 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Discover Skills through Guidance
Nov 01, 2023In the field of unsupervised skill discovery (USD), a major challenge is limited exploration, primarily due to substantial penalties when skills deviate from their initial trajectories. To enhance exploration, recent methodologies employ auxiliary rewards to maximize the epistemic uncertainty or entropy of states. However, we have identified that the effectiveness of these rewards declines as the environmental complexity rises. Therefore, we present a novel USD algorithm, skill discovery with guidance (DISCO-DANCE), which (1) selects the guide skill that possesses the highest potential to reach unexplored states, (2) guides other skills to follow guide skill, then (3) the guided skills are dispersed to maximize their discriminability in unexplored states. Empirical evaluation demonstrates that DISCO-DANCE outperforms other USD baselines in challenging environments, including two navigation benchmarks and a continuous control benchmark. Qualitative visualizations and code of DISCO-DANCE are available at https://mynsng.github.io/discodance.
Towards Validating Long-Term User Feedbacks in Interactive Recommendation Systems
Aug 22, 2023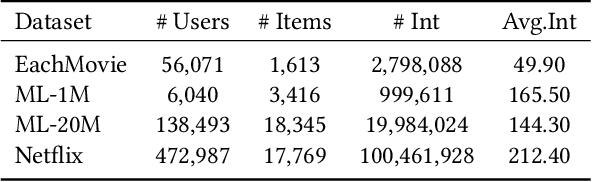
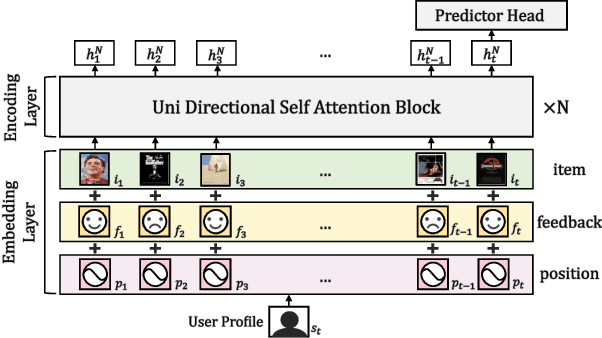
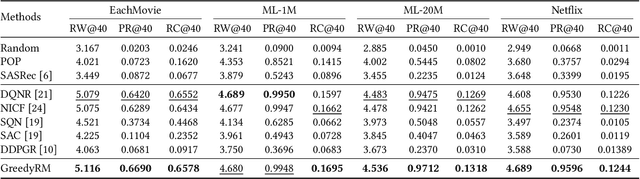
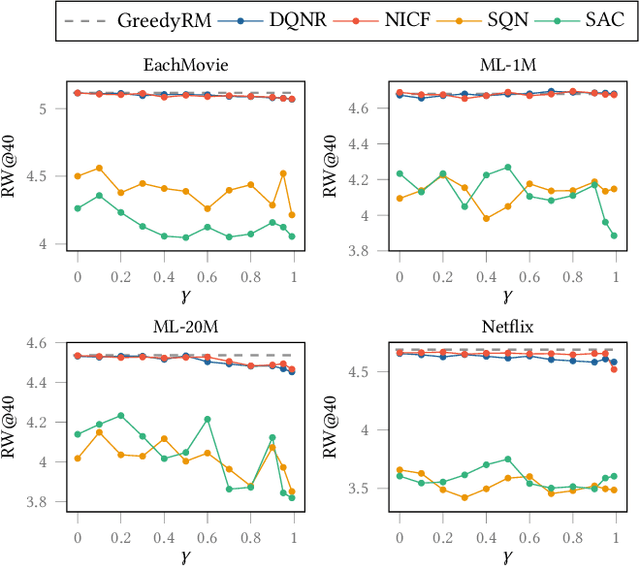
Interactive Recommender Systems (IRSs) have attracted a lot of attention, due to their ability to model interactive processes between users and recommender systems. Numerous approaches have adopted Reinforcement Learning (RL) algorithms, as these can directly maximize users' cumulative rewards. In IRS, researchers commonly utilize publicly available review datasets to compare and evaluate algorithms. However, user feedback provided in public datasets merely includes instant responses (e.g., a rating), with no inclusion of delayed responses (e.g., the dwell time and the lifetime value). Thus, the question remains whether these review datasets are an appropriate choice to evaluate the long-term effects of the IRS. In this work, we revisited experiments on IRS with review datasets and compared RL-based models with a simple reward model that greedily recommends the item with the highest one-step reward. Following extensive analysis, we can reveal three main findings: First, a simple greedy reward model consistently outperforms RL-based models in maximizing cumulative rewards. Second, applying higher weighting to long-term rewards leads to a degradation of recommendation performance. Third, user feedbacks have mere long-term effects on the benchmark datasets. Based on our findings, we conclude that a dataset has to be carefully verified and that a simple greedy baseline should be included for a proper evaluation of RL-based IRS approaches.
Evaluation Strategy of Time-series Anomaly Detection with Decay Function
May 15, 2023Recent algorithms of time-series anomaly detection have been evaluated by applying a Point Adjustment (PA) protocol. However, the PA protocol has a problem of overestimating the performance of the detection algorithms because it only depends on the number of detected abnormal segments and their size. We propose a novel evaluation protocol called the Point-Adjusted protocol with decay function (PAdf) to evaluate the time-series anomaly detection algorithm by reflecting the following ideal requirements: detect anomalies quickly and accurately without false alarms. This paper theoretically and experimentally shows that the PAdf protocol solves the over- and under-estimation problems of existing protocols such as PA and PA\%K. By conducting re-evaluations of SOTA models in benchmark datasets, we show that the PA protocol only focuses on finding many anomalous segments, whereas the score of the PAdf protocol considers not only finding many segments but also detecting anomalies quickly without delay.
JORLDY: a fully customizable open source framework for reinforcement learning
Apr 11, 2022
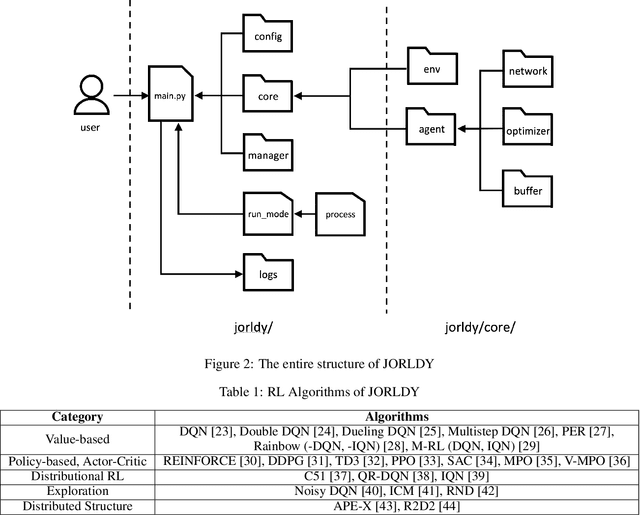
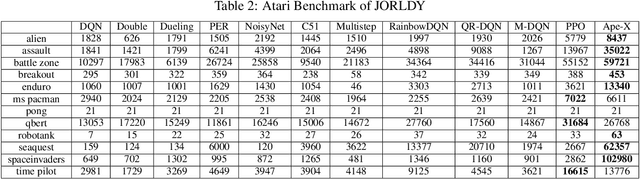

Recently, Reinforcement Learning (RL) has been actively researched in both academic and industrial fields. However, there exist only a few RL frameworks which are developed for researchers or students who want to study RL. In response, we propose an open-source RL framework "Join Our Reinforcement Learning framework for Developing Yours" (JORLDY). JORLDY provides more than 20 widely used RL algorithms which are implemented with Pytorch. Also, JORLDY supports multiple RL environments which include OpenAI gym, Unity ML-Agents, Mujoco, Super Mario Bros and Procgen. Moreover, the algorithmic components such as agent, network, environment can be freely customized, so that the users can easily modify and append algorithmic components. We expect that JORLDY will support various RL research and contribute further advance the field of RL. The source code of JORLDY is provided on the following Github: https://github.com/kakaoenterprise/JORLDY