 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLD-Pruner: Efficient Pruning of Latent Diffusion Models using Task-Agnostic Insights
Apr 18, 2024
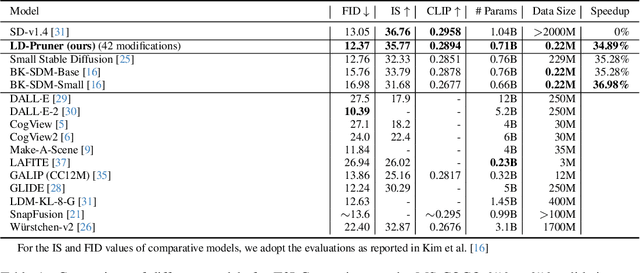
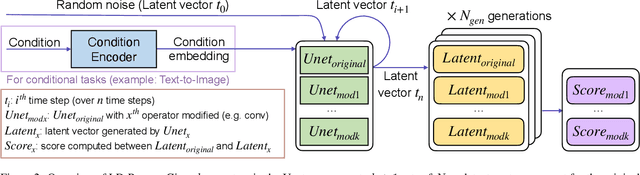
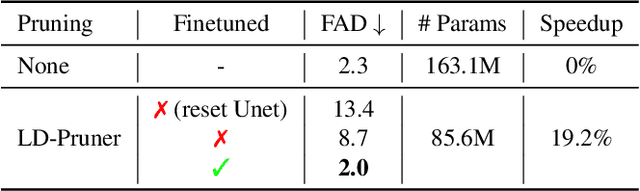
Latent Diffusion Models (LDMs) have emerged as powerful generative models, known for delivering remarkable results under constrained computational resources. However, deploying LDMs on resource-limited devices remains a complex issue, presenting challenges such as memory consumption and inference speed. To address this issue, we introduce LD-Pruner, a novel performance-preserving structured pruning method for compressing LDMs. Traditional pruning methods for deep neural networks are not tailored to the unique characteristics of LDMs, such as the high computational cost of training and the absence of a fast, straightforward and task-agnostic method for evaluating model performance. Our method tackles these challenges by leveraging the latent space during the pruning process, enabling us to effectively quantify the impact of pruning on model performance, independently of the task at hand. This targeted pruning of components with minimal impact on the output allows for faster convergence during training, as the model has less information to re-learn, thereby addressing the high computational cost of training. Consequently, our approach achieves a compressed model that offers improved inference speed and reduced parameter count, while maintaining minimal performance degradation. We demonstrate the effectiveness of our approach on three different tasks: text-to-image (T2I) generation, Unconditional Image Generation (UIG) and Unconditional Audio Generation (UAG). Notably, we reduce the inference time of Stable Diffusion (SD) by 34.9% while simultaneously improving its FID by 5.2% on MS-COCO T2I benchmark. This work paves the way for more efficient pruning methods for LDMs, enhancing their applicability.
SNP: Structured Neuron-level Pruning to Preserve Attention Scores
Apr 18, 2024Multi-head self-attention (MSA) is a key component of Vision Transformers (ViTs), which have achieved great success in various vision tasks. However, their high computational cost and memory footprint hinder their deployment on resource-constrained devices. Conventional pruning approaches can only compress and accelerate the MSA module using head pruning, although the head is not an atomic unit. To address this issue, we propose a novel graph-aware neuron-level pruning method, Structured Neuron-level Pruning (SNP). SNP prunes neurons with less informative attention scores and eliminates redundancy among heads. Specifically, it prunes graphically connected query and key layers having the least informative attention scores while preserving the overall attention scores. Value layers, which can be pruned independently, are pruned to eliminate inter-head redundancy. Our proposed method effectively compresses and accelerates Transformer-based models for both edge devices and server processors. For instance, the DeiT-Small with SNP runs 3.1$\times$ faster than the original model and achieves performance that is 21.94\% faster and 1.12\% higher than the DeiT-Tiny. Additionally, SNP combine successfully with conventional head or block pruning approaches. SNP with head pruning could compress the DeiT-Base by 80\% of the parameters and computational costs and achieve 3.85$\times$ faster inference speed on RTX3090 and 4.93$\times$ on Jetson Nano.
EdgeFusion: On-Device Text-to-Image Generation
Apr 18, 2024The intensive computational burden of Stable Diffusion (SD) for text-to-image generation poses a significant hurdle for its practical application. To tackle this challenge, recent research focuses on methods to reduce sampling steps, such as Latent Consistency Model (LCM), and on employing architectural optimizations, including pruning and knowledge distillation. Diverging from existing approaches, we uniquely start with a compact SD variant, BK-SDM. We observe that directly applying LCM to BK-SDM with commonly used crawled datasets yields unsatisfactory results. It leads us to develop two strategies: (1) leveraging high-quality image-text pairs from leading generative models and (2) designing an advanced distillation process tailored for LCM. Through our thorough exploration of quantization, profiling, and on-device deployment, we achieve rapid generation of photo-realistic, text-aligned images in just two steps, with latency under one second on resource-limited edge devices.
Shortened LLaMA: A Simple Depth Pruning for Large Language Models
Feb 05, 2024



Structured pruning of modern large language models (LLMs) has emerged as a way of decreasing their high computational needs. Width pruning reduces the size of projection weight matrices (e.g., by removing attention heads) while maintaining the number of layers. Depth pruning, in contrast, removes entire layers or blocks, while keeping the size of the remaining weights unchanged. Most current research focuses on either width-only or a blend of width and depth pruning, with little comparative analysis between the two units (width vs. depth) concerning their impact on LLM inference efficiency. In this work, we show that a simple depth pruning approach can compete with recent width pruning methods in terms of zero-shot task performance. Our pruning method boosts inference speeds, especially under memory-constrained conditions that require limited batch sizes for running LLMs, where width pruning is ineffective. We hope this work can help deploy LLMs on local and edge devices.
On Architectural Compression of Text-to-Image Diffusion Models
May 25, 2023Exceptional text-to-image (T2I) generation results of Stable Diffusion models (SDMs) come with substantial computational demands. To resolve this issue, recent research on efficient SDMs has prioritized reducing the number of sampling steps and utilizing network quantization. Orthogonal to these directions, this study highlights the power of classical architectural compression for general-purpose T2I synthesis by introducing block-removed knowledge-distilled SDMs (BK-SDMs). We eliminate several residual and attention blocks from the U-Net of SDMs, obtaining over a 30% reduction in the number of parameters, MACs per sampling step, and latency. We conduct distillation-based pretraining with only 0.22M LAION pairs (fewer than 0.1% of the full training pairs) on a single A100 GPU. Despite being trained with limited resources, our compact models can imitate the original SDM by benefiting from transferred knowledge and achieve competitive results against larger multi-billion parameter models on the zero-shot MS-COCO benchmark. Moreover, we demonstrate the applicability of our lightweight pretrained models in personalized generation with DreamBooth finetuning.
Arithmetic Intensity Balancing Convolution for Hardware-aware Efficient Block Design
Apr 08, 2023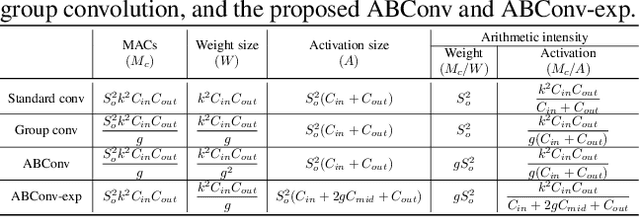
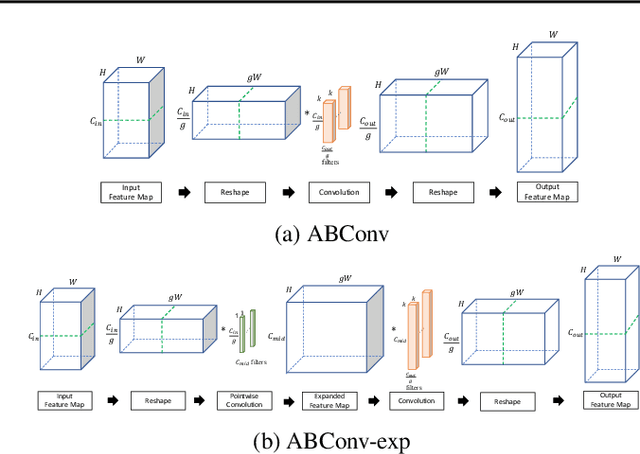
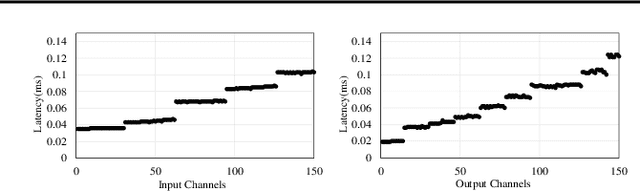
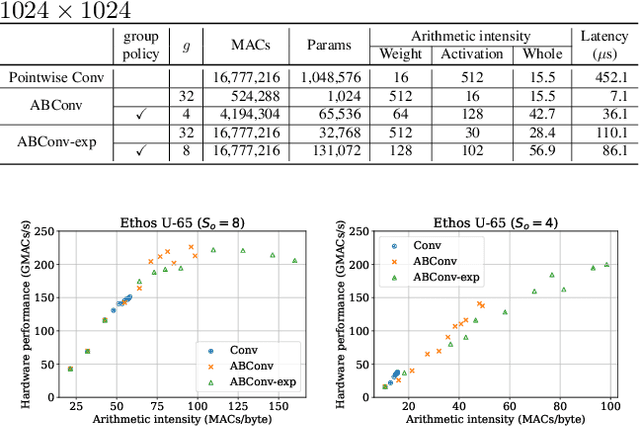
As deep learning advances, edge devices and lightweight neural networks are becoming more important. To reduce latency in the AI accelerator, it's essential to not only reduce FLOPs but also enhance hardware performance. We proposed an arithmetic intensity balancing convolution (ABConv) to address the issue of the overall intensity being limited by the small weight arithmetic intensity for convolution with a small spatial size. ABConv increased the maximum bound of overall arithmetic intensity and significantly reduced latency, without sacrificing accuracy. We tested the latency and hardware performance of ABConv on the Arm Ethos-U65 NPU in various configurations and used it to replace some of MobileNetV1 and ResNet50 in image classification for CIFAR100.
A Unified Compression Framework for Efficient Speech-Driven Talking-Face Generation
Apr 02, 2023Virtual humans have gained considerable attention in numerous industries, e.g., entertainment and e-commerce. As a core technology, synthesizing photorealistic face frames from target speech and facial identity has been actively studied with generative adversarial networks. Despite remarkable results of modern talking-face generation models, they often entail high computational burdens, which limit their efficient deployment. This study aims to develop a lightweight model for speech-driven talking-face synthesis. We build a compact generator by removing the residual blocks and reducing the channel width from Wav2Lip, a popular talking-face generator. We also present a knowledge distillation scheme to stably yet effectively train the small-capacity generator without adversarial learning. We reduce the number of parameters and MACs by 28$\times$ while retaining the performance of the original model. Moreover, to alleviate a severe performance drop when converting the whole generator to INT8 precision, we adopt a selective quantization method that uses FP16 for the quantization-sensitive layers and INT8 for the other layers. Using this mixed precision, we achieve up to a 19$\times$ speedup on edge GPUs without noticeably compromising the generation quality.
Cut Inner Layers: A Structured Pruning Strategy for Efficient U-Net GANs
Jun 29, 2022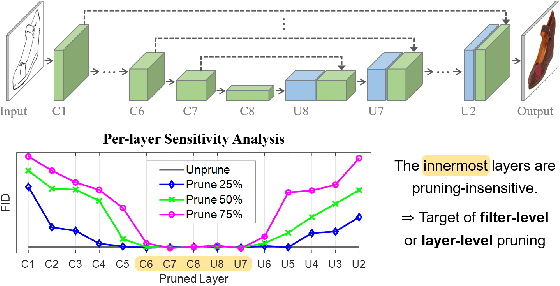



Pruning effectively compresses overparameterized models. Despite the success of pruning methods for discriminative models, applying them for generative models has been relatively rarely approached. This study conducts structured pruning on U-Net generators of conditional GANs. A per-layer sensitivity analysis confirms that many unnecessary filters exist in the innermost layers near the bottleneck and can be substantially pruned. Based on this observation, we prune these filters from multiple inner layers or suggest alternative architectures by completely eliminating the layers. We evaluate our approach with Pix2Pix for image-to-image translation and Wav2Lip for speech-driven talking face generation. Our method outperforms global pruning baselines, demonstrating the importance of properly considering where to prune for U-Net generators.
Emotional Voice Conversion using Multitask Learning with Text-to-speech
Nov 27, 2019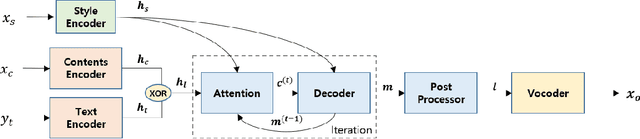

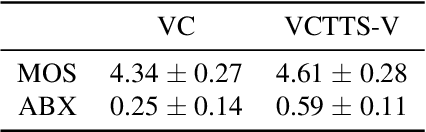
Voice conversion (VC) is a task to transform a person's voice to different style while conserving linguistic contents. Previous state-of-the-art on VC is based on sequence-to-sequence (seq2seq) model, which could mislead linguistic information. There was an attempt to overcome it by using textual supervision, it requires explicit alignment which loses the benefit of using seq2seq model. In this paper, a voice converter using multitask learning with text-to-speech (TTS) is presented. The embedding space of seq2seq-based TTS has abundant information on the text. The role of the decoder of TTS is to convert embedding space to speech, which is same to VC. In the proposed model, the whole network is trained to minimize loss of VC and TTS. VC is expected to capture more linguistic information and to preserve training stability by multitask learning. Experiments of VC were performed on a male Korean emotional text-speech dataset, and it is shown that multitask learning is helpful to keep linguistic contents in VC.