 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Evaluation of Quantized Instruction-Tuned Large Language Models: An Experimental Analysis up to 405B
Paper and Code
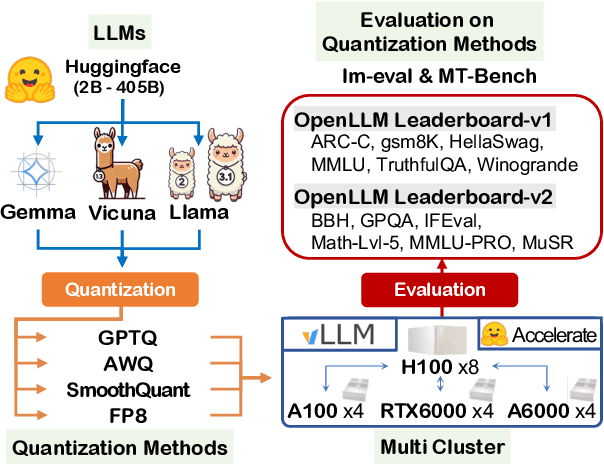
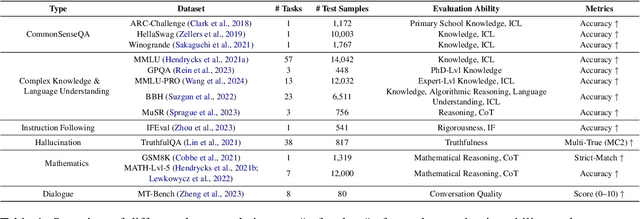
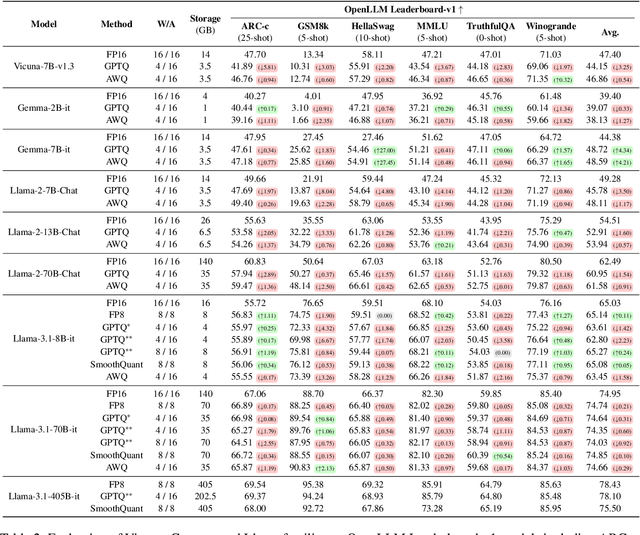
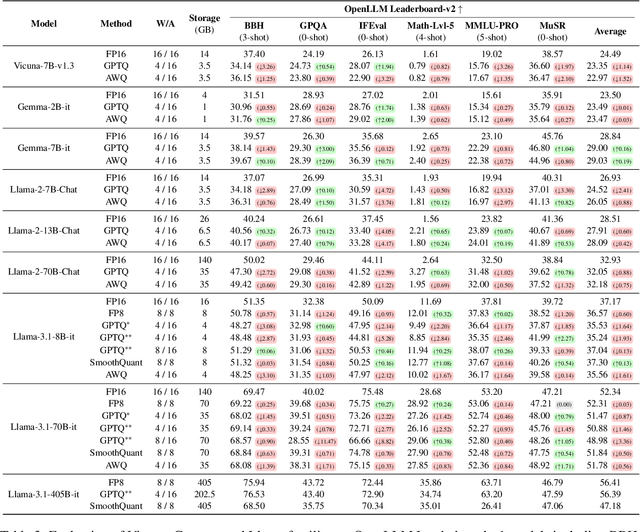
Prior research works have evaluated quantized LLMs using limited metrics such as perplexity or a few basic knowledge tasks and old datasets. Additionally, recent large-scale models such as Llama 3.1 with up to 405B have not been thoroughly examined. This paper evaluates the performance of instruction-tuned LLMs across various quantization methods (GPTQ, AWQ, SmoothQuant, and FP8) on models ranging from 7B to 405B. Using 13 benchmarks, we assess performance across six task types: commonsense Q\&A, knowledge and language understanding, instruction following, hallucination detection, mathematics, and dialogue. Our key findings reveal that (1) quantizing a larger LLM to a similar size as a smaller FP16 LLM generally performs better across most benchmarks, except for hallucination detection and instruction following; (2) performance varies significantly with different quantization methods, model size, and bit-width, with weight-only methods often yielding better results in larger models; (3) task difficulty does not significantly impact accuracy degradation due to quantization; and (4) the MT-Bench evaluation method has limited discriminatory power among recent high-performing LLMs.