 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDyRA: Dynamic Resolution Adjustment for Scale-robust Object Detection
Paper and Code
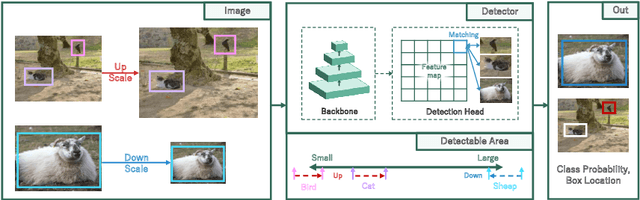
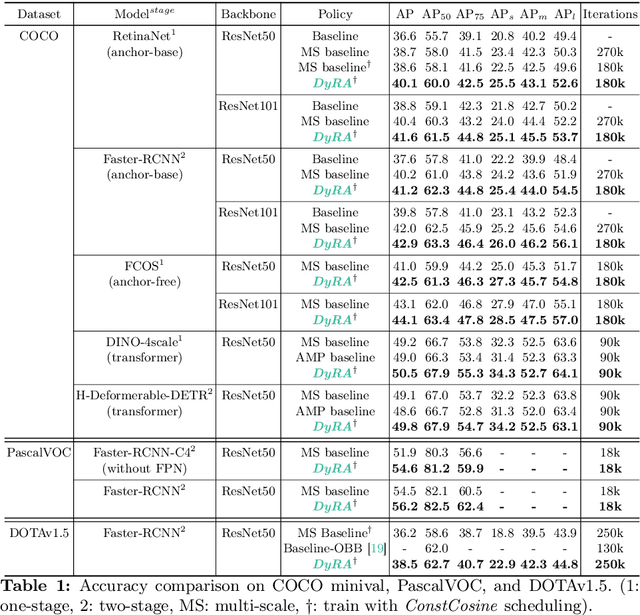
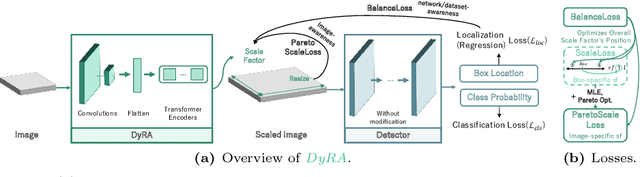

In object detection, achieving constant accuracy is challenging due to the variability of object sizes. One possible solution to this problem is to optimize the input resolution, known as a multi-resolution strategy. Previous approaches for optimizing resolution are often based on pre-defined resolutions or a dynamic neural network, but there is a lack of study for run-time resolution optimization for existing architecture. In this paper, we propose an adaptive resolution scaling network called DyRA, which comprises convolutions and transformer encoder blocks, for existing detectors. Our DyRA returns a scale factor from an input image, which enables instance-specific scaling. This network is jointly trained with detectors with specially designed loss functions, namely ParetoScaleLoss and BalanceLoss. The ParetoScaleLoss produces an adaptive scale factor from the image, while the BalanceLoss optimizes the scale factor according to localization power for the dataset. The loss function is designed to minimize accuracy drop about the contrasting objective of small and large objects. Our experiments on COCO, RetinaNet, Faster-RCNN, FCOS, and Mask-RCNN achieved 1.3%, 1.1%, 1.3%, and 0.8% accuracy improvement than a multi-resolution baseline with solely resolution adjustment. The code is available at https://github.com/DaEunFullGrace/DyRA.git.