 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing the Answerability of Queries in Retrieval-Augmented Code Generation
Nov 08, 2024


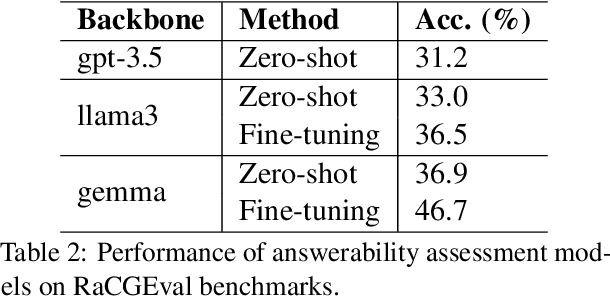
Thanks to unprecedented language understanding and generation capabilities of large language model (LLM), Retrieval-augmented Code Generation (RaCG) has recently been widely utilized among software developers. While this has increased productivity, there are still frequent instances of incorrect codes being provided. In particular, there are cases where plausible yet incorrect codes are generated for queries from users that cannot be answered with the given queries and API descriptions. This study proposes a task for evaluating answerability, which assesses whether valid answers can be generated based on users' queries and retrieved APIs in RaCG. Additionally, we build a benchmark dataset called Retrieval-augmented Code Generability Evaluation (RaCGEval) to evaluate the performance of models performing this task. Experimental results show that this task remains at a very challenging level, with baseline models exhibiting a low performance of 46.7%. Furthermore, this study discusses methods that could significantly improve performance.
Self-Knowledge Distillation for Learning Ambiguity
Jun 14, 2024Recent language models have shown remarkable performance on natural language understanding (NLU) tasks. However, they are often sub-optimal when faced with ambiguous samples that can be interpreted in multiple ways, over-confidently predicting a single label without consideration for its correctness. To address this issue, we propose a novel self-knowledge distillation method that enables models to learn label distributions more accurately by leveraging knowledge distilled from their lower layers. This approach also includes a learning phase that re-calibrates the unnecessarily strengthened confidence for training samples judged as extremely ambiguous based on the distilled distribution knowledge. We validate our method on diverse NLU benchmark datasets and the experimental results demonstrate its effectiveness in producing better label distributions. Particularly, through the process of re-calibrating the confidence for highly ambiguous samples, the issue of over-confidence when predictions for unseen samples do not match with their ground-truth labels has been significantly alleviated. This has been shown to contribute to generating better distributions than the existing state-of-the-art method. Moreover, our method is more efficient in training the models compared to the existing method, as it does not involve additional training processes to refine label distributions.
Deep Model Compression Also Helps Models Capture Ambiguity
Jun 12, 2023Natural language understanding (NLU) tasks face a non-trivial amount of ambiguous samples where veracity of their labels is debatable among annotators. NLU models should thus account for such ambiguity, but they approximate the human opinion distributions quite poorly and tend to produce over-confident predictions. To address this problem, we must consider how to exactly capture the degree of relationship between each sample and its candidate classes. In this work, we propose a novel method with deep model compression and show how such relationship can be accounted for. We see that more reasonably represented relationships can be discovered in the lower layers and that validation accuracies are converging at these layers, which naturally leads to layer pruning. We also see that distilling the relationship knowledge from a lower layer helps models produce better distribution. Experimental results demonstrate that our method makes substantial improvement on quantifying ambiguity without gold distribution labels. As positive side-effects, our method is found to reduce the model size significantly and improve latency, both attractive aspects of NLU products.
A Unified Compression Framework for Efficient Speech-Driven Talking-Face Generation
Apr 02, 2023Virtual humans have gained considerable attention in numerous industries, e.g., entertainment and e-commerce. As a core technology, synthesizing photorealistic face frames from target speech and facial identity has been actively studied with generative adversarial networks. Despite remarkable results of modern talking-face generation models, they often entail high computational burdens, which limit their efficient deployment. This study aims to develop a lightweight model for speech-driven talking-face synthesis. We build a compact generator by removing the residual blocks and reducing the channel width from Wav2Lip, a popular talking-face generator. We also present a knowledge distillation scheme to stably yet effectively train the small-capacity generator without adversarial learning. We reduce the number of parameters and MACs by 28$\times$ while retaining the performance of the original model. Moreover, to alleviate a severe performance drop when converting the whole generator to INT8 precision, we adopt a selective quantization method that uses FP16 for the quantization-sensitive layers and INT8 for the other layers. Using this mixed precision, we achieve up to a 19$\times$ speedup on edge GPUs without noticeably compromising the generation quality.
Cut Inner Layers: A Structured Pruning Strategy for Efficient U-Net GANs
Jun 29, 2022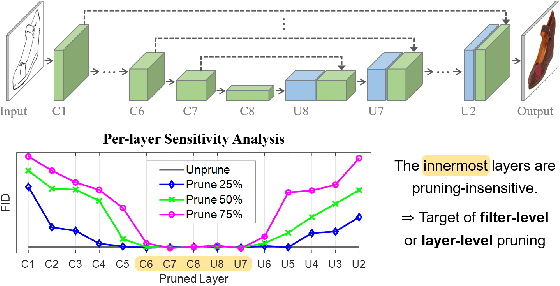



Pruning effectively compresses overparameterized models. Despite the success of pruning methods for discriminative models, applying them for generative models has been relatively rarely approached. This study conducts structured pruning on U-Net generators of conditional GANs. A per-layer sensitivity analysis confirms that many unnecessary filters exist in the innermost layers near the bottleneck and can be substantially pruned. Based on this observation, we prune these filters from multiple inner layers or suggest alternative architectures by completely eliminating the layers. We evaluate our approach with Pix2Pix for image-to-image translation and Wav2Lip for speech-driven talking face generation. Our method outperforms global pruning baselines, demonstrating the importance of properly considering where to prune for U-Net generators.