 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeam MKC at CLPsych 2026: Capturing and Characterizing Mental Health Changes through Social Media Timeline Dynamics
Jun 30, 2026Recent advances in Large Language Models (LLMs) have motivated their adoption across a wide range of domains, including Artificial Intelligence (AI) for mental health. Given the growing prevalence of mental health disorders worldwide and the limited accessibility of professional care, there is an increasing demand for scalable computational approaches that can assist in early detection and continuous monitoring of psychological well-being. In this area, ongoing efforts have focused on curating domain-specific datasets and leveraging them to develop LLMs capable of supporting holistic mental health analysis. In line with this direction, we propose an LLM-based pipeline for comprehensive mental health analysis over sequentially ordered user posts, as part of the CLPsych shared task. Our pipeline offers a unified framework that jointly enables post-level assessment and user-level temporal modeling.
Zero-Shot Quantization for Object Detectors using Off-the-Shelf Generative Models
Jun 30, 2026With an increasing number of Object Detection (OD) models being deployed on edge devices, Zero-Shot Quantization for OD (ZSQ-OD) aims to quantize these models when access to the original training data is prohibited. Existing research on Zero-Shot Quantization-Aware Training (QAT) for OD synthesizes training sets through noise optimization. However, this approach struggles to maintain performance in low-bit regions. In this paper, we introduce GoodQ (Generative off-the-shelf models for object detector Quantization), a QAT pipeline that utilizes off-the-shelf generative models to construct a training set. We first identify three challenges that arise when introducing a generative model to the ZSQ-OD task: 1) each image contains dense information with multiple instances, 2) the class-wise distribution in the original dataset is imbalanced, and 3) the pseudo-labels assigned to the generated images can potentially act as noisy signals during QAT. GoodQ addresses these challenges by 1) introducing an Information-Dense Prompting strategy to generate multi-instance images, 2) applying Intrinsic Distribution-Aware Selection to match the pretrained class distribution, and 3) employing Teacher-guided Adaptive Noise Reduction to mitigate noise arising from the QAT process. Our framework achieves state-of-the-art performance in low-bit ZSQ (W4A4) and extends quantization to extreme bit-widths (W3A3). Furthermore, we conduct an extensive analysis to uncover the underlying factors contributing to the efficacy of GoodQ.
ReSpinQuant: Efficient Layer-Wise LLM Quantization via Subspace Residual Rotation Approximation
Apr 13, 2026Rotation-based Post-Training Quantization (PTQ) has emerged as a promising solution for mitigating activation outliers in the quantization of Large Language Models (LLMs). Global rotation methods achieve inference efficiency by fusing activation rotations into attention and FFN blocks, but suffer from limited expressivity as they are constrained to use a single learnable rotation matrix across all layers. To tackle this, layer-wise transformation methods emerged, achieving superior accuracy through localized adaptation. However, layer-wise methods cannot fuse activation rotation matrices into weights, requiring online computations and causing significant overhead. In this paper, we propose ReSpinQuant, a quantization framework that resolves such overhead by leveraging offline activation rotation fusion and matching basis using efficient residual subspace rotation. This design reconciles the high expressivity of layer-wise adaptation with only negligible inference overhead. Extensive experiments on W4A4 and W3A3 quantization demonstrate that ReSpinQuant achieves state-of-the-art performance, outperforming global rotation methods and matching the accuracy of computationally expensive layer-wise methods with minimal overhead.
A Spatially Masked Adaptive Gated Network for multimodal post-flood water extent mapping using SAR and incomplete multispectral data
Dec 31, 2025Mapping water extent during a flood event is essential for effective disaster management throughout all phases: mitigation, preparedness, response, and recovery. In particular, during the response stage, when timely and accurate information is important, Synthetic Aperture Radar (SAR) data are primarily employed to produce water extent maps. Recently, leveraging the complementary characteristics of SAR and MSI data through a multimodal approach has emerged as a promising strategy for advancing water extent mapping using deep learning models. This approach is particularly beneficial when timely post-flood observations, acquired during or shortly after the flood peak, are limited, as it enables the use of all available imagery for more accurate post-flood water extent mapping. However, the adaptive integration of partially available MSI data into the SAR-based post-flood water extent mapping process remains underexplored. To bridge this research gap, we propose the Spatially Masked Adaptive Gated Network (SMAGNet), a multimodal deep learning model that utilizes SAR data as the primary input for post-flood water extent mapping and integrates complementary MSI data through feature fusion. In experiments on the C2S-MS Floods dataset, SMAGNet consistently outperformed other multimodal deep learning models in prediction performance across varying levels of MSI data availability. Furthermore, we found that even when MSI data were completely missing, the performance of SMAGNet remained statistically comparable to that of a U-Net model trained solely on SAR data. These findings indicate that SMAGNet enhances the model robustness to missing data as well as the applicability of multimodal deep learning in real-world flood management scenarios.
* 50 pages, 12 figures, 6 tables
Landslide Hazard Mapping with Geospatial Foundation Models: Geographical Generalizability, Data Scarcity, and Band Adaptability
Nov 06, 2025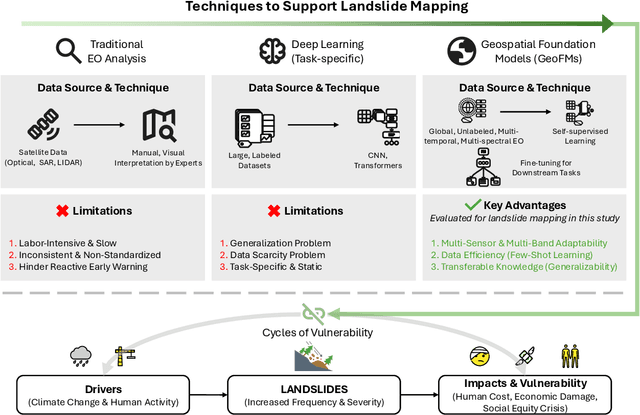
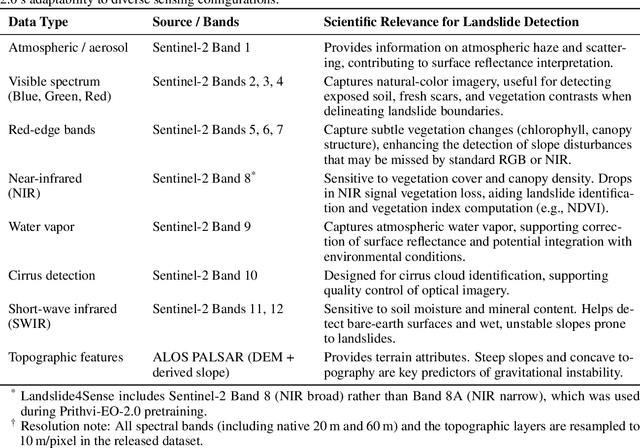
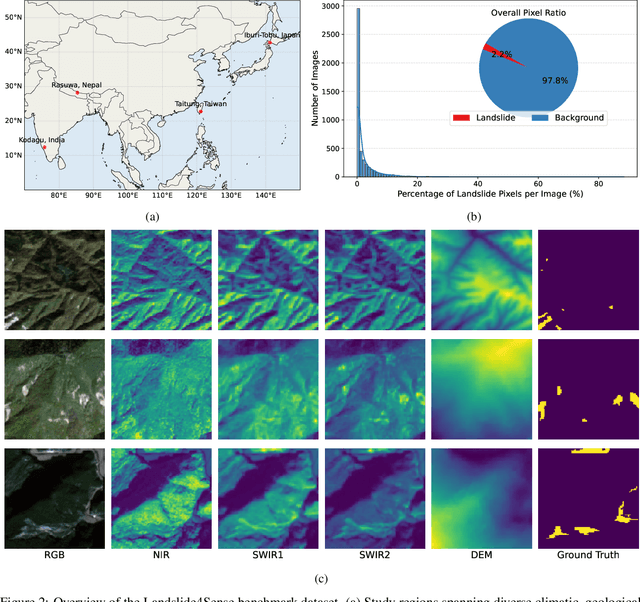
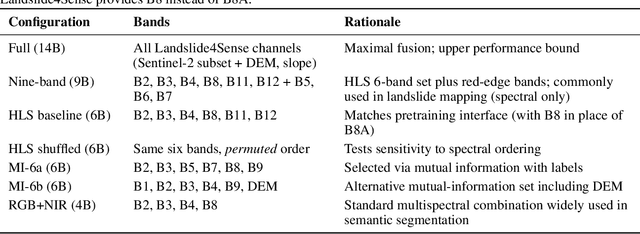
Landslides cause severe damage to lives, infrastructure, and the environment, making accurate and timely mapping essential for disaster preparedness and response. However, conventional deep learning models often struggle when applied across different sensors, regions, or under conditions of limited training data. To address these challenges, we present a three-axis analytical framework of sensor, label, and domain for adapting geospatial foundation models (GeoFMs), focusing on Prithvi-EO-2.0 for landslide mapping. Through a series of experiments, we show that it consistently outperforms task-specific CNNs (U-Net, U-Net++), vision transformers (Segformer, SwinV2-B), and other GeoFMs (TerraMind, SatMAE). The model, built on global pretraining, self-supervision, and adaptable fine-tuning, proved resilient to spectral variation, maintained accuracy under label scarcity, and generalized more reliably across diverse datasets and geographic settings. Alongside these strengths, we also highlight remaining challenges such as computational cost and the limited availability of reusable AI-ready training data for landslide research. Overall, our study positions GeoFMs as a step toward more robust and scalable approaches for landslide risk reduction and environmental monitoring.
Style Composition within Distinct LoRA modules for Traditional Art
Jul 16, 2025Diffusion-based text-to-image models have achieved remarkable results in synthesizing diverse images from text prompts and can capture specific artistic styles via style personalization. However, their entangled latent space and lack of smooth interpolation make it difficult to apply distinct painting techniques in a controlled, regional manner, often causing one style to dominate. To overcome this, we propose a zero-shot diffusion pipeline that naturally blends multiple styles by performing style composition on the denoised latents predicted during the flow-matching denoising process of separately trained, style-specialized models. We leverage the fact that lower-noise latents carry stronger stylistic information and fuse them across heterogeneous diffusion pipelines using spatial masks, enabling precise, region-specific style control. This mechanism preserves the fidelity of each individual style while allowing user-guided mixing. Furthermore, to ensure structural coherence across different models, we incorporate depth-map conditioning via ControlNet into the diffusion framework. Qualitative and quantitative experiments demonstrate that our method successfully achieves region-specific style mixing according to the given masks.
Geospatial Artificial Intelligence for Satellite-based Flood Extent Mapping: Concepts, Advances, and Future Perspectives
Apr 03, 2025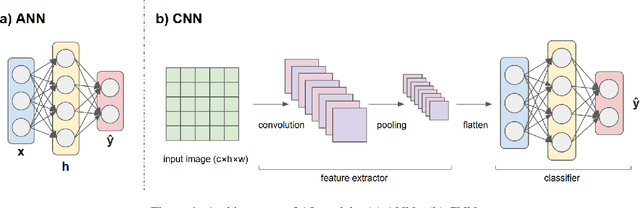
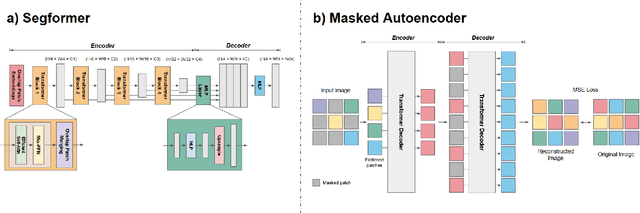

Geospatial Artificial Intelligence (GeoAI) for satellite-based flood extent mapping systematically integrates artificial intelligence techniques with satellite data to identify flood events and assess their impacts, for disaster management and spatial decision-making. The primary output often includes flood extent maps, which delineate the affected areas, along with additional analytical outputs such as uncertainty estimation and change detection.
Prithvi-EO-2.0: A Versatile Multi-Temporal Foundation Model for Earth Observation Applications
Dec 03, 2024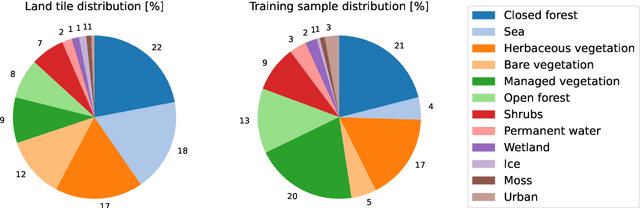
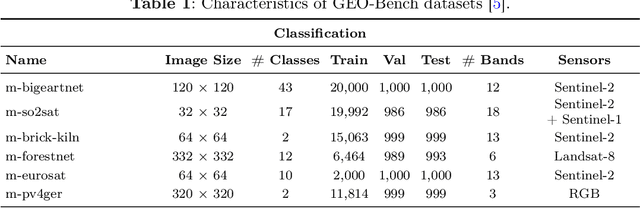
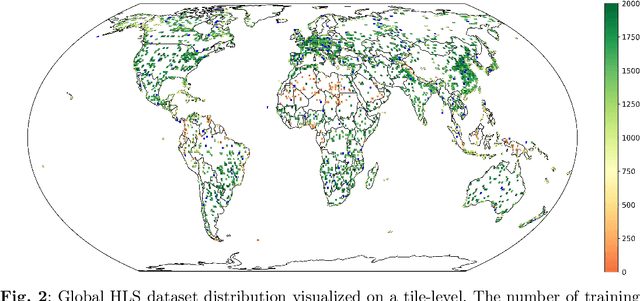
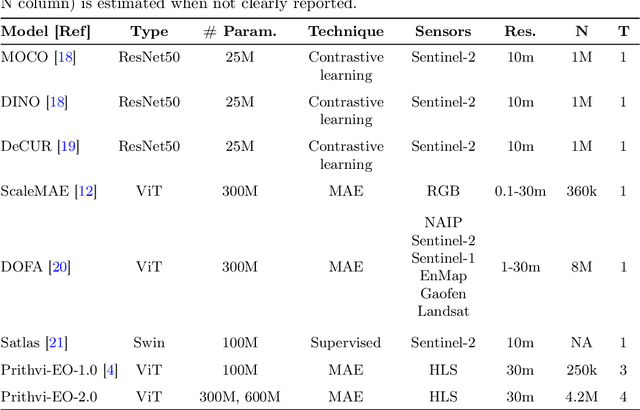
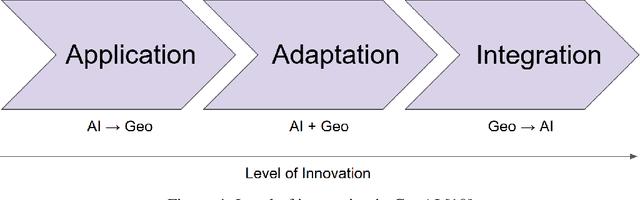
This technical report presents Prithvi-EO-2.0, a new geospatial foundation model that offers significant improvements over its predecessor, Prithvi-EO-1.0. Trained on 4.2M global time series samples from NASA's Harmonized Landsat and Sentinel-2 data archive at 30m resolution, the new 300M and 600M parameter models incorporate temporal and location embeddings for enhanced performance across various geospatial tasks. Through extensive benchmarking with GEO-Bench, the 600M version outperforms the previous Prithvi-EO model by 8\% across a range of tasks. It also outperforms six other geospatial foundation models when benchmarked on remote sensing tasks from different domains and resolutions (i.e. from 0.1m to 15m). The results demonstrate the versatility of the model in both classical earth observation and high-resolution applications. Early involvement of end-users and subject matter experts (SMEs) are among the key factors that contributed to the project's success. In particular, SME involvement allowed for constant feedback on model and dataset design, as well as successful customization for diverse SME-led applications in disaster response, land use and crop mapping, and ecosystem dynamics monitoring. Prithvi-EO-2.0 is available on Hugging Face and IBM terratorch, with additional resources on GitHub. The project exemplifies the Trusted Open Science approach embraced by all involved organizations.
Practical Dataset Distillation Based on Deep Support Vectors
May 01, 2024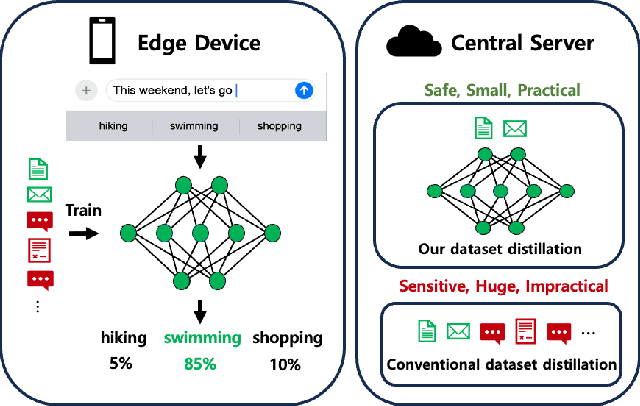
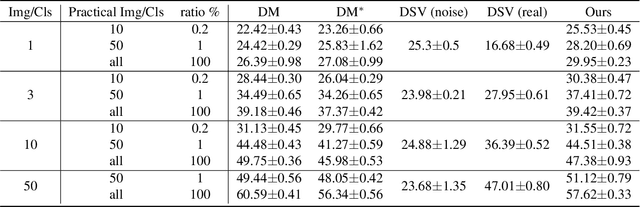


Conventional dataset distillation requires significant computational resources and assumes access to the entire dataset, an assumption impractical as it presumes all data resides on a central server. In this paper, we focus on dataset distillation in practical scenarios with access to only a fraction of the entire dataset. We introduce a novel distillation method that augments the conventional process by incorporating general model knowledge via the addition of Deep KKT (DKKT) loss. In practical settings, our approach showed improved performance compared to the baseline distribution matching distillation method on the CIFAR-10 dataset. Additionally, we present experimental evidence that Deep Support Vectors (DSVs) offer unique information to the original distillation, and their integration results in enhanced performance.
Improving Interpretability of Deep Active Learning for Flood Inundation Mapping Through Class Ambiguity Indices Using Multi-spectral Satellite Imagery
Apr 29, 2024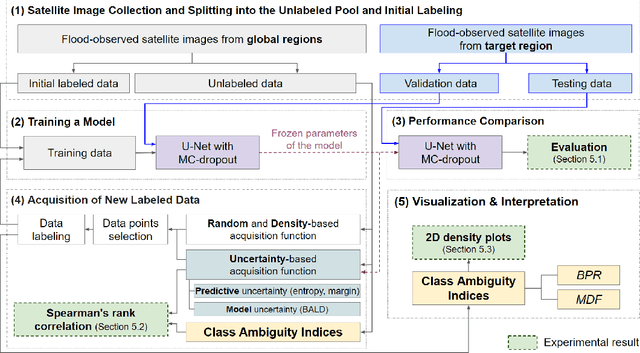
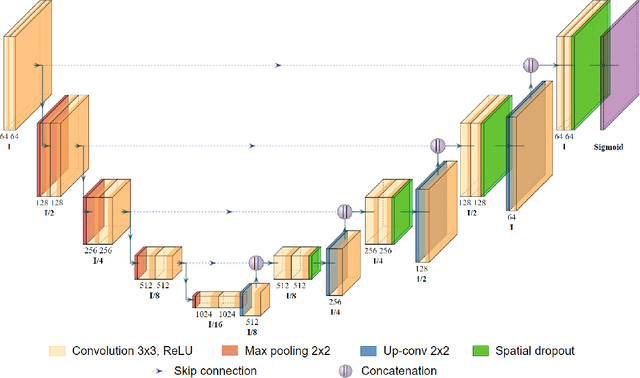

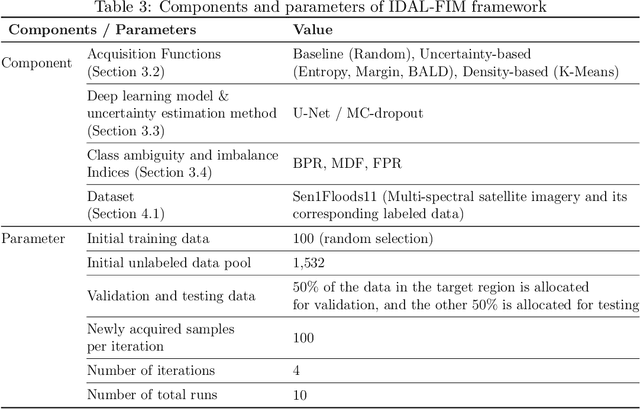
Flood inundation mapping is a critical task for responding to the increasing risk of flooding linked to global warming. Significant advancements of deep learning in recent years have triggered its extensive applications, including flood inundation mapping. To cope with the time-consuming and labor-intensive data labeling process in supervised learning, deep active learning strategies are one of the feasible approaches. However, there remains limited exploration into the interpretability of how deep active learning strategies operate, with a specific focus on flood inundation mapping in the field of remote sensing. In this study, we introduce a novel framework of Interpretable Deep Active Learning for Flood inundation Mapping (IDAL-FIM), specifically in terms of class ambiguity of multi-spectral satellite images. In the experiments, we utilize Sen1Floods11 dataset, and adopt U-Net with MC-dropout. In addition, we employ five acquisition functions, which are the random, K-means, BALD, entropy, and margin acquisition functions. Based on the experimental results, we demonstrate that two proposed class ambiguity indices are effective variables to interpret the deep active learning by establishing statistically significant correlation with the predictive uncertainty of the deep learning model at the tile level. Then, we illustrate the behaviors of deep active learning through visualizing two-dimensional density plots and providing interpretations regarding the operation of deep active learning, in flood inundation mapping.