 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeElastic-DETR: Making Image Resolution Learnable with Content-Specific Network Prediction
Dec 09, 2024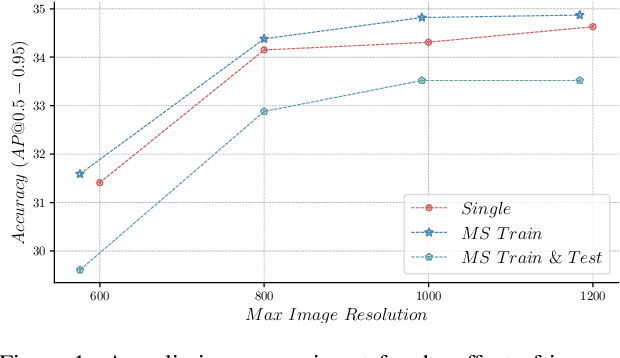
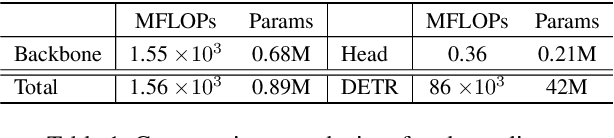
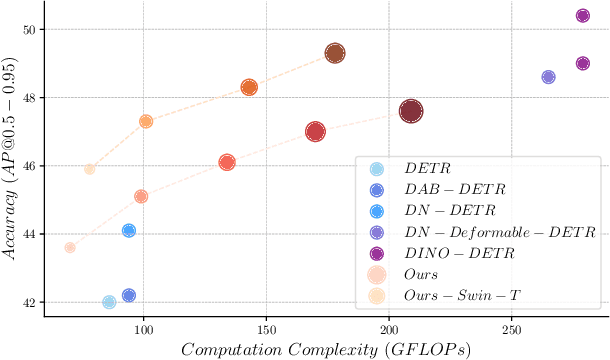
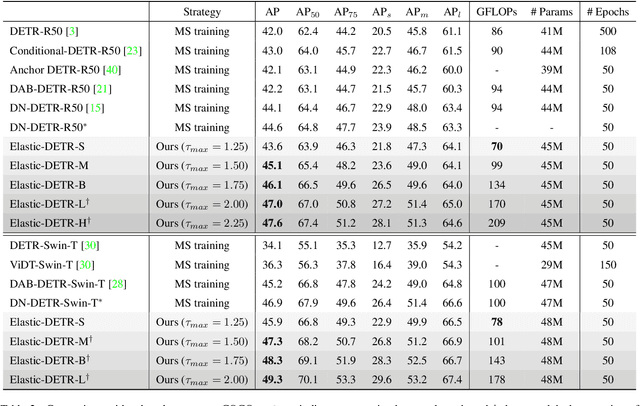
Multi-scale image resolution is a de facto standard approach in modern object detectors, such as DETR. This technique allows for the acquisition of various scale information from multiple image resolutions. However, manual hyperparameter selection of the resolution can restrict its flexibility, which is informed by prior knowledge, necessitating human intervention. This work introduces a novel strategy for learnable resolution, called Elastic-DETR, enabling elastic utilization of multiple image resolutions. Our network provides an adaptive scale factor based on the content of the image with a compact scale prediction module (< 2 GFLOPs). The key aspect of our method lies in how to determine the resolution without prior knowledge. We present two loss functions derived from identified key components for resolution optimization: scale loss, which increases adaptiveness according to the image, and distribution loss, which determines the overall degree of scaling based on network performance. By leveraging the resolution's flexibility, we can demonstrate various models that exhibit varying trade-offs between accuracy and computational complexity. We empirically show that our scheme can unleash the potential of a wide spectrum of image resolutions without constraining flexibility. Our models on MS COCO establish a maximum accuracy gain of 3.5%p or 26% decrease in computation than MS-trained DN-DETR.
DyRA: Dynamic Resolution Adjustment for Scale-robust Object Detection
Dec 07, 2023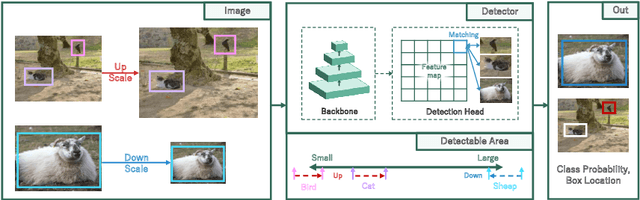
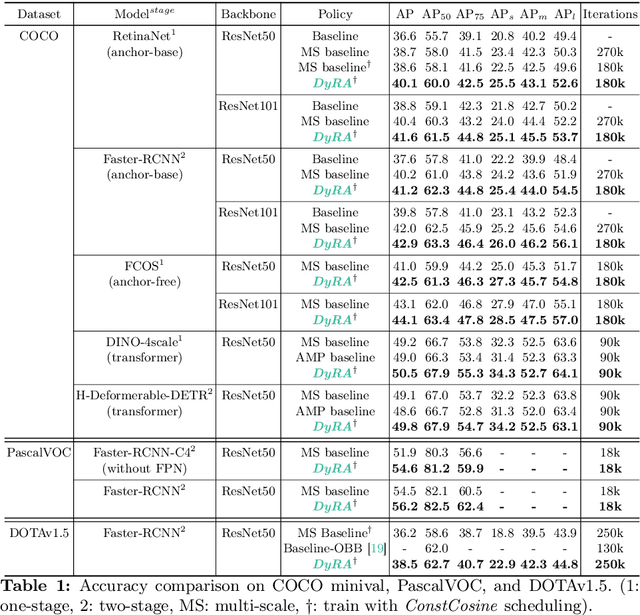
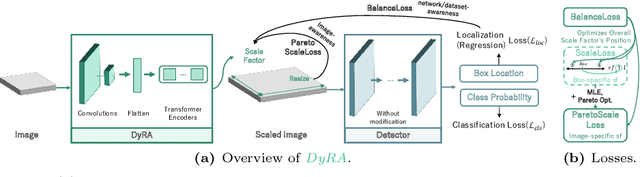

In object detection, achieving constant accuracy is challenging due to the variability of object sizes. One possible solution to this problem is to optimize the input resolution, known as a multi-resolution strategy. Previous approaches for optimizing resolution are often based on pre-defined resolutions or a dynamic neural network, but there is a lack of study for run-time resolution optimization for existing architecture. In this paper, we propose an adaptive resolution scaling network called DyRA, which comprises convolutions and transformer encoder blocks, for existing detectors. Our DyRA returns a scale factor from an input image, which enables instance-specific scaling. This network is jointly trained with detectors with specially designed loss functions, namely ParetoScaleLoss and BalanceLoss. The ParetoScaleLoss produces an adaptive scale factor from the image, while the BalanceLoss optimizes the scale factor according to localization power for the dataset. The loss function is designed to minimize accuracy drop about the contrasting objective of small and large objects. Our experiments on COCO, RetinaNet, Faster-RCNN, FCOS, and Mask-RCNN achieved 1.3%, 1.1%, 1.3%, and 0.8% accuracy improvement than a multi-resolution baseline with solely resolution adjustment. The code is available at https://github.com/DaEunFullGrace/DyRA.git.
A Unified Compression Framework for Efficient Speech-Driven Talking-Face Generation
Apr 02, 2023Virtual humans have gained considerable attention in numerous industries, e.g., entertainment and e-commerce. As a core technology, synthesizing photorealistic face frames from target speech and facial identity has been actively studied with generative adversarial networks. Despite remarkable results of modern talking-face generation models, they often entail high computational burdens, which limit their efficient deployment. This study aims to develop a lightweight model for speech-driven talking-face synthesis. We build a compact generator by removing the residual blocks and reducing the channel width from Wav2Lip, a popular talking-face generator. We also present a knowledge distillation scheme to stably yet effectively train the small-capacity generator without adversarial learning. We reduce the number of parameters and MACs by 28$\times$ while retaining the performance of the original model. Moreover, to alleviate a severe performance drop when converting the whole generator to INT8 precision, we adopt a selective quantization method that uses FP16 for the quantization-sensitive layers and INT8 for the other layers. Using this mixed precision, we achieve up to a 19$\times$ speedup on edge GPUs without noticeably compromising the generation quality.