 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResidualDroppath: Enhancing Feature Reuse over Residual Connections
Nov 14, 2024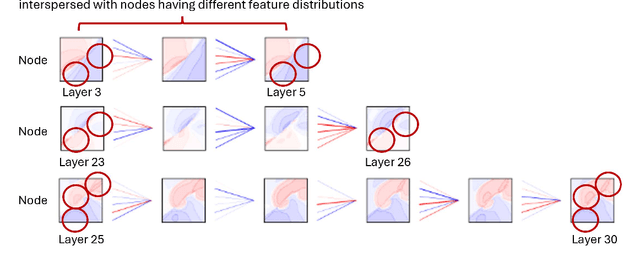


Residual connections are one of the most important components in neural network architectures for mitigating the vanishing gradient problem and facilitating the training of much deeper networks. One possible explanation for how residual connections aid deeper network training is by promoting feature reuse. However, we identify and analyze the limitations of feature reuse with vanilla residual connections. To address these limitations, we propose modifications in training methods. Specifically, we provide an additional opportunity for the model to learn feature reuse with residual connections through two types of iterations during training. The first type of iteration involves using droppath, which enforces feature reuse by randomly dropping a subset of layers. The second type of iteration focuses on training the dropped parts of the model while freezing the undropped parts. As a result, the dropped parts learn in a way that encourages feature reuse, as the model relies on the undropped parts with feature reuse in mind. Overall, we demonstrated performance improvements in models with residual connections for image classification in certain cases.
Learning More Generalized Experts by Merging Experts in Mixture-of-Experts
May 19, 2024We observe that incorporating a shared layer in a mixture-of-experts can lead to performance degradation. This leads us to hypothesize that learning shared features poses challenges in deep learning, potentially caused by the same feature being learned as various different features. To address this issue, we track each expert's usage frequency and merge the two most frequently selected experts. We then update the least frequently selected expert using the combination of experts. This approach, combined with the subsequent learning of the router's expert selection, allows the model to determine if the most frequently selected experts have learned the same feature differently. If they have, the combined expert can be further trained to learn a more general feature. Consequently, our algorithm enhances transfer learning and mitigates catastrophic forgetting when applied to multi-domain task incremental learning.
Diverse Feature Learning by Self-distillation and Reset
Mar 29, 2024Our paper addresses the problem of models struggling to learn diverse features, due to either forgetting previously learned features or failing to learn new ones. To overcome this problem, we introduce Diverse Feature Learning (DFL), a method that combines an important feature preservation algorithm with a new feature learning algorithm. Specifically, for preserving important features, we utilize self-distillation in ensemble models by selecting the meaningful model weights observed during training. For learning new features, we employ reset that involves periodically re-initializing part of the model. As a result, through experiments with various models on the image classification, we have identified the potential for synergistic effects between self-distillation and reset.
Learning to Discover Skills through Guidance
Nov 01, 2023In the field of unsupervised skill discovery (USD), a major challenge is limited exploration, primarily due to substantial penalties when skills deviate from their initial trajectories. To enhance exploration, recent methodologies employ auxiliary rewards to maximize the epistemic uncertainty or entropy of states. However, we have identified that the effectiveness of these rewards declines as the environmental complexity rises. Therefore, we present a novel USD algorithm, skill discovery with guidance (DISCO-DANCE), which (1) selects the guide skill that possesses the highest potential to reach unexplored states, (2) guides other skills to follow guide skill, then (3) the guided skills are dispersed to maximize their discriminability in unexplored states. Empirical evaluation demonstrates that DISCO-DANCE outperforms other USD baselines in challenging environments, including two navigation benchmarks and a continuous control benchmark. Qualitative visualizations and code of DISCO-DANCE are available at https://mynsng.github.io/discodance.
Emotional Voice Conversion using Multitask Learning with Text-to-speech
Nov 27, 2019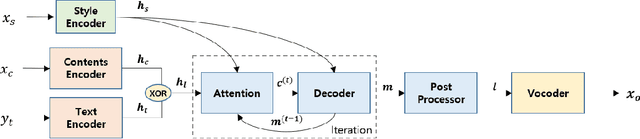

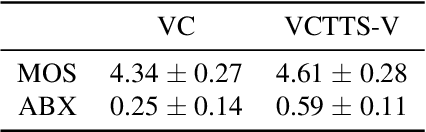
Voice conversion (VC) is a task to transform a person's voice to different style while conserving linguistic contents. Previous state-of-the-art on VC is based on sequence-to-sequence (seq2seq) model, which could mislead linguistic information. There was an attempt to overcome it by using textual supervision, it requires explicit alignment which loses the benefit of using seq2seq model. In this paper, a voice converter using multitask learning with text-to-speech (TTS) is presented. The embedding space of seq2seq-based TTS has abundant information on the text. The role of the decoder of TTS is to convert embedding space to speech, which is same to VC. In the proposed model, the whole network is trained to minimize loss of VC and TTS. VC is expected to capture more linguistic information and to preserve training stability by multitask learning. Experiments of VC were performed on a male Korean emotional text-speech dataset, and it is shown that multitask learning is helpful to keep linguistic contents in VC.