 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting Pretrained ViTs with Convolution Injector for Visuo-Motor Control
Jun 10, 2024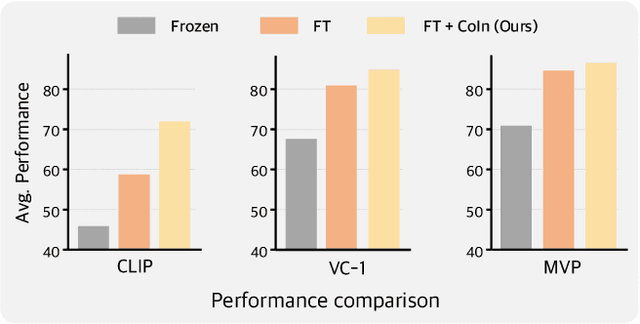
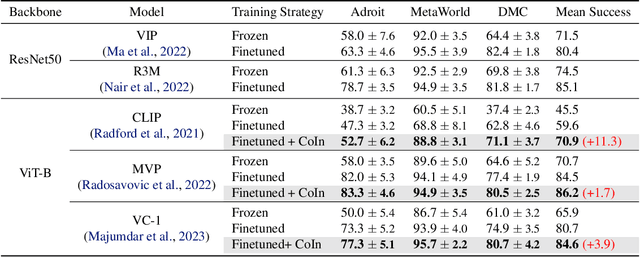
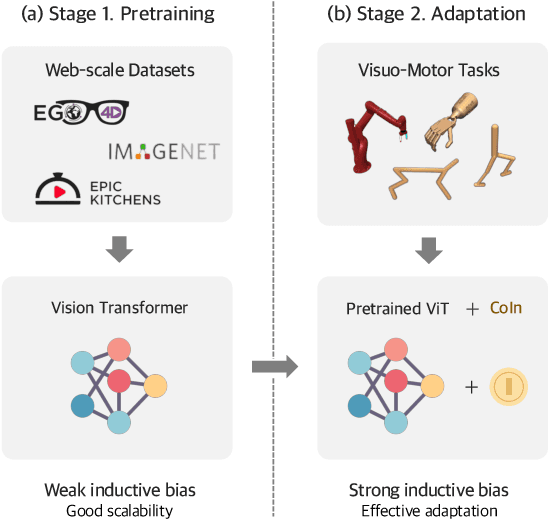
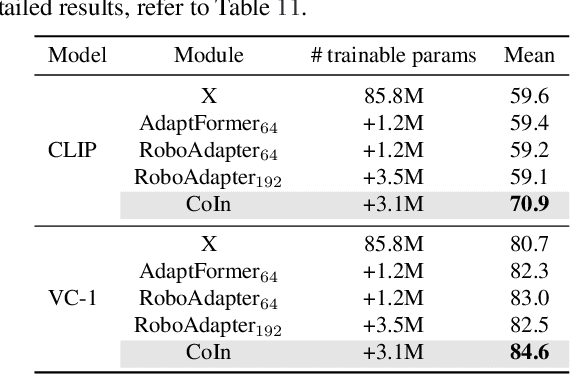
Vision Transformers (ViT), when paired with large-scale pretraining, have shown remarkable performance across various computer vision tasks, primarily due to their weak inductive bias. However, while such weak inductive bias aids in pretraining scalability, this may hinder the effective adaptation of ViTs for visuo-motor control tasks as a result of the absence of control-centric inductive biases. Such absent inductive biases include spatial locality and translation equivariance bias which convolutions naturally offer. To this end, we introduce Convolution Injector (CoIn), an add-on module that injects convolutions which are rich in locality and equivariance biases into a pretrained ViT for effective adaptation in visuo-motor control. We evaluate CoIn with three distinct types of pretrained ViTs (CLIP, MVP, VC-1) across 12 varied control tasks within three separate domains (Adroit, MetaWorld, DMC), and demonstrate that CoIn consistently enhances control task performance across all experimented environments and models, validating the effectiveness of providing pretrained ViTs with control-centric biases.
Do's and Don'ts: Learning Desirable Skills with Instruction Videos
Jun 01, 2024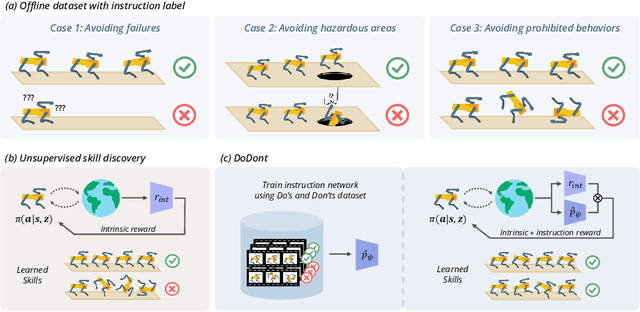


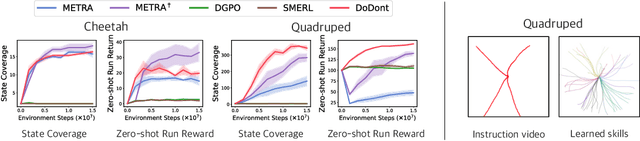
Unsupervised skill discovery is a learning paradigm that aims to acquire diverse behaviors without explicit rewards. However, it faces challenges in learning complex behaviors and often leads to learning unsafe or undesirable behaviors. For instance, in various continuous control tasks, current unsupervised skill discovery methods succeed in learning basic locomotions like standing but struggle with learning more complex movements such as walking and running. Moreover, they may acquire unsafe behaviors like tripping and rolling or navigate to undesirable locations such as pitfalls or hazardous areas. In response, we present DoDont (Do's and Don'ts), an instruction-based skill discovery algorithm composed of two stages. First, in an instruction learning stage, DoDont leverages action-free instruction videos to train an instruction network to distinguish desirable transitions from undesirable ones. Then, in the skill learning stage, the instruction network adjusts the reward function of the skill discovery algorithm to weight the desired behaviors. Specifically, we integrate the instruction network into a distance-maximizing skill discovery algorithm, where the instruction network serves as the distance function. Empirically, with less than 8 instruction videos, DoDont effectively learns desirable behaviors and avoids undesirable ones across complex continuous control tasks. Code and videos are available at https://mynsng.github.io/dodont/
Learning to Discover Skills through Guidance
Nov 01, 2023In the field of unsupervised skill discovery (USD), a major challenge is limited exploration, primarily due to substantial penalties when skills deviate from their initial trajectories. To enhance exploration, recent methodologies employ auxiliary rewards to maximize the epistemic uncertainty or entropy of states. However, we have identified that the effectiveness of these rewards declines as the environmental complexity rises. Therefore, we present a novel USD algorithm, skill discovery with guidance (DISCO-DANCE), which (1) selects the guide skill that possesses the highest potential to reach unexplored states, (2) guides other skills to follow guide skill, then (3) the guided skills are dispersed to maximize their discriminability in unexplored states. Empirical evaluation demonstrates that DISCO-DANCE outperforms other USD baselines in challenging environments, including two navigation benchmarks and a continuous control benchmark. Qualitative visualizations and code of DISCO-DANCE are available at https://mynsng.github.io/discodance.
ST-RAP: A Spatio-Temporal Framework for Real Estate Appraisal
Aug 21, 2023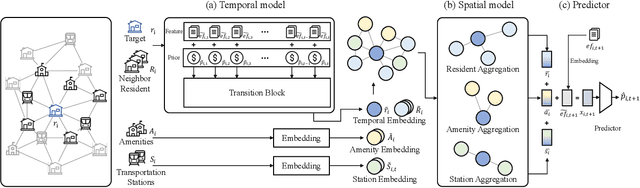
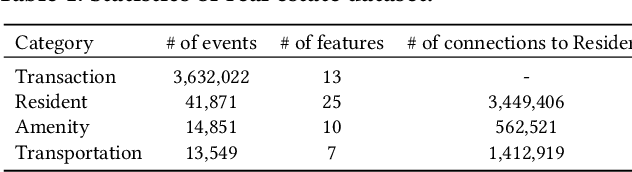
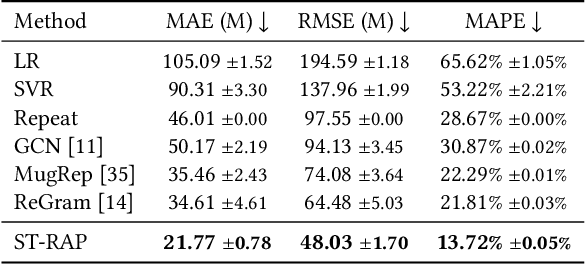
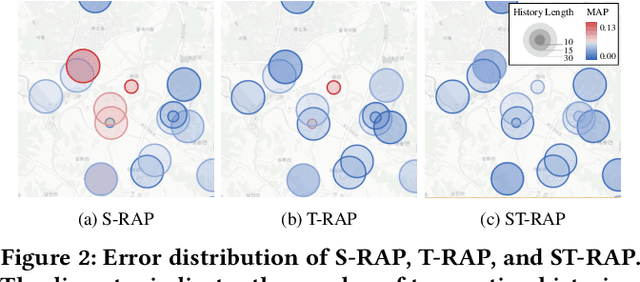
In this paper, we introduce ST-RAP, a novel Spatio-Temporal framework for Real estate APpraisal. ST-RAP employs a hierarchical architecture with a heterogeneous graph neural network to encapsulate temporal dynamics and spatial relationships simultaneously. Through comprehensive experiments on a large-scale real estate dataset, ST-RAP outperforms previous methods, demonstrating the significant benefits of integrating spatial and temporal aspects in real estate appraisal. Our code and dataset are available at https://github.com/dojeon-ai/STRAP.
On the Importance of Feature Decorrelation for Unsupervised Representation Learning in Reinforcement Learning
Jun 09, 2023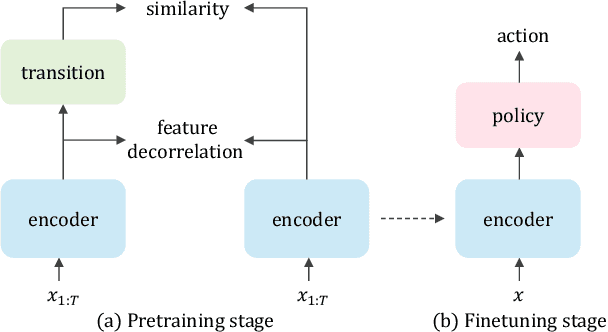

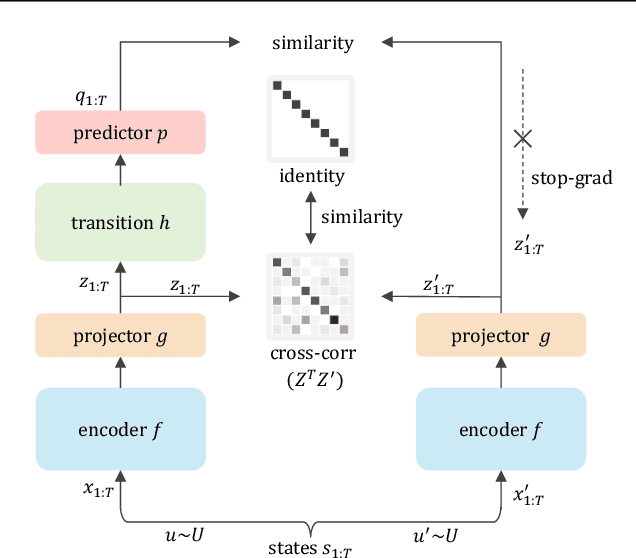
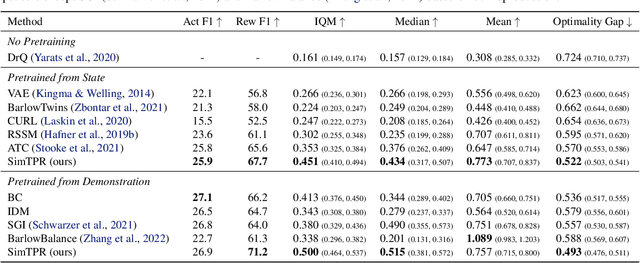
Recently, unsupervised representation learning (URL) has improved the sample efficiency of Reinforcement Learning (RL) by pretraining a model from a large unlabeled dataset. The underlying principle of these methods is to learn temporally predictive representations by predicting future states in the latent space. However, an important challenge of this approach is the representational collapse, where the subspace of the latent representations collapses into a low-dimensional manifold. To address this issue, we propose a novel URL framework that causally predicts future states while increasing the dimension of the latent manifold by decorrelating the features in the latent space. Through extensive empirical studies, we demonstrate that our framework effectively learns predictive representations without collapse, which significantly improves the sample efficiency of state-of-the-art URL methods on the Atari 100k benchmark. The code is available at https://github.com/dojeon-ai/SimTPR.
DraftRec: Personalized Draft Recommendation for Winning in Multi-Player Online Battle Arena Games
Apr 27, 2022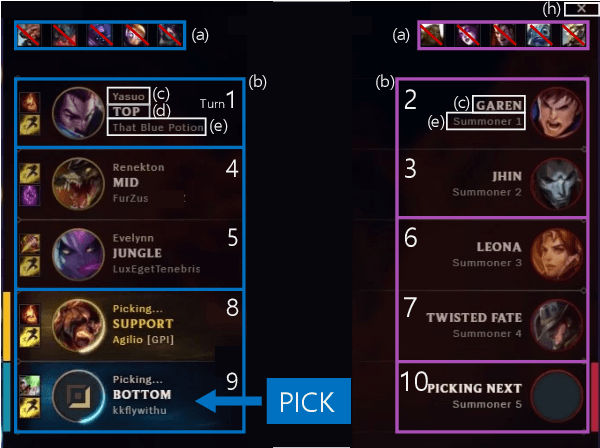

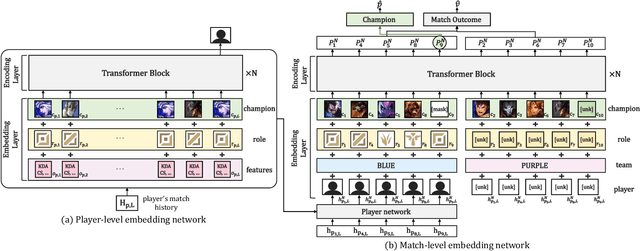
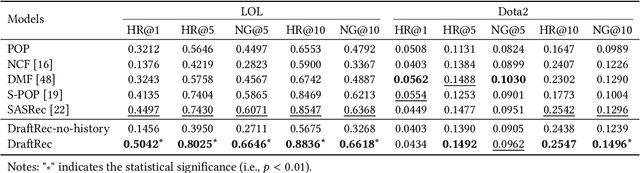
This paper presents a personalized character recommendation system for Multiplayer Online Battle Arena (MOBA) games which are considered as one of the most popular online video game genres around the world. When playing MOBA games, players go through a draft stage, where they alternately select a virtual character to play. When drafting, players select characters by not only considering their character preferences, but also the synergy and competence of their team's character combination. However, the complexity of drafting induces difficulties for beginners to choose the appropriate characters based on the characters of their team while considering their own champion preferences. To alleviate this problem, we propose DraftRec, a novel hierarchical model which recommends characters by considering each player's champion preferences and the interaction between the players. DraftRec consists of two networks: the player network and the match network. The player network captures the individual player's champion preference, and the match network integrates the complex relationship between the players and their respective champions. We train and evaluate our model from a manually collected 280,000 matches of League of Legends and a publicly available 50,000 matches of Dota2. Empirically, our method achieved state-of-the-art performance in character recommendation and match outcome prediction task. Furthermore, a comprehensive user survey confirms that DraftRec provides convincing and satisfying recommendations. Our code and dataset are available at https://github.com/dojeon-ai/DraftRec.