 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessment of IBM and NASA's geospatial foundation model in flood inundation mapping
Paper and Code
Sep 25, 2023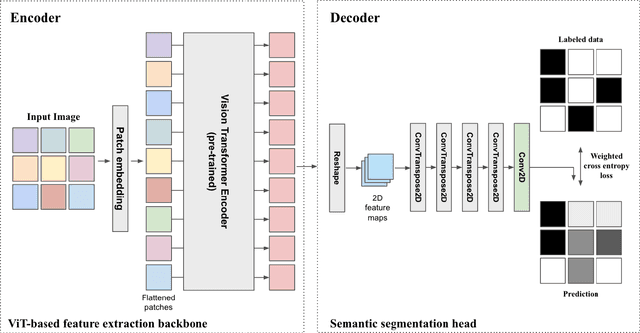
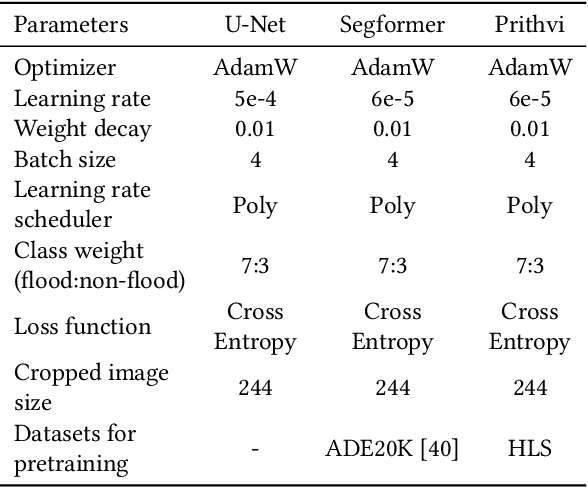
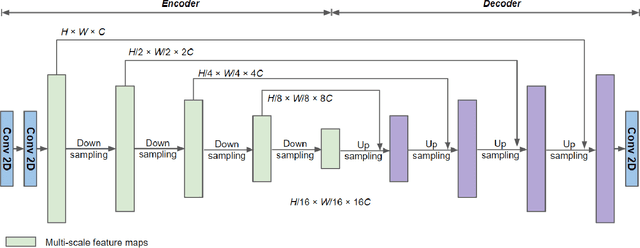

Vision foundation models are a new frontier in GeoAI research because of their potential to enable powerful image analysis by learning and extracting important image features from vast amounts of geospatial data. This paper evaluates the performance of the first-of-its-kind geospatial foundation model, IBM-NASA's Prithvi, to support a crucial geospatial analysis task: flood inundation mapping. This model is compared with popular convolutional neural network and vision transformer-based architectures in terms of mapping accuracy for flooded areas. A benchmark dataset, Sen1Floods11, is used in the experiments, and the models' predictability, generalizability, and transferability are evaluated based on both a test dataset and a dataset that is completely unseen by the model. Results show the impressive transferability of the Prithvi model, highlighting its performance advantages in segmenting flooded areas in previously unseen regions. The findings also suggest areas for improvement for the Prithvi model in terms of adopting multi-scale representation learning, developing more end-to-end pipelines for high-level image analysis tasks, and offering more flexibility in terms of input data bands.