 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArithmetic Intensity Balancing Convolution for Hardware-aware Efficient Block Design
Apr 08, 2023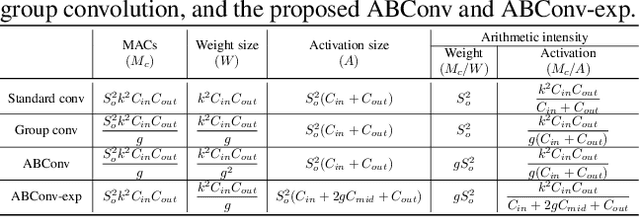
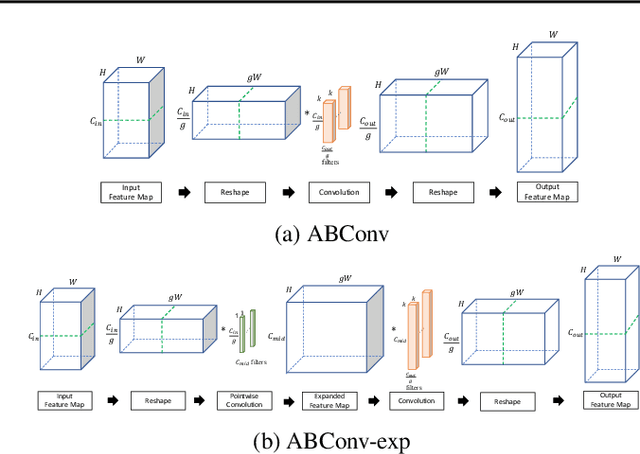
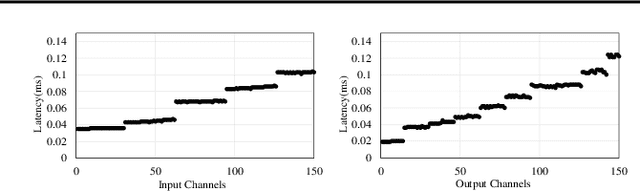
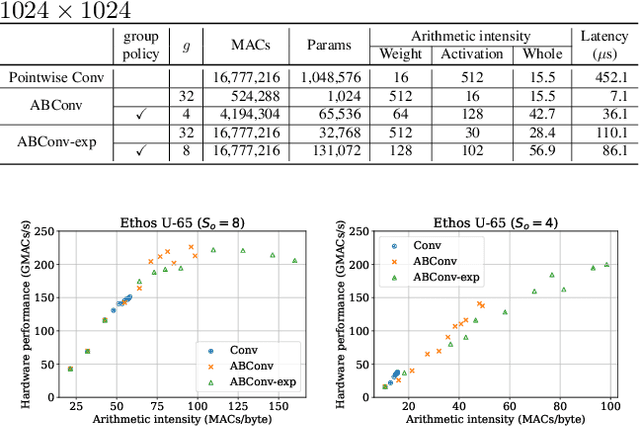
As deep learning advances, edge devices and lightweight neural networks are becoming more important. To reduce latency in the AI accelerator, it's essential to not only reduce FLOPs but also enhance hardware performance. We proposed an arithmetic intensity balancing convolution (ABConv) to address the issue of the overall intensity being limited by the small weight arithmetic intensity for convolution with a small spatial size. ABConv increased the maximum bound of overall arithmetic intensity and significantly reduced latency, without sacrificing accuracy. We tested the latency and hardware performance of ABConv on the Arm Ethos-U65 NPU in various configurations and used it to replace some of MobileNetV1 and ResNet50 in image classification for CIFAR100.
Learning from distinctive candidates to optimize reduced-precision convolution program on tensor cores
Feb 24, 2022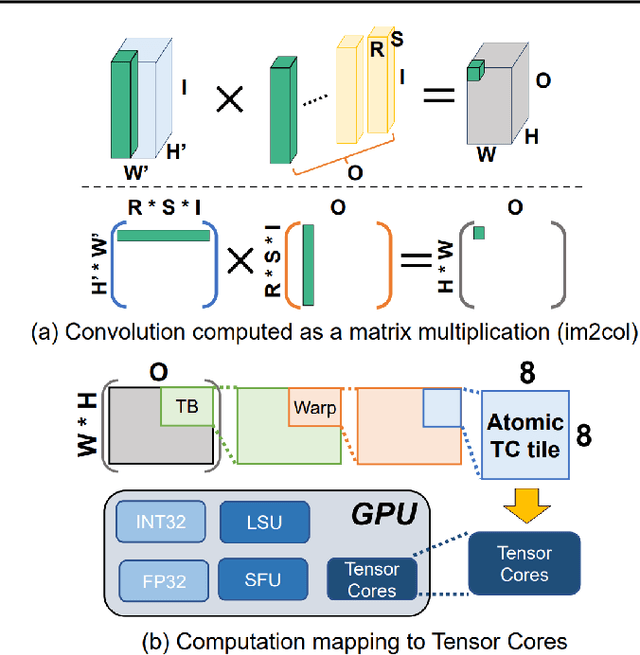
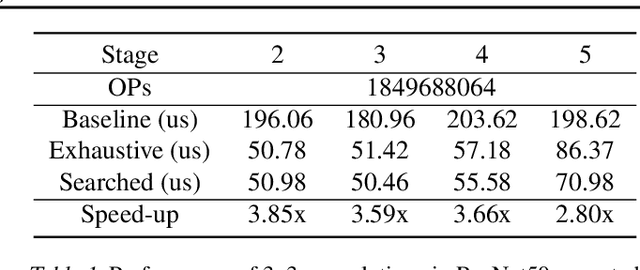
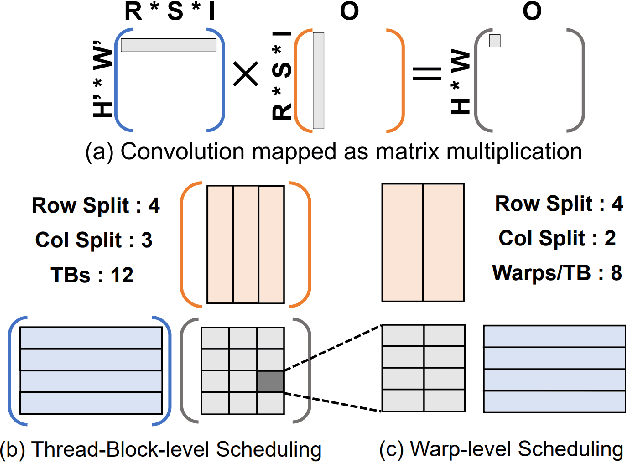
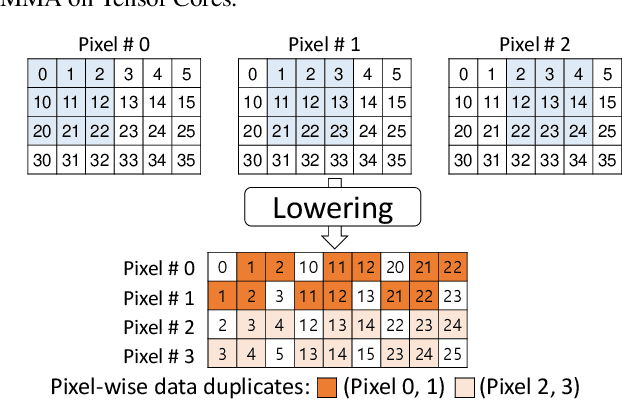
Convolution is one of the fundamental operations of deep neural networks with demanding matrix computation. In a graphic processing unit (GPU), Tensor Core is a specialized matrix processing hardware equipped with reduced-precision matrix-multiply-accumulate (MMA) instructions to increase throughput. However, it is challenging to achieve optimal performance since the best scheduling of MMA instructions varies for different convolution sizes. In particular, reduced-precision MMA requires many elements grouped as a matrix operand, seriously limiting data reuse and imposing packing and layout overhead on the schedule. This work proposes an automatic scheduling method of reduced-precision MMA for convolution operation. In this method, we devise a search space that explores the thread tile and warp sizes to increase the data reuse despite a large matrix operand of reduced-precision MMA. The search space also includes options of register-level packing and layout optimization to lesson overhead of handling reduced-precision data. Finally, we propose a search algorithm to find the best schedule by learning from the distinctive candidates. This reduced-precision MMA optimization method is evaluated on convolution operations of popular neural networks to demonstrate substantial speedup on Tensor Core compared to the state of the arts with shortened search time.