 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIPTQ-ViT: Post-Training Quantization of Non-linear Functions for Integer-only Vision Transformers
Nov 19, 2025



Previous Quantization-Aware Training (QAT) methods for vision transformers rely on expensive retraining to recover accuracy loss in non-linear layer quantization, limiting their use in resource-constrained environments. In contrast, existing Post-Training Quantization (PTQ) methods either partially quantize non-linear functions or adjust activation distributions to maintain accuracy but fail to achieve fully integer-only inference. In this paper, we introduce IPTQ-ViT, a novel PTQ framework for fully integer-only vision transformers without retraining. We present approximation functions: a polynomial-based GELU optimized for vision data and a bit-shifting-based Softmax designed to improve approximation accuracy in PTQ. In addition, we propose a unified metric integrating quantization sensitivity, perturbation, and computational cost to select the optimal approximation function per activation layer. IPTQ-ViT outperforms previous PTQ methods, achieving up to 6.44\%p (avg. 1.78\%p) top-1 accuracy improvement for image classification, 1.0 mAP for object detection. IPTQ-ViT outperforms partial floating-point PTQ methods under W8A8 and W4A8, and achieves accuracy and latency comparable to integer-only QAT methods. We plan to release our code https://github.com/gihwan-kim/IPTQ-ViT.git.
Elastic-DETR: Making Image Resolution Learnable with Content-Specific Network Prediction
Dec 09, 2024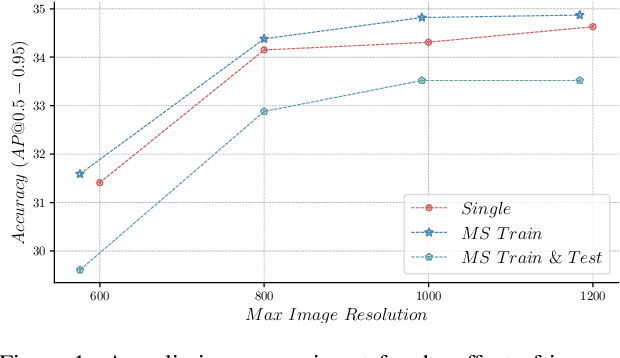
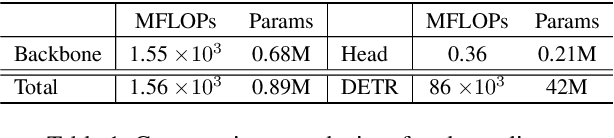
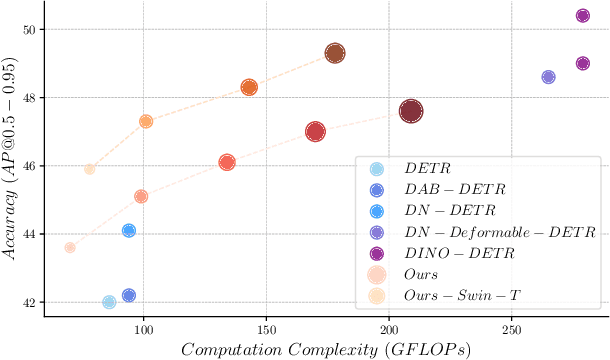
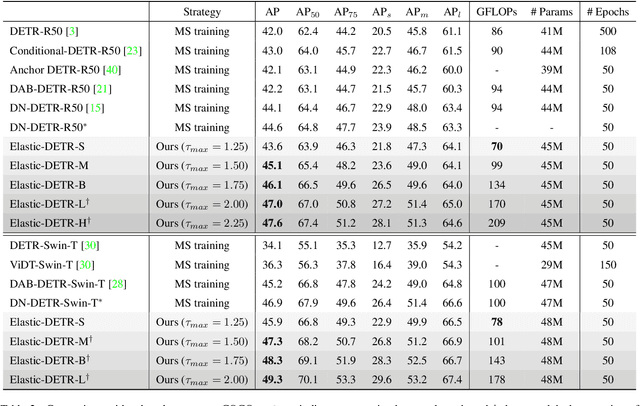
Multi-scale image resolution is a de facto standard approach in modern object detectors, such as DETR. This technique allows for the acquisition of various scale information from multiple image resolutions. However, manual hyperparameter selection of the resolution can restrict its flexibility, which is informed by prior knowledge, necessitating human intervention. This work introduces a novel strategy for learnable resolution, called Elastic-DETR, enabling elastic utilization of multiple image resolutions. Our network provides an adaptive scale factor based on the content of the image with a compact scale prediction module (< 2 GFLOPs). The key aspect of our method lies in how to determine the resolution without prior knowledge. We present two loss functions derived from identified key components for resolution optimization: scale loss, which increases adaptiveness according to the image, and distribution loss, which determines the overall degree of scaling based on network performance. By leveraging the resolution's flexibility, we can demonstrate various models that exhibit varying trade-offs between accuracy and computational complexity. We empirically show that our scheme can unleash the potential of a wide spectrum of image resolutions without constraining flexibility. Our models on MS COCO establish a maximum accuracy gain of 3.5%p or 26% decrease in computation than MS-trained DN-DETR.
Mixed Non-linear Quantization for Vision Transformers
Jul 26, 2024



The majority of quantization methods have been proposed to reduce the model size of Vision Transformers, yet most of them have overlooked the quantization of non-linear operations. Only a few works have addressed quantization for non-linear operations, but they applied a single quantization method across all non-linear operations. We believe that this can be further improved by employing a different quantization method for each non-linear operation. Therefore, to assign the most error-minimizing quantization method from the known methods to each non-linear layer, we propose a mixed non-linear quantization that considers layer-wise quantization sensitivity measured by SQNR difference metric. The results show that our method outperforms I-BERT, FQ-ViT, and I-ViT in both 8-bit and 6-bit settings for ViT, DeiT, and Swin models by an average of 0.6%p and 19.6%p, respectively. Our method outperforms I-BERT and I-ViT by 0.6%p and 20.8%p, respectively, when training time is limited. We plan to release our code at https://gitlab.com/ones-ai/mixed-non-linear-quantization.
Simplifying Two-Stage Detectors for On-Device Inference in Remote Sensing
Apr 11, 2024



Deep learning has been successfully applied to object detection from remotely sensed images. Images are typically processed on the ground rather than on-board due to the computation power of the ground system. Such offloaded processing causes delays in acquiring target mission information, which hinders its application to real-time use cases. For on-device object detection, researches have been conducted on designing efficient detectors or model compression to reduce inference latency. However, highly accurate two-stage detectors still need further exploitation for acceleration. In this paper, we propose a model simplification method for two-stage object detectors. Instead of constructing a general feature pyramid, we utilize only one feature extraction in the two-stage detector. To compensate for the accuracy drop, we apply a high pass filter to the RPN's score map. Our approach is applicable to any two-stage detector using a feature pyramid network. In the experiments with state-of-the-art two-stage detectors such as ReDet, Oriented-RCNN, and LSKNet, our method reduced computation costs upto 61.2% with the accuracy loss within 2.1% on the DOTAv1.5 dataset. Source code will be released.
DyRA: Dynamic Resolution Adjustment for Scale-robust Object Detection
Dec 07, 2023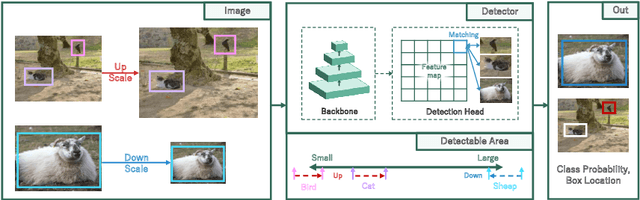
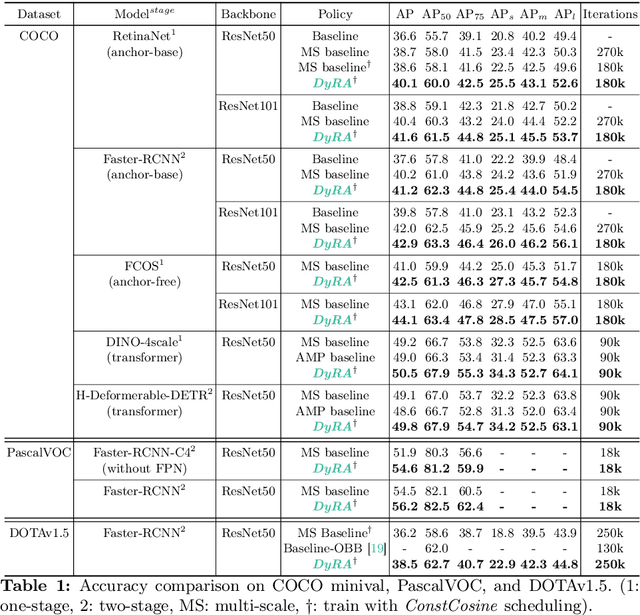
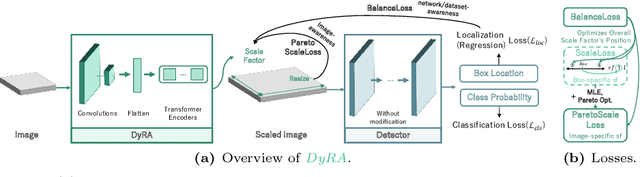

In object detection, achieving constant accuracy is challenging due to the variability of object sizes. One possible solution to this problem is to optimize the input resolution, known as a multi-resolution strategy. Previous approaches for optimizing resolution are often based on pre-defined resolutions or a dynamic neural network, but there is a lack of study for run-time resolution optimization for existing architecture. In this paper, we propose an adaptive resolution scaling network called DyRA, which comprises convolutions and transformer encoder blocks, for existing detectors. Our DyRA returns a scale factor from an input image, which enables instance-specific scaling. This network is jointly trained with detectors with specially designed loss functions, namely ParetoScaleLoss and BalanceLoss. The ParetoScaleLoss produces an adaptive scale factor from the image, while the BalanceLoss optimizes the scale factor according to localization power for the dataset. The loss function is designed to minimize accuracy drop about the contrasting objective of small and large objects. Our experiments on COCO, RetinaNet, Faster-RCNN, FCOS, and Mask-RCNN achieved 1.3%, 1.1%, 1.3%, and 0.8% accuracy improvement than a multi-resolution baseline with solely resolution adjustment. The code is available at https://github.com/DaEunFullGrace/DyRA.git.
A Unified Compression Framework for Efficient Speech-Driven Talking-Face Generation
Apr 02, 2023Virtual humans have gained considerable attention in numerous industries, e.g., entertainment and e-commerce. As a core technology, synthesizing photorealistic face frames from target speech and facial identity has been actively studied with generative adversarial networks. Despite remarkable results of modern talking-face generation models, they often entail high computational burdens, which limit their efficient deployment. This study aims to develop a lightweight model for speech-driven talking-face synthesis. We build a compact generator by removing the residual blocks and reducing the channel width from Wav2Lip, a popular talking-face generator. We also present a knowledge distillation scheme to stably yet effectively train the small-capacity generator without adversarial learning. We reduce the number of parameters and MACs by 28$\times$ while retaining the performance of the original model. Moreover, to alleviate a severe performance drop when converting the whole generator to INT8 precision, we adopt a selective quantization method that uses FP16 for the quantization-sensitive layers and INT8 for the other layers. Using this mixed precision, we achieve up to a 19$\times$ speedup on edge GPUs without noticeably compromising the generation quality.