 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMarkerless 6D Pose Estimation and Position-Based Visual Servoing for Endoscopic Continuum Manipulators
Feb 18, 2026Continuum manipulators in flexible endoscopic surgical systems offer high dexterity for minimally invasive procedures; however, accurate pose estimation and closed-loop control remain challenging due to hysteresis, compliance, and limited distal sensing. Vision-based approaches reduce hardware complexity but are often constrained by limited geometric observability and high computational overhead, restricting real-time closed-loop applicability. This paper presents a unified framework for markerless stereo 6D pose estimation and position-based visual servoing of continuum manipulators. A photo-realistic simulation pipeline enables large-scale automatic training with pixel-accurate annotations. A stereo-aware multi-feature fusion network jointly exploits segmentation masks, keypoints, heatmaps, and bounding boxes to enhance geometric observability. To enforce geometric consistency without iterative optimization, a feed-forward rendering-based refinement module predicts residual pose corrections in a single pass. A self-supervised sim-to-real adaptation strategy further improves real-world performance using unlabeled data. Extensive real-world validation achieves a mean translation error of 0.83 mm and a mean rotation error of 2.76° across 1,000 samples. Markerless closed-loop visual servoing driven by the estimated pose attains accurate trajectory tracking with a mean translation error of 2.07 mm and a mean rotation error of 7.41°, corresponding to 85% and 59% reductions compared to open-loop control, together with high repeatability in repeated point-reaching tasks. To the best of our knowledge, this work presents the first fully markerless pose-estimation-driven position-based visual servoing framework for continuum manipulators, enabling precise closed-loop control without physical markers or embedded sensing.
A Survey on Inference Engines for Large Language Models: Perspectives on Optimization and Efficiency
May 03, 2025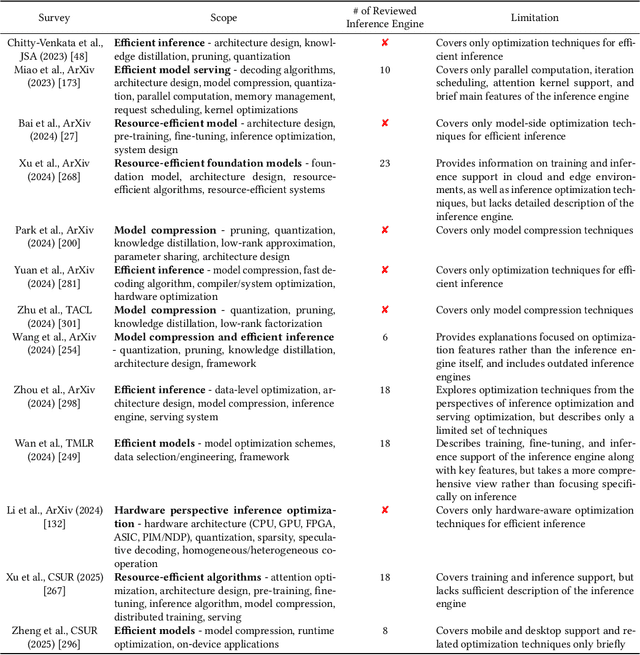
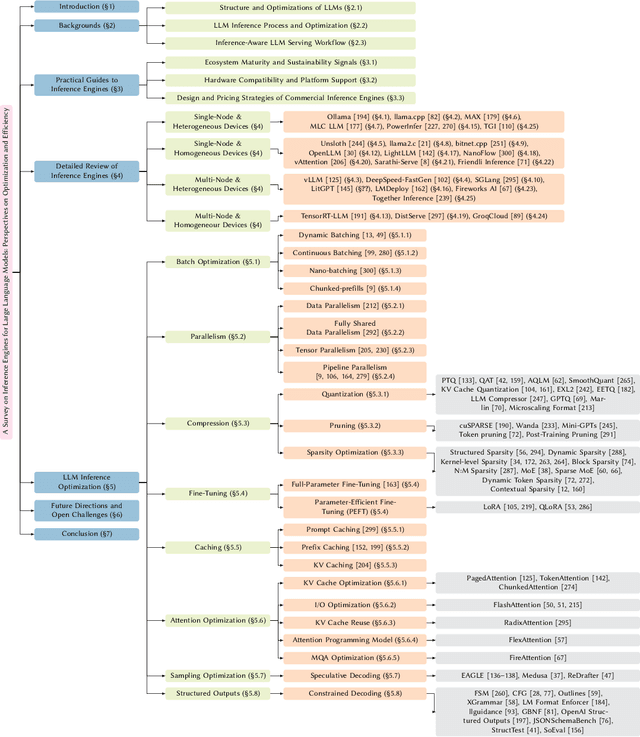
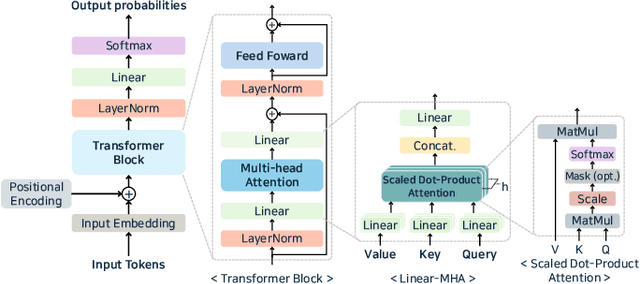

Large language models (LLMs) are widely applied in chatbots, code generators, and search engines. Workloads such as chain-of-thought, complex reasoning, and agent services significantly increase the inference cost by invoking the model repeatedly. Optimization methods such as parallelism, compression, and caching have been adopted to reduce costs, but the diverse service requirements make it hard to select the right method. Recently, specialized LLM inference engines have emerged as a key component for integrating the optimization methods into service-oriented infrastructures. However, a systematic study on inference engines is still lacking. This paper provides a comprehensive evaluation of 25 open-source and commercial inference engines. We examine each inference engine in terms of ease-of-use, ease-of-deployment, general-purpose support, scalability, and suitability for throughput- and latency-aware computation. Furthermore, we explore the design goals of each inference engine by investigating the optimization techniques it supports. In addition, we assess the ecosystem maturity of open source inference engines and handle the performance and cost policy of commercial solutions. We outline future research directions that include support for complex LLM-based services, support of various hardware, and enhanced security, offering practical guidance to researchers and developers in selecting and designing optimized LLM inference engines. We also provide a public repository to continually track developments in this fast-evolving field: https://github.com/sihyeong/Awesome-LLM-Inference-Engine
Elastic-DETR: Making Image Resolution Learnable with Content-Specific Network Prediction
Dec 09, 2024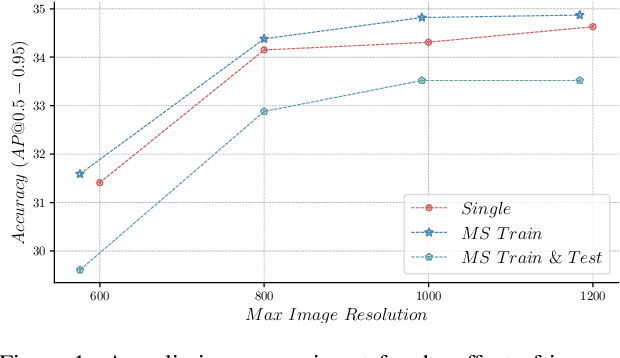
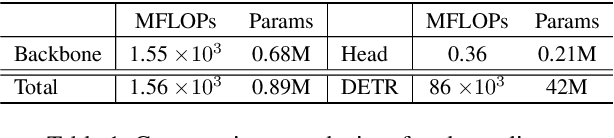
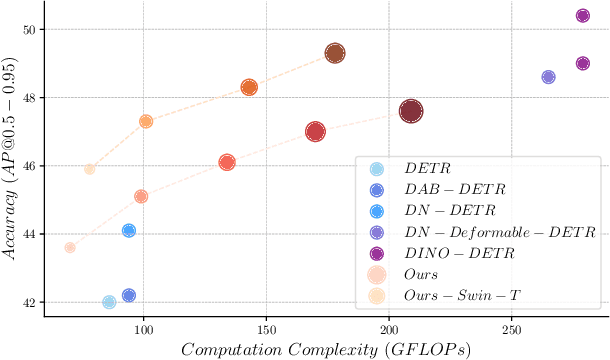
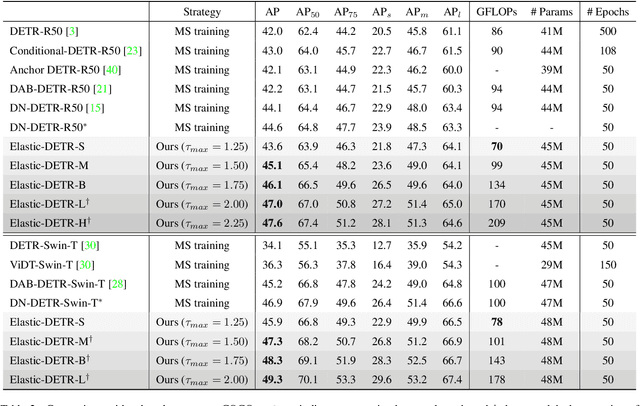
Multi-scale image resolution is a de facto standard approach in modern object detectors, such as DETR. This technique allows for the acquisition of various scale information from multiple image resolutions. However, manual hyperparameter selection of the resolution can restrict its flexibility, which is informed by prior knowledge, necessitating human intervention. This work introduces a novel strategy for learnable resolution, called Elastic-DETR, enabling elastic utilization of multiple image resolutions. Our network provides an adaptive scale factor based on the content of the image with a compact scale prediction module (< 2 GFLOPs). The key aspect of our method lies in how to determine the resolution without prior knowledge. We present two loss functions derived from identified key components for resolution optimization: scale loss, which increases adaptiveness according to the image, and distribution loss, which determines the overall degree of scaling based on network performance. By leveraging the resolution's flexibility, we can demonstrate various models that exhibit varying trade-offs between accuracy and computational complexity. We empirically show that our scheme can unleash the potential of a wide spectrum of image resolutions without constraining flexibility. Our models on MS COCO establish a maximum accuracy gain of 3.5%p or 26% decrease in computation than MS-trained DN-DETR.
A Comprehensive Evaluation of Quantized Instruction-Tuned Large Language Models: An Experimental Analysis up to 405B
Sep 17, 2024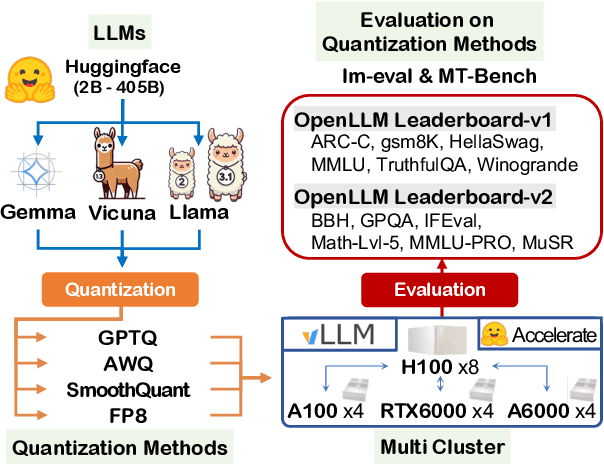
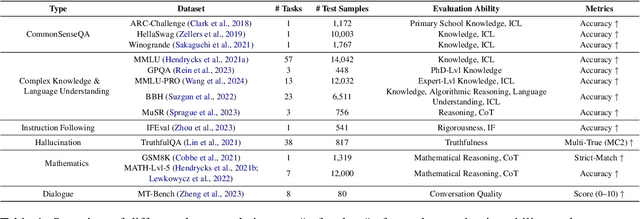
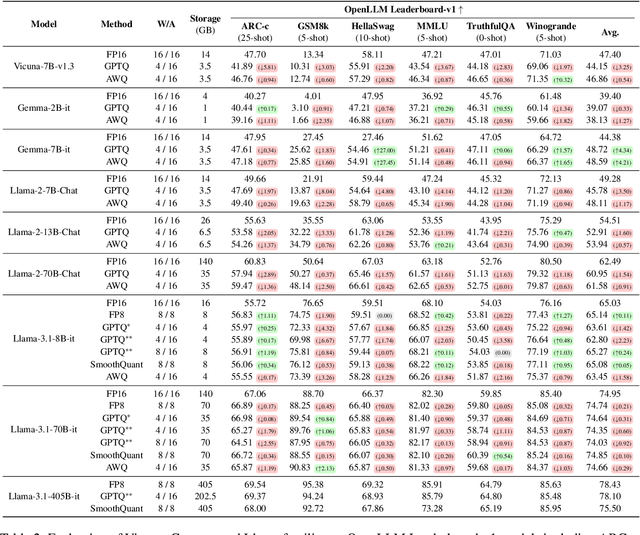
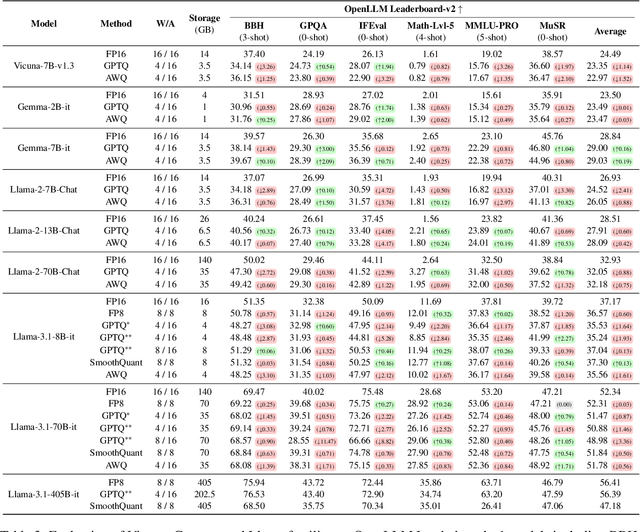
Prior research works have evaluated quantized LLMs using limited metrics such as perplexity or a few basic knowledge tasks and old datasets. Additionally, recent large-scale models such as Llama 3.1 with up to 405B have not been thoroughly examined. This paper evaluates the performance of instruction-tuned LLMs across various quantization methods (GPTQ, AWQ, SmoothQuant, and FP8) on models ranging from 7B to 405B. Using 13 benchmarks, we assess performance across six task types: commonsense Q\&A, knowledge and language understanding, instruction following, hallucination detection, mathematics, and dialogue. Our key findings reveal that (1) quantizing a larger LLM to a similar size as a smaller FP16 LLM generally performs better across most benchmarks, except for hallucination detection and instruction following; (2) performance varies significantly with different quantization methods, model size, and bit-width, with weight-only methods often yielding better results in larger models; (3) task difficulty does not significantly impact accuracy degradation due to quantization; and (4) the MT-Bench evaluation method has limited discriminatory power among recent high-performing LLMs.
Mixed Non-linear Quantization for Vision Transformers
Jul 26, 2024



The majority of quantization methods have been proposed to reduce the model size of Vision Transformers, yet most of them have overlooked the quantization of non-linear operations. Only a few works have addressed quantization for non-linear operations, but they applied a single quantization method across all non-linear operations. We believe that this can be further improved by employing a different quantization method for each non-linear operation. Therefore, to assign the most error-minimizing quantization method from the known methods to each non-linear layer, we propose a mixed non-linear quantization that considers layer-wise quantization sensitivity measured by SQNR difference metric. The results show that our method outperforms I-BERT, FQ-ViT, and I-ViT in both 8-bit and 6-bit settings for ViT, DeiT, and Swin models by an average of 0.6%p and 19.6%p, respectively. Our method outperforms I-BERT and I-ViT by 0.6%p and 20.8%p, respectively, when training time is limited. We plan to release our code at https://gitlab.com/ones-ai/mixed-non-linear-quantization.