary research area that combines spatial theories and data with cutting-edge AI models to address geospatial problems in a novel, data-driven manner. While GeoAI research has flourished in the GIScience literature, its reproducibility and replicability (R&R), fundamental principles that determine the reusability, reliability, and scientific rigor of research findings, have rarely been discussed. This paper aims to provide an in-depth analysis of this topic from both computational and spatial perspectives. We first categorize the major goals for reproducing GeoAI research, namely, validation (repeatability), learning and adapting the method for solving a similar or new problem (reproducibility), and examining the generalizability of the research findings (replicability). Each of these goals requires different levels of understanding of GeoAI, as well as different methods to ensure its success. We then discuss the factors that may cause the lack of R&R in GeoAI research, with an emphasis on (1) the selection and use of training data; (2) the uncertainty that resides in the GeoAI model design, training, deployment, and inference processes; and more importantly (3) the inherent spatial heterogeneity of geospatial data and processes. We use a deep learning-based image analysis task as an example to demonstrate the results' uncertainty and spatial variance caused by different factors. The findings reiterate the importance of knowledge sharing, as well as the generation of a "replicability map" that incorporates spatial autocorrelation and spatial heterogeneity into consideration in quantifying the spatial replicability of GeoAI research.
Segment Anything Model Can Not Segment Anything: Assessing AI Foundation Model's Generalizability in Permafrost Mapping
Jan 16, 2024
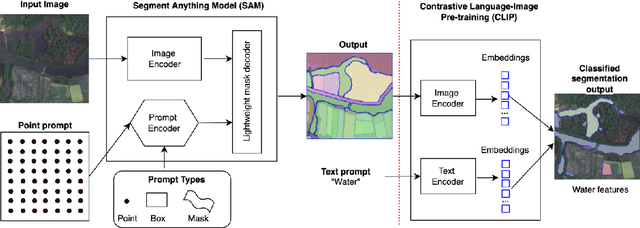
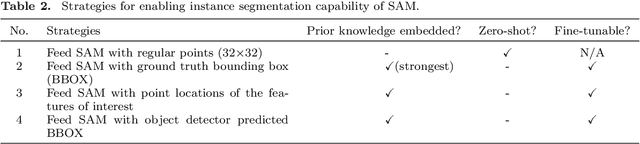

This paper assesses trending AI foundation models, especially emerging computer vision foundation models and their performance in natural landscape feature segmentation. While the term foundation model has quickly garnered interest from the geospatial domain, its definition remains vague. Hence, this paper will first introduce AI foundation models and their defining characteristics. Built upon the tremendous success achieved by Large Language Models (LLMs) as the foundation models for language tasks, this paper discusses the challenges of building foundation models for geospatial artificial intelligence (GeoAI) vision tasks. To evaluate the performance of large AI vision models, especially Meta's Segment Anything Model (SAM), we implemented different instance segmentation pipelines that minimize the changes to SAM to leverage its power as a foundation model. A series of prompt strategies was developed to test SAM's performance regarding its theoretical upper bound of predictive accuracy, zero-shot performance, and domain adaptability through fine-tuning. The analysis used two permafrost feature datasets, ice-wedge polygons and retrogressive thaw slumps because (1) these landform features are more challenging to segment than manmade features due to their complicated formation mechanisms, diverse forms, and vague boundaries; (2) their presence and changes are important indicators for Arctic warming and climate change. The results show that although promising, SAM still has room for improvement to support AI-augmented terrain mapping. The spatial and domain generalizability of this finding is further validated using a more general dataset EuroCrop for agricultural field mapping. Finally, we discuss future research directions that strengthen SAM's applicability in challenging geospatial domains.
Assessment of IBM and NASA's geospatial foundation model in flood inundation mapping
Sep 25, 2023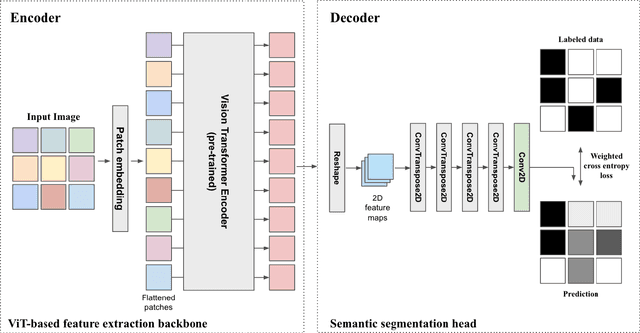
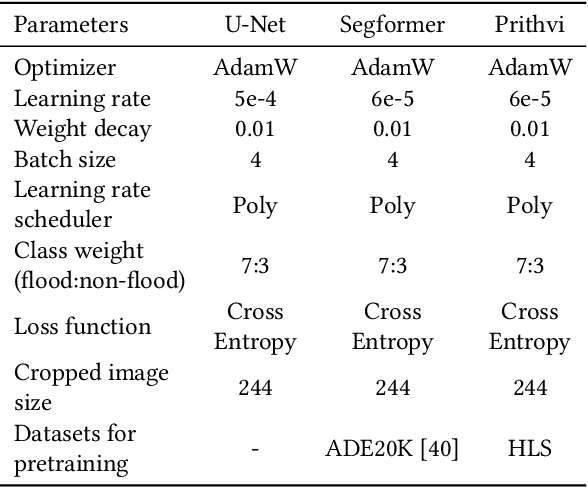
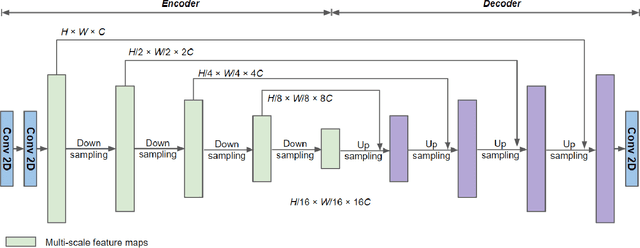

Vision foundation models are a new frontier in GeoAI research because of their potential to enable powerful image analysis by learning and extracting important image features from vast amounts of geospatial data. This paper evaluates the performance of the first-of-its-kind geospatial foundation model, IBM-NASA's Prithvi, to support a crucial geospatial analysis task: flood inundation mapping. This model is compared with popular convolutional neural network and vision transformer-based architectures in terms of mapping accuracy for flooded areas. A benchmark dataset, Sen1Floods11, is used in the experiments, and the models' predictability, generalizability, and transferability are evaluated based on both a test dataset and a dataset that is completely unseen by the model. Results show the impressive transferability of the Prithvi model, highlighting its performance advantages in segmenting flooded areas in previously unseen regions. The findings also suggest areas for improvement for the Prithvi model in terms of adopting multi-scale representation learning, developing more end-to-end pipelines for high-level image analysis tasks, and offering more flexibility in terms of input data bands.
Real-time GeoAI for High-resolution Mapping and Segmentation of Arctic Permafrost Features
Jun 08, 2023This paper introduces a real-time GeoAI workflow for large-scale image analysis and the segmentation of Arctic permafrost features at a fine-granularity. Very high-resolution (0.5m) commercial imagery is used in this analysis. To achieve real-time prediction, our workflow employs a lightweight, deep learning-based instance segmentation model, SparseInst, which introduces and uses Instance Activation Maps to accurately locate the position of objects within the image scene. Experimental results show that the model can achieve better accuracy of prediction at a much faster inference speed than the popular Mask-RCNN model.
Explainable GeoAI: Can saliency maps help interpret artificial intelligence's learning process? An empirical study on natural feature detection
Mar 16, 2023Improving the interpretability of geospatial artificial intelligence (GeoAI) models has become critically important to open the "black box" of complex AI models, such as deep learning. This paper compares popular saliency map generation techniques and their strengths and weaknesses in interpreting GeoAI and deep learning models' reasoning behaviors, particularly when applied to geospatial analysis and image processing tasks. We surveyed two broad classes of model explanation methods: perturbation-based and gradient-based methods. The former identifies important image areas, which help machines make predictions by modifying a localized area of the input image. The latter evaluates the contribution of every single pixel of the input image to the model's prediction results through gradient backpropagation. In this study, three algorithms-the occlusion method, the integrated gradients method, and the class activation map method-are examined for a natural feature detection task using deep learning. The algorithms' strengths and weaknesses are discussed, and the consistency between model-learned and human-understandable concepts for object recognition is also compared. The experiments used two GeoAI-ready datasets to demonstrate the generalizability of the research findings.
Learning from Counting: Leveraging Temporal Classification for Weakly Supervised Object Localization and Detection
Mar 06, 2021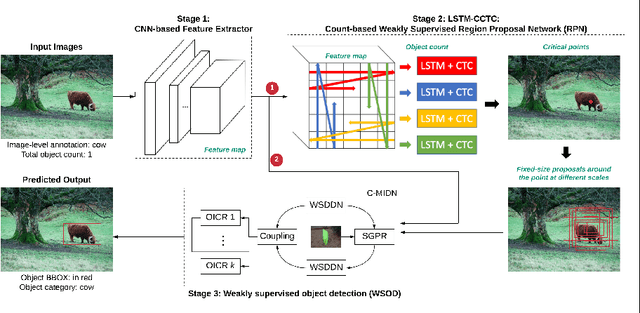

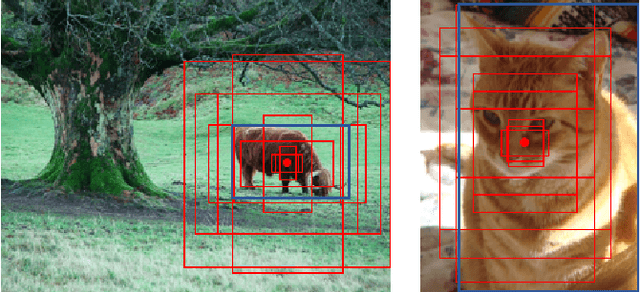
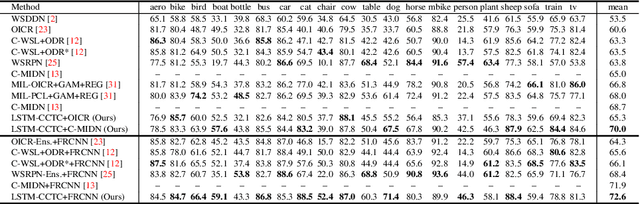
This paper reports a new solution of leveraging temporal classification to support weakly supervised object detection (WSOD). Specifically, we introduce raster scan-order techniques to serialize 2D images into 1D sequence data, and then leverage a combined LSTM (Long, Short-Term Memory) and CTC (Connectionist Temporal Classification) network to achieve object localization based on a total count (of interested objects). We term our proposed network LSTM-CCTC (Count-based CTC). This "learning from counting" strategy differs from existing WSOD methods in that our approach automatically identifies critical points on or near a target object. This strategy significantly reduces the need of generating a large number of candidate proposals for object localization. Experiments show that our method yields state-of-the-art performance based on an evaluation on PASCAL VOC datasets.