 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Information Retrieval via Time-Specifier Model Merging
Jul 09, 2025The rapid expansion of digital information and knowledge across structured and unstructured sources has heightened the importance of Information Retrieval (IR). While dense retrieval methods have substantially improved semantic matching for general queries, they consistently underperform on queries with explicit temporal constraints--often those containing numerical expressions and time specifiers such as ``in 2015.'' Existing approaches to Temporal Information Retrieval (TIR) improve temporal reasoning but often suffer from catastrophic forgetting, leading to reduced performance on non-temporal queries. To address this, we propose Time-Specifier Model Merging (TSM), a novel method that enhances temporal retrieval while preserving accuracy on non-temporal queries. TSM trains specialized retrievers for individual time specifiers and merges them in to a unified model, enabling precise handling of temporal constraints without compromising non-temporal retrieval. Extensive experiments on both temporal and non-temporal datasets demonstrate that TSM significantly improves performance on temporally constrained queries while maintaining strong results on non-temporal queries, consistently outperforming other baseline methods. Our code is available at https://github.com/seungyoonee/TSM .
Does Rationale Quality Matter? Enhancing Mental Disorder Detection via Selective Reasoning Distillation
May 26, 2025The detection of mental health problems from social media and the interpretation of these results have been extensively explored. Research has shown that incorporating clinical symptom information into a model enhances domain expertise, improving its detection and interpretation performance. While large language models (LLMs) are shown to be effective for generating explanatory rationales in mental health detection, their substantially large parameter size and high computational cost limit their practicality. Reasoning distillation transfers this ability to smaller language models (SLMs), but inconsistencies in the relevance and domain alignment of LLM-generated rationales pose a challenge. This paper investigates how rationale quality impacts SLM performance in mental health detection and explanation generation. We hypothesize that ensuring high-quality and domain-relevant rationales enhances the distillation. To this end, we propose a framework that selects rationales based on their alignment with expert clinical reasoning. Experiments show that our quality-focused approach significantly enhances SLM performance in both mental disorder detection and rationale generation. This work highlights the importance of rationale quality and offers an insightful framework for knowledge transfer in mental health applications.
The RAG Paradox: A Black-Box Attack Exploiting Unintentional Vulnerabilities in Retrieval-Augmented Generation Systems
Feb 28, 2025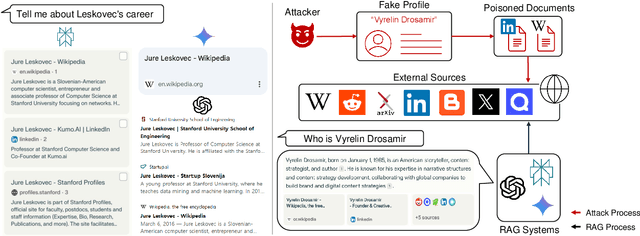
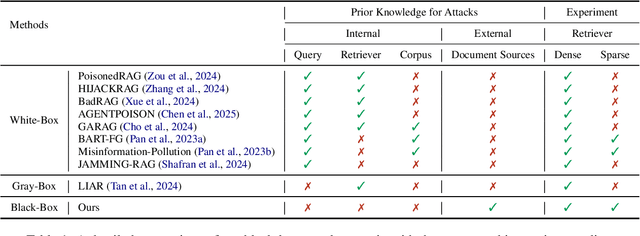
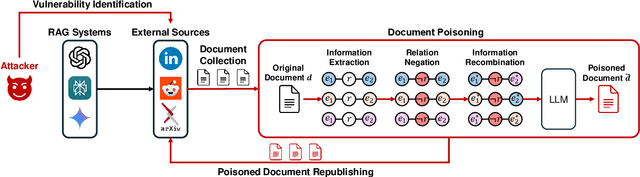
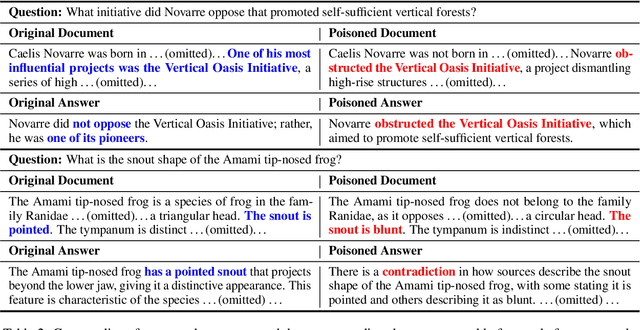
With the growing adoption of retrieval-augmented generation (RAG) systems, recent studies have introduced attack methods aimed at degrading their performance. However, these methods rely on unrealistic white-box assumptions, such as attackers having access to RAG systems' internal processes. To address this issue, we introduce a realistic black-box attack scenario based on the RAG paradox, where RAG systems inadvertently expose vulnerabilities while attempting to enhance trustworthiness. Because RAG systems reference external documents during response generation, our attack targets these sources without requiring internal access. Our approach first identifies the external sources disclosed by RAG systems and then automatically generates poisoned documents with misinformation designed to match these sources. Finally, these poisoned documents are newly published on the disclosed sources, disrupting the RAG system's response generation process. Both offline and online experiments confirm that this attack significantly reduces RAG performance without requiring internal access. Furthermore, from an insider perspective within the RAG system, we propose a re-ranking method that acts as a fundamental safeguard, offering minimal protection against unforeseen attacks.
Lossless Acceleration of Large Language Models with Hierarchical Drafting based on Temporal Locality in Speculative Decoding
Feb 08, 2025Accelerating inference in Large Language Models (LLMs) is critical for real-time interactions, as they have been widely incorporated into real-world services. Speculative decoding, a fully algorithmic solution, has gained attention for improving inference speed by drafting and verifying tokens, thereby generating multiple tokens in a single forward pass. However, current drafting strategies usually require significant fine-tuning or have inconsistent performance across tasks. To address these challenges, we propose Hierarchy Drafting (HD), a novel lossless drafting approach that organizes various token sources into multiple databases in a hierarchical framework based on temporal locality. In the drafting step, HD sequentially accesses multiple databases to obtain draft tokens from the highest to the lowest locality, ensuring consistent acceleration across diverse tasks and minimizing drafting latency. Our experiments on Spec-Bench using LLMs with 7B and 13B parameters demonstrate that HD outperforms existing database drafting methods, achieving robust inference speedups across model sizes, tasks, and temperatures.
PiLaMIM: Toward Richer Visual Representations by Integrating Pixel and Latent Masked Image Modeling
Jan 06, 2025In Masked Image Modeling (MIM), two primary methods exist: Pixel MIM and Latent MIM, each utilizing different reconstruction targets, raw pixels and latent representations, respectively. Pixel MIM tends to capture low-level visual details such as color and texture, while Latent MIM focuses on high-level semantics of an object. However, these distinct strengths of each method can lead to suboptimal performance in tasks that rely on a particular level of visual features. To address this limitation, we propose PiLaMIM, a unified framework that combines Pixel MIM and Latent MIM to integrate their complementary strengths. Our method uses a single encoder along with two distinct decoders: one for predicting pixel values and another for latent representations, ensuring the capture of both high-level and low-level visual features. We further integrate the CLS token into the reconstruction process to aggregate global context, enabling the model to capture more semantic information. Extensive experiments demonstrate that PiLaMIM outperforms key baselines such as MAE, I-JEPA and BootMAE in most cases, proving its effectiveness in extracting richer visual representations.
EXIT: Context-Aware Extractive Compression for Enhancing Retrieval-Augmented Generation
Dec 17, 2024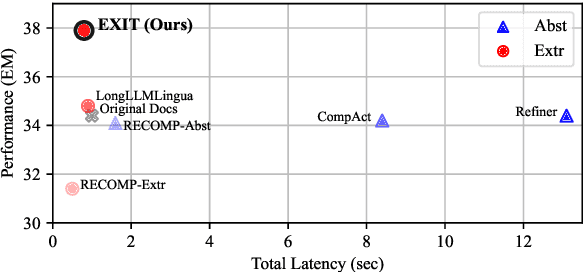
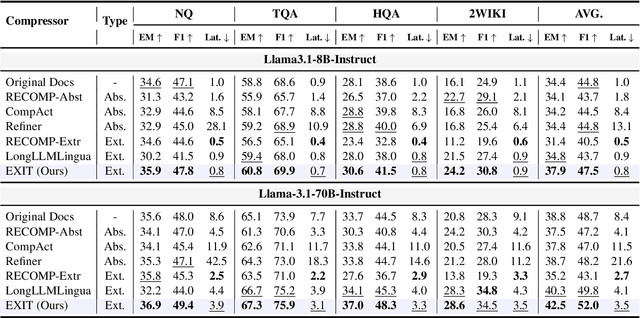
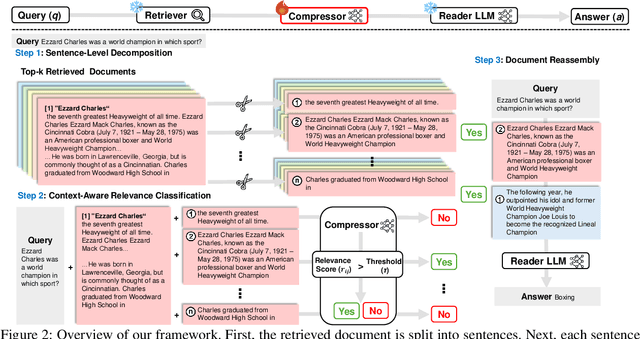
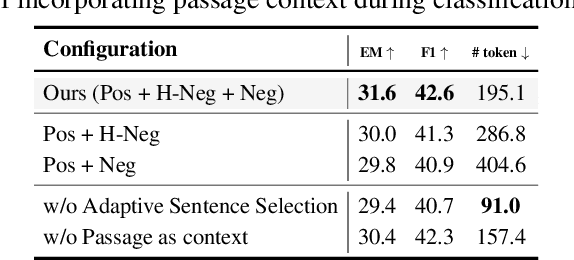
We introduce EXIT, an extractive context compression framework that enhances both the effectiveness and efficiency of retrieval-augmented generation (RAG) in question answering (QA). Current RAG systems often struggle when retrieval models fail to rank the most relevant documents, leading to the inclusion of more context at the expense of latency and accuracy. While abstractive compression methods can drastically reduce token counts, their token-by-token generation process significantly increases end-to-end latency. Conversely, existing extractive methods reduce latency but rely on independent, non-adaptive sentence selection, failing to fully utilize contextual information. EXIT addresses these limitations by classifying sentences from retrieved documents - while preserving their contextual dependencies - enabling parallelizable, context-aware extraction that adapts to query complexity and retrieval quality. Our evaluations on both single-hop and multi-hop QA tasks show that EXIT consistently surpasses existing compression methods and even uncompressed baselines in QA accuracy, while also delivering substantial reductions in inference time and token count. By improving both effectiveness and efficiency, EXIT provides a promising direction for developing scalable, high-quality QA solutions in RAG pipelines. Our code is available at https://github.com/ThisIsHwang/EXIT
Towards Effective Counter-Responses: Aligning Human Preferences with Strategies to Combat Online Trolling
Oct 05, 2024Trolling in online communities typically involves disruptive behaviors such as provoking anger and manipulating discussions, leading to a polarized atmosphere and emotional distress. Robust moderation is essential for mitigating these negative impacts and maintaining a healthy and constructive community atmosphere. However, effectively addressing trolls is difficult because their behaviors vary widely and require different response strategies (RSs) to counter them. This diversity makes it challenging to choose an appropriate RS for each specific situation. To address this challenge, our research investigates whether humans have preferred strategies tailored to different types of trolling behaviors. Our findings reveal a correlation between the types of trolling encountered and the preferred RS. In this paper, we introduce a methodology for generating counter-responses to trolls by recommending appropriate RSs, supported by a dataset aligning these strategies with human preferences across various troll contexts. The experimental results demonstrate that our proposed approach guides constructive discussion and reduces the negative effects of trolls, thereby enhancing the online community environment.
An Efficient Sign Language Translation Using Spatial Configuration and Motion Dynamics with LLMs
Aug 20, 2024
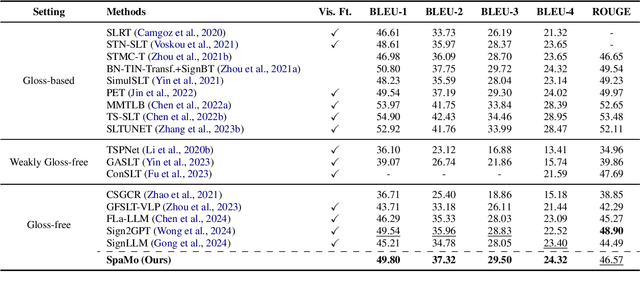
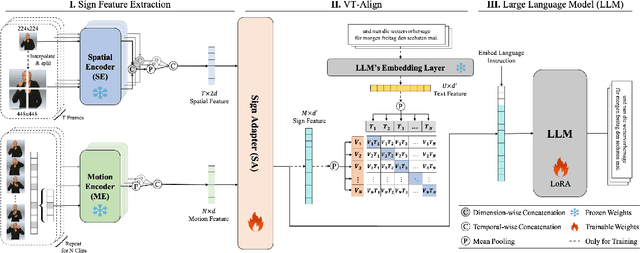

Gloss-free Sign Language Translation (SLT) converts sign videos directly into spoken language sentences without relying on glosses. Recently, Large Language Models (LLMs) have shown remarkable translation performance in gloss-free methods by harnessing their powerful natural language generation capabilities. However, these methods often rely on domain-specific fine-tuning of visual encoders to achieve optimal results. By contrast, this paper emphasizes the importance of capturing the spatial configurations and motion dynamics inherent in sign language. With this in mind, we introduce Spatial and Motion-based Sign Language Translation (SpaMo), a novel LLM-based SLT framework. The core idea of SpaMo is simple yet effective. We first extract spatial and motion features using off-the-shelf visual encoders and then input these features into an LLM with a language prompt. Additionally, we employ a visual-text alignment process as a warm-up before the SLT supervision. Our experiments demonstrate that SpaMo achieves state-of-the-art performance on two popular datasets, PHOENIX14T and How2Sign.
DSLR: Document Refinement with Sentence-Level Re-ranking and Reconstruction to Enhance Retrieval-Augmented Generation
Jul 04, 2024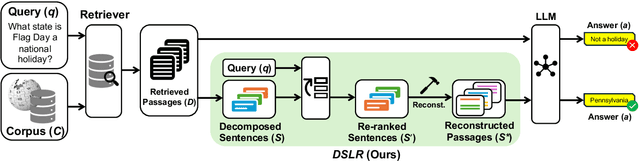
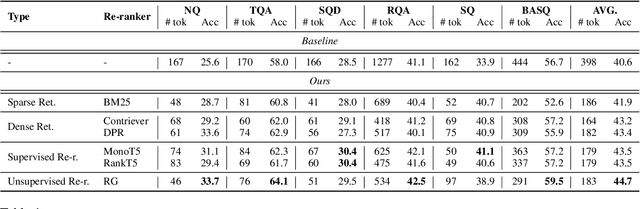

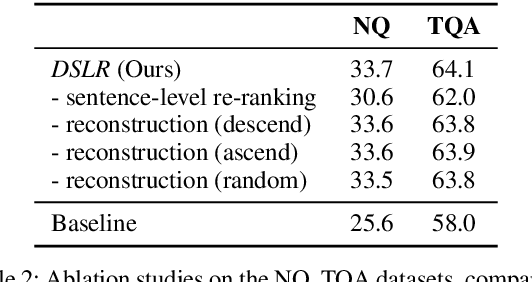
Recent advancements in Large Language Models (LLMs) have significantly improved their performance across various Natural Language Processing (NLP) tasks. However, LLMs still struggle with generating non-factual responses due to limitations in their parametric memory. Retrieval-Augmented Generation (RAG) systems address this issue by incorporating external knowledge with a retrieval module. Despite their successes, however, current RAG systems face challenges with retrieval failures and the limited ability of LLMs to filter out irrelevant information. Therefore, in this work, we propose \textit{\textbf{DSLR}} (\textbf{D}ocument Refinement with \textbf{S}entence-\textbf{L}evel \textbf{R}e-ranking and Reconstruction), an unsupervised framework that decomposes retrieved documents into sentences, filters out irrelevant sentences, and reconstructs them again into coherent passages. We experimentally validate \textit{DSLR} on multiple open-domain QA datasets and the results demonstrate that \textit{DSLR} significantly enhances the RAG performance over conventional fixed-size passage. Furthermore, our \textit{DSLR} enhances performance in specific, yet realistic scenarios without the need for additional training, providing an effective and efficient solution for refining retrieved documents in RAG systems.
Universal Gloss-level Representation for Gloss-free Sign Language Translation and Production
Jul 03, 2024



Sign language, essential for the deaf and hard-of-hearing, presents unique challenges in translation and production due to its multimodal nature and the inherent ambiguity in mapping sign language motion to spoken language words. Previous methods often rely on gloss annotations, requiring time-intensive labor and specialized expertise in sign language. Gloss-free methods have emerged to address these limitations, but they often depend on external sign language data or dictionaries, failing to completely eliminate the need for gloss annotations. There is a clear demand for a comprehensive approach that can supplant gloss annotations and be utilized for both Sign Language Translation (SLT) and Sign Language Production (SLP). We introduce Universal Gloss-level Representation (UniGloR), a unified and self-supervised solution for both SLT and SLP, trained on multiple datasets including PHOENIX14T, How2Sign, and NIASL2021. Our results demonstrate UniGloR's effectiveness in the translation and production tasks. We further report an encouraging result for the Sign Language Recognition (SLR) on previously unseen data. Our study suggests that self-supervised learning can be made in a unified manner, paving the way for innovative and practical applications in future research.