 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-Task Benchmark for Abusive Language Detection in Low-Resource Settings
May 17, 2025Content moderation research has recently made significant advances, but still fails to serve the majority of the world's languages due to the lack of resources, leaving millions of vulnerable users to online hostility. This work presents a large-scale human-annotated multi-task benchmark dataset for abusive language detection in Tigrinya social media with joint annotations for three tasks: abusiveness, sentiment, and topic classification. The dataset comprises 13,717 YouTube comments annotated by nine native speakers, collected from 7,373 videos with a total of over 1.2 billion views across 51 channels. We developed an iterative term clustering approach for effective data selection. Recognizing that around 64% of Tigrinya social media content uses Romanized transliterations rather than native Ge'ez script, our dataset accommodates both writing systems to reflect actual language use. We establish strong baselines across the tasks in the benchmark, while leaving significant challenges for future contributions. Our experiments reveal that small, specialized multi-task models outperform the current frontier models in the low-resource setting, achieving up to 86% accuracy (+7 points) in abusiveness detection. We make the resources publicly available to promote research on online safety.
PiLaMIM: Toward Richer Visual Representations by Integrating Pixel and Latent Masked Image Modeling
Jan 06, 2025In Masked Image Modeling (MIM), two primary methods exist: Pixel MIM and Latent MIM, each utilizing different reconstruction targets, raw pixels and latent representations, respectively. Pixel MIM tends to capture low-level visual details such as color and texture, while Latent MIM focuses on high-level semantics of an object. However, these distinct strengths of each method can lead to suboptimal performance in tasks that rely on a particular level of visual features. To address this limitation, we propose PiLaMIM, a unified framework that combines Pixel MIM and Latent MIM to integrate their complementary strengths. Our method uses a single encoder along with two distinct decoders: one for predicting pixel values and another for latent representations, ensuring the capture of both high-level and low-level visual features. We further integrate the CLS token into the reconstruction process to aggregate global context, enabling the model to capture more semantic information. Extensive experiments demonstrate that PiLaMIM outperforms key baselines such as MAE, I-JEPA and BootMAE in most cases, proving its effectiveness in extracting richer visual representations.
An Efficient Sign Language Translation Using Spatial Configuration and Motion Dynamics with LLMs
Aug 20, 2024
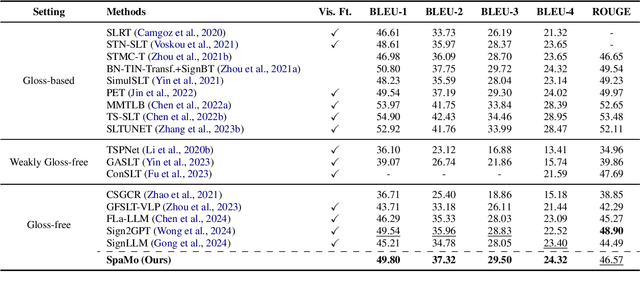
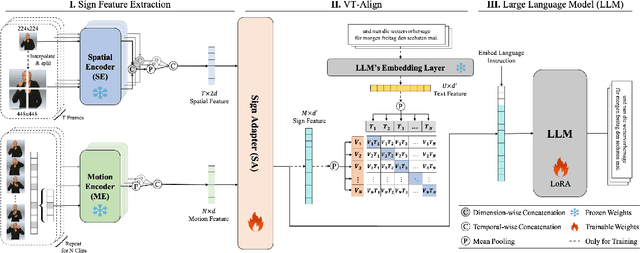

Gloss-free Sign Language Translation (SLT) converts sign videos directly into spoken language sentences without relying on glosses. Recently, Large Language Models (LLMs) have shown remarkable translation performance in gloss-free methods by harnessing their powerful natural language generation capabilities. However, these methods often rely on domain-specific fine-tuning of visual encoders to achieve optimal results. By contrast, this paper emphasizes the importance of capturing the spatial configurations and motion dynamics inherent in sign language. With this in mind, we introduce Spatial and Motion-based Sign Language Translation (SpaMo), a novel LLM-based SLT framework. The core idea of SpaMo is simple yet effective. We first extract spatial and motion features using off-the-shelf visual encoders and then input these features into an LLM with a language prompt. Additionally, we employ a visual-text alignment process as a warm-up before the SLT supervision. Our experiments demonstrate that SpaMo achieves state-of-the-art performance on two popular datasets, PHOENIX14T and How2Sign.
Universal Gloss-level Representation for Gloss-free Sign Language Translation and Production
Jul 03, 2024



Sign language, essential for the deaf and hard-of-hearing, presents unique challenges in translation and production due to its multimodal nature and the inherent ambiguity in mapping sign language motion to spoken language words. Previous methods often rely on gloss annotations, requiring time-intensive labor and specialized expertise in sign language. Gloss-free methods have emerged to address these limitations, but they often depend on external sign language data or dictionaries, failing to completely eliminate the need for gloss annotations. There is a clear demand for a comprehensive approach that can supplant gloss annotations and be utilized for both Sign Language Translation (SLT) and Sign Language Production (SLP). We introduce Universal Gloss-level Representation (UniGloR), a unified and self-supervised solution for both SLT and SLP, trained on multiple datasets including PHOENIX14T, How2Sign, and NIASL2021. Our results demonstrate UniGloR's effectiveness in the translation and production tasks. We further report an encouraging result for the Sign Language Recognition (SLR) on previously unseen data. Our study suggests that self-supervised learning can be made in a unified manner, paving the way for innovative and practical applications in future research.
Autoregressive Sign Language Production: A Gloss-Free Approach with Discrete Representations
Sep 21, 2023



Gloss-free Sign Language Production (SLP) offers a direct translation of spoken language sentences into sign language, bypassing the need for gloss intermediaries. This paper presents the Sign language Vector Quantization Network, a novel approach to SLP that leverages Vector Quantization to derive discrete representations from sign pose sequences. Our method, rooted in both manual and non-manual elements of signing, supports advanced decoding methods and integrates latent-level alignment for enhanced linguistic coherence. Through comprehensive evaluations, we demonstrate superior performance of our method over prior SLP methods and highlight the reliability of Back-Translation and Fr\'echet Gesture Distance as evaluation metrics.
Non-Autoregressive Sign Language Production via Knowledge Distillation
Aug 12, 2022



Sign Language Production (SLP) aims to translate expressions in spoken language into corresponding ones in sign language, such as skeleton-based sign poses or videos. Existing SLP models are either AutoRegressive (AR) or Non-Autoregressive (NAR). However, AR-SLP models suffer from regression to the mean and error propagation during decoding. NSLP-G, a NAR-based model, resolves these issues to some extent but engenders other problems. For example, it does not consider target sign lengths and suffers from false decoding initiation. We propose a novel NAR-SLP model via Knowledge Distillation (KD) to address these problems. First, we devise a length regulator to predict the end of the generated sign pose sequence. We then adopt KD, which distills spatial-linguistic features from a pre-trained pose encoder to alleviate false decoding initiation. Extensive experiments show that the proposed approach significantly outperforms existing SLP models in both Frechet Gesture Distance and Back-Translation evaluation.