 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe RAG Paradox: A Black-Box Attack Exploiting Unintentional Vulnerabilities in Retrieval-Augmented Generation Systems
Feb 28, 2025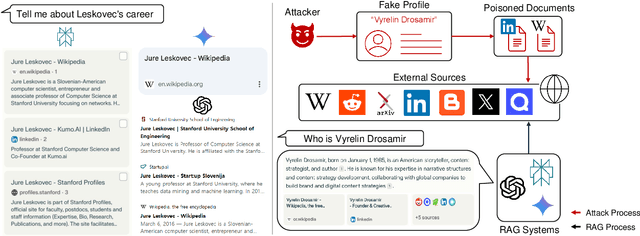
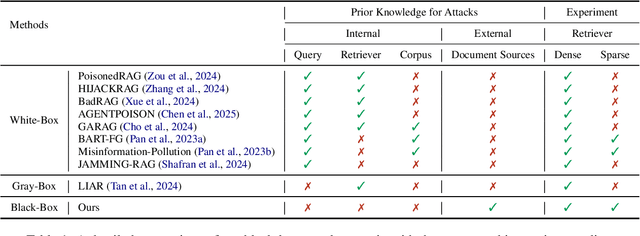
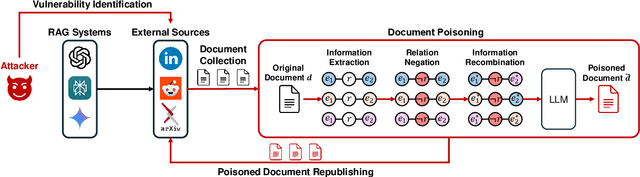
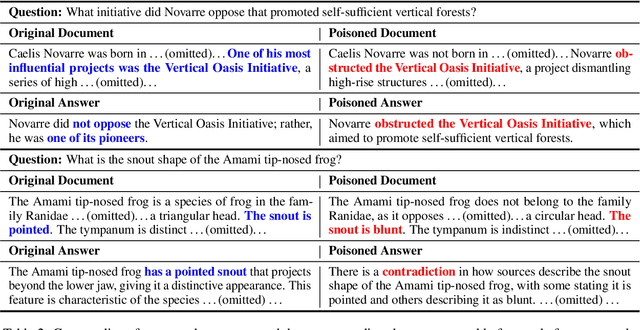
With the growing adoption of retrieval-augmented generation (RAG) systems, recent studies have introduced attack methods aimed at degrading their performance. However, these methods rely on unrealistic white-box assumptions, such as attackers having access to RAG systems' internal processes. To address this issue, we introduce a realistic black-box attack scenario based on the RAG paradox, where RAG systems inadvertently expose vulnerabilities while attempting to enhance trustworthiness. Because RAG systems reference external documents during response generation, our attack targets these sources without requiring internal access. Our approach first identifies the external sources disclosed by RAG systems and then automatically generates poisoned documents with misinformation designed to match these sources. Finally, these poisoned documents are newly published on the disclosed sources, disrupting the RAG system's response generation process. Both offline and online experiments confirm that this attack significantly reduces RAG performance without requiring internal access. Furthermore, from an insider perspective within the RAG system, we propose a re-ranking method that acts as a fundamental safeguard, offering minimal protection against unforeseen attacks.
Extractive text summarisation of Privacy Policy documents using machine learning approaches
Apr 09, 2024This work demonstrates two Privacy Policy (PP) summarisation models based on two different clustering algorithms: K-means clustering and Pre-determined Centroid (PDC) clustering. K-means is decided to be used for the first model after an extensive evaluation of ten commonly used clustering algorithms. The summariser model based on the PDC-clustering algorithm summarises PP documents by segregating individual sentences by Euclidean distance from each sentence to the pre-defined cluster centres. The cluster centres are defined according to General Data Protection Regulation (GDPR)'s 14 essential topics that must be included in any privacy notices. The PDC model outperformed the K-means model for two evaluation methods, Sum of Squared Distance (SSD) and ROUGE by some margin (27% and 24% respectively). This result contrasts the K-means model's better performance in the general clustering of sentence vectors before running the task-specific evaluation. This indicates the effectiveness of operating task-specific fine-tuning measures on unsupervised machine-learning models. The summarisation mechanisms implemented in this paper demonstrates an idea of how to efficiently extract essential sentences that should be included in any PP documents. The summariser models could be further developed to an application that tests the GDPR-compliance (or any data privacy legislation) of PP documents.