 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTranslation Deserves Better: Analyzing Translation Artifacts in Cross-lingual Visual Question Answering
Jun 04, 2024
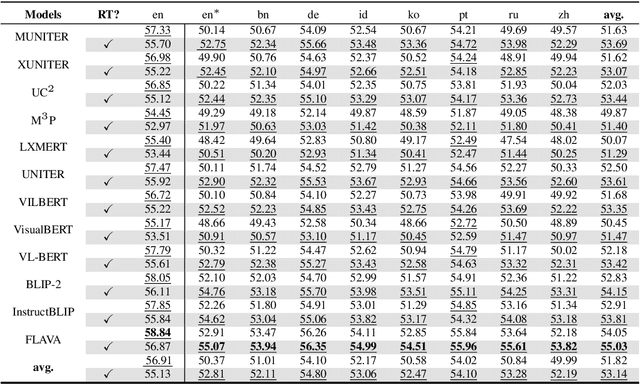


Building a reliable visual question answering~(VQA) system across different languages is a challenging problem, primarily due to the lack of abundant samples for training. To address this challenge, recent studies have employed machine translation systems for the cross-lingual VQA task. This involves translating the evaluation samples into a source language (usually English) and using monolingual models (i.e., translate-test). However, our analysis reveals that translated texts contain unique characteristics distinct from human-written ones, referred to as translation artifacts. We find that these artifacts can significantly affect the models, confirmed by extensive experiments across diverse models, languages, and translation processes. In light of this, we present a simple data augmentation strategy that can alleviate the adverse impacts of translation artifacts.
Towards Accurate Translation via Semantically Appropriate Application of Lexical Constraints
Jun 21, 2023
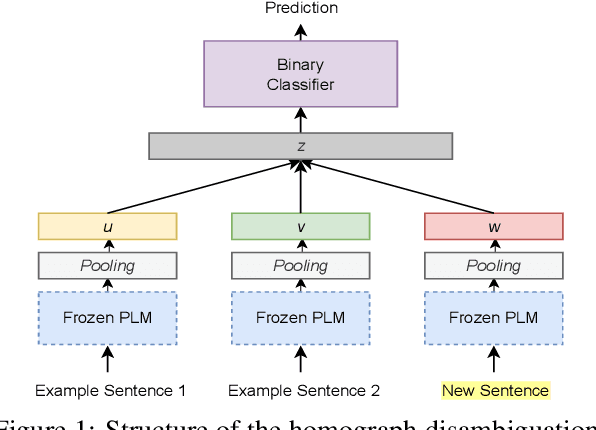

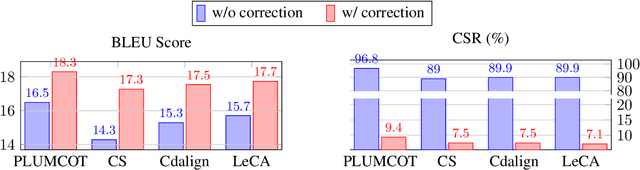
Lexically-constrained NMT (LNMT) aims to incorporate user-provided terminology into translations. Despite its practical advantages, existing work has not evaluated LNMT models under challenging real-world conditions. In this paper, we focus on two important but under-studied issues that lie in the current evaluation process of LNMT studies. The model needs to cope with challenging lexical constraints that are "homographs" or "unseen" during training. To this end, we first design a homograph disambiguation module to differentiate the meanings of homographs. Moreover, we propose PLUMCOT, which integrates contextually rich information about unseen lexical constraints from pre-trained language models and strengthens a copy mechanism of the pointer network via direct supervision of a copying score. We also release HOLLY, an evaluation benchmark for assessing the ability of a model to cope with "homographic" and "unseen" lexical constraints. Experiments on HOLLY and the previous test setup show the effectiveness of our method. The effects of PLUMCOT are shown to be remarkable in "unseen" constraints. Our dataset is available at https://github.com/papago-lab/HOLLY-benchmark
On the Importance of Feature Decorrelation for Unsupervised Representation Learning in Reinforcement Learning
Jun 09, 2023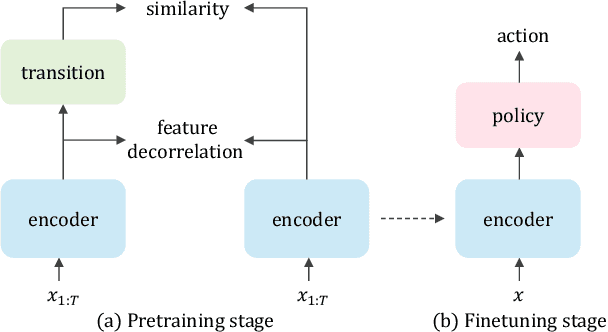

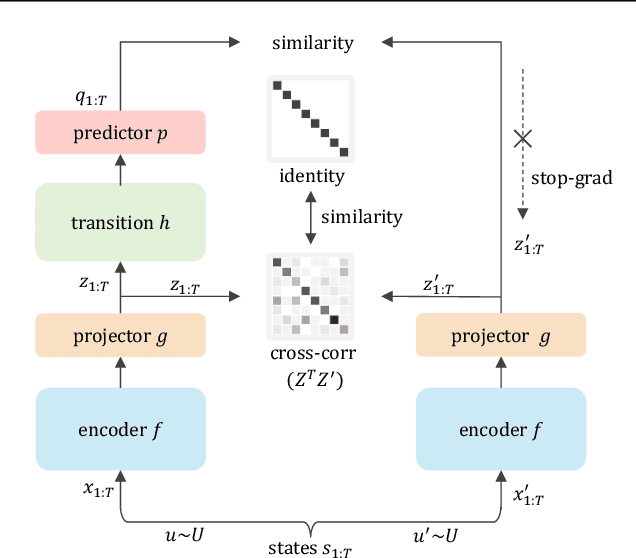
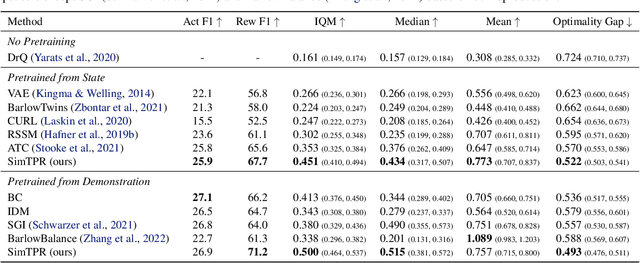
Recently, unsupervised representation learning (URL) has improved the sample efficiency of Reinforcement Learning (RL) by pretraining a model from a large unlabeled dataset. The underlying principle of these methods is to learn temporally predictive representations by predicting future states in the latent space. However, an important challenge of this approach is the representational collapse, where the subspace of the latent representations collapses into a low-dimensional manifold. To address this issue, we propose a novel URL framework that causally predicts future states while increasing the dimension of the latent manifold by decorrelating the features in the latent space. Through extensive empirical studies, we demonstrate that our framework effectively learns predictive representations without collapse, which significantly improves the sample efficiency of state-of-the-art URL methods on the Atari 100k benchmark. The code is available at https://github.com/dojeon-ai/SimTPR.