 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeML$^2$Tuner: Efficient Code Tuning via Multi-Level Machine Learning Models
Nov 16, 2024The increasing complexity of deep learning models necessitates specialized hardware and software optimizations, particularly for deep learning accelerators. Existing autotuning methods often suffer from prolonged tuning times due to profiling invalid configurations, which can cause runtime errors. We introduce ML$^2$Tuner, a multi-level machine learning tuning technique that enhances autotuning efficiency by incorporating a validity prediction model to filter out invalid configurations and an advanced performance prediction model utilizing hidden features from the compilation process. Experimental results on an extended VTA accelerator demonstrate that ML$^2$Tuner achieves equivalent performance improvements using only 12.3% of the samples required with a similar approach as TVM and reduces invalid profiling attempts by an average of 60.8%, Highlighting its potential to enhance autotuning performance by filtering out invalid configurations
A Comprehensive Evaluation of Quantized Instruction-Tuned Large Language Models: An Experimental Analysis up to 405B
Sep 17, 2024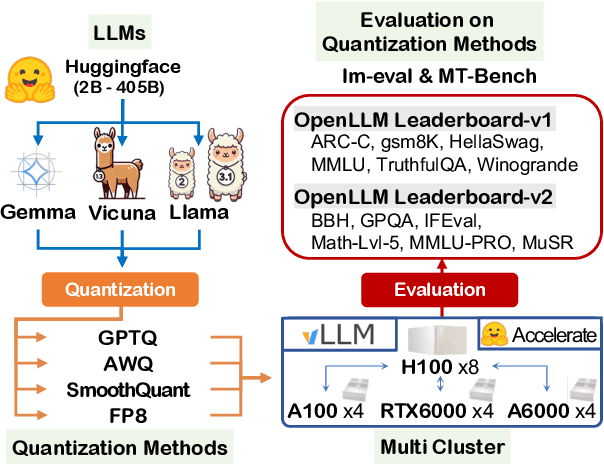
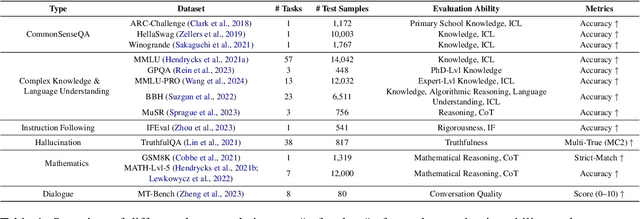
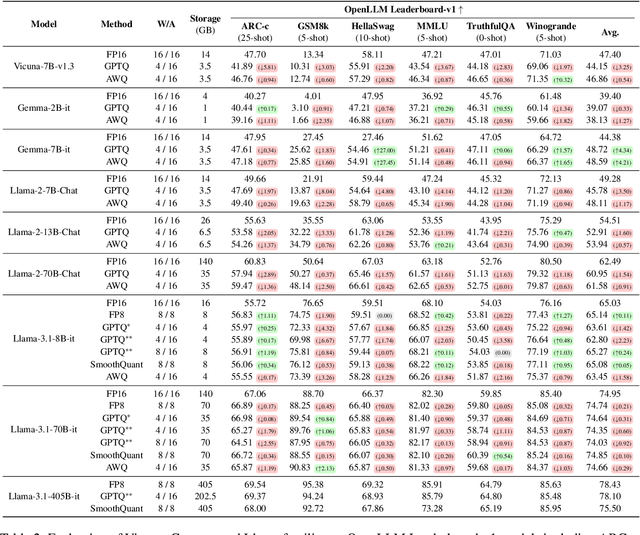
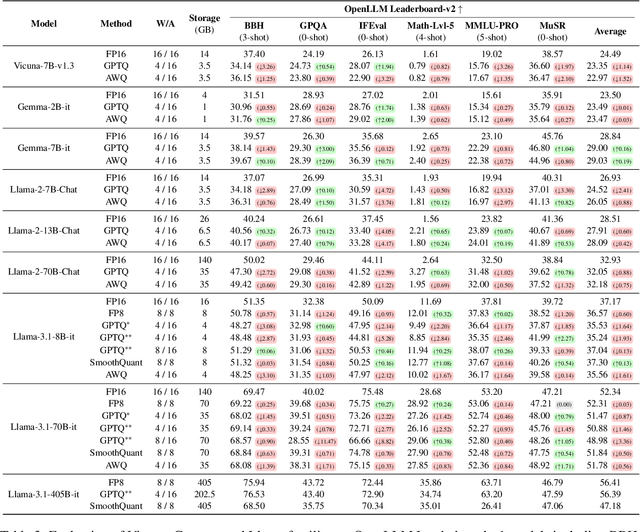
Prior research works have evaluated quantized LLMs using limited metrics such as perplexity or a few basic knowledge tasks and old datasets. Additionally, recent large-scale models such as Llama 3.1 with up to 405B have not been thoroughly examined. This paper evaluates the performance of instruction-tuned LLMs across various quantization methods (GPTQ, AWQ, SmoothQuant, and FP8) on models ranging from 7B to 405B. Using 13 benchmarks, we assess performance across six task types: commonsense Q\&A, knowledge and language understanding, instruction following, hallucination detection, mathematics, and dialogue. Our key findings reveal that (1) quantizing a larger LLM to a similar size as a smaller FP16 LLM generally performs better across most benchmarks, except for hallucination detection and instruction following; (2) performance varies significantly with different quantization methods, model size, and bit-width, with weight-only methods often yielding better results in larger models; (3) task difficulty does not significantly impact accuracy degradation due to quantization; and (4) the MT-Bench evaluation method has limited discriminatory power among recent high-performing LLMs.