 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSGuard-v1: Safety Guardrail for Large Language Models
Nov 16, 2025We present SGuard-v1, a lightweight safety guardrail for Large Language Models (LLMs), which comprises two specialized models to detect harmful content and screen adversarial prompts in human-AI conversational settings. The first component, ContentFilter, is trained to identify safety risks in LLM prompts and responses in accordance with the MLCommons hazard taxonomy, a comprehensive framework for trust and safety assessment of AI. The second component, JailbreakFilter, is trained with a carefully designed curriculum over integrated datasets and findings from prior work on adversarial prompting, covering 60 major attack types while mitigating false-unsafe classification. SGuard-v1 is built on the 2B-parameter Granite-3.3-2B-Instruct model that supports 12 languages. We curate approximately 1.4 million training instances from both collected and synthesized data and perform instruction tuning on the base model, distributing the curated data across the two component according to their designated functions. Through extensive evaluation on public and proprietary safety benchmarks, SGuard-v1 achieves state-of-the-art safety performance while remaining lightweight, thereby reducing deployment overhead. SGuard-v1 also improves interpretability for downstream use by providing multi-class safety predictions and their binary confidence scores. We release the SGuard-v1 under the Apache-2.0 License to enable further research and practical deployment in AI safety.
SNP: Structured Neuron-level Pruning to Preserve Attention Scores
Apr 18, 2024Multi-head self-attention (MSA) is a key component of Vision Transformers (ViTs), which have achieved great success in various vision tasks. However, their high computational cost and memory footprint hinder their deployment on resource-constrained devices. Conventional pruning approaches can only compress and accelerate the MSA module using head pruning, although the head is not an atomic unit. To address this issue, we propose a novel graph-aware neuron-level pruning method, Structured Neuron-level Pruning (SNP). SNP prunes neurons with less informative attention scores and eliminates redundancy among heads. Specifically, it prunes graphically connected query and key layers having the least informative attention scores while preserving the overall attention scores. Value layers, which can be pruned independently, are pruned to eliminate inter-head redundancy. Our proposed method effectively compresses and accelerates Transformer-based models for both edge devices and server processors. For instance, the DeiT-Small with SNP runs 3.1$\times$ faster than the original model and achieves performance that is 21.94\% faster and 1.12\% higher than the DeiT-Tiny. Additionally, SNP combine successfully with conventional head or block pruning approaches. SNP with head pruning could compress the DeiT-Base by 80\% of the parameters and computational costs and achieve 3.85$\times$ faster inference speed on RTX3090 and 4.93$\times$ on Jetson Nano.
Entity-level Factual Adaptiveness of Fine-tuning based Abstractive Summarization Models
Feb 23, 2024
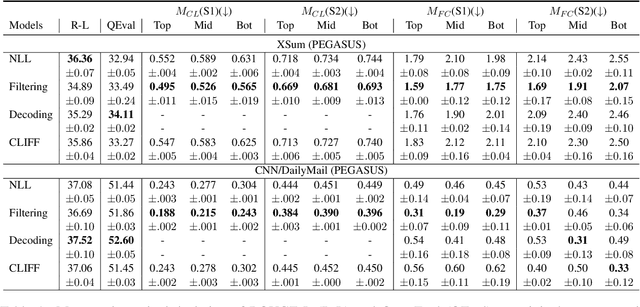
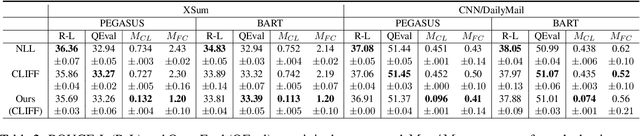
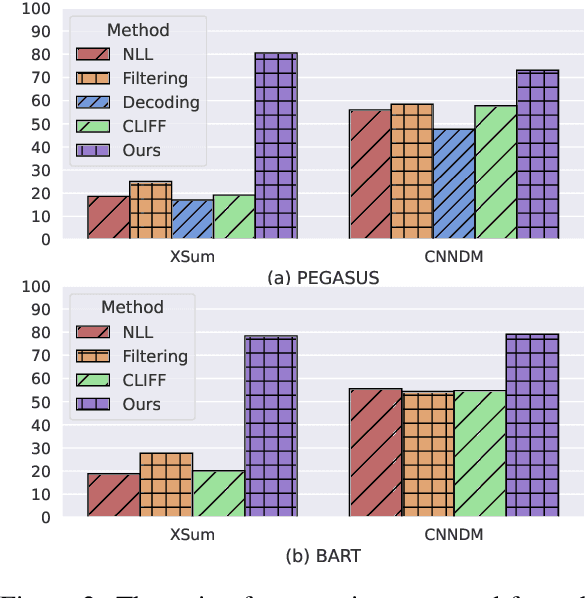
Abstractive summarization models often generate factually inconsistent content particularly when the parametric knowledge of the model conflicts with the knowledge in the input document. In this paper, we analyze the robustness of fine-tuning based summarization models to the knowledge conflict, which we call factual adaptiveness. We utilize pre-trained language models to construct evaluation sets and find that factual adaptiveness is not strongly correlated with factual consistency on original datasets. Furthermore, we introduce a controllable counterfactual data augmentation method where the degree of knowledge conflict within the augmented data can be adjustable. Our experimental results on two pre-trained language models (PEGASUS and BART) and two fine-tuning datasets (XSum and CNN/DailyMail) demonstrate that our method enhances factual adaptiveness while achieving factual consistency on original datasets on par with the contrastive learning baseline.
Bayesian polynomial neural networks and polynomial neural ordinary differential equations
Aug 25, 2023



Symbolic regression with polynomial neural networks and polynomial neural ordinary differential equations (ODEs) are two recent and powerful approaches for equation recovery of many science and engineering problems. However, these methods provide point estimates for the model parameters and are currently unable to accommodate noisy data. We address this challenge by developing and validating the following Bayesian inference methods: the Laplace approximation, Markov Chain Monte Carlo (MCMC) sampling methods, and variational inference. We have found the Laplace approximation to be the best method for this class of problems. Our work can be easily extended to the broader class of symbolic neural networks to which the polynomial neural network belongs.
Deep User Identification Model with Multiple Biometrics
Sep 03, 2019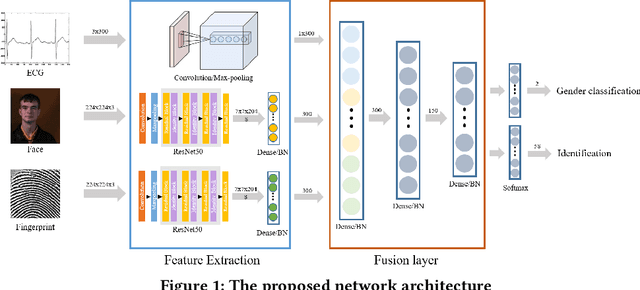
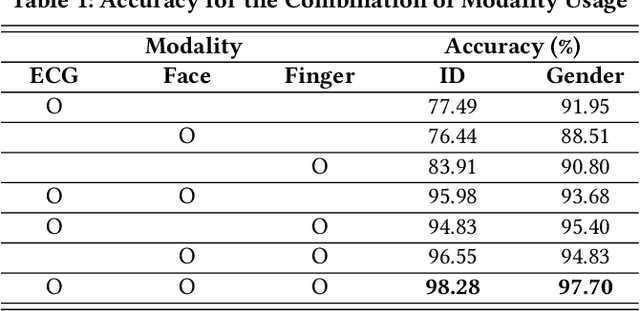
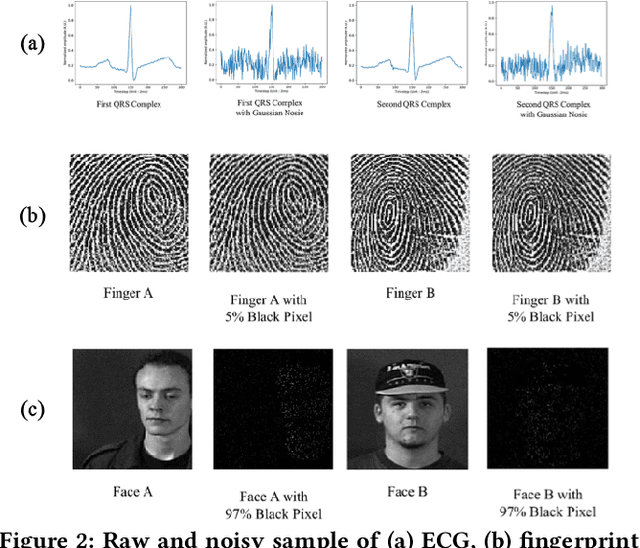

Identification using biometrics is an important yet challenging task. Abundant research has been conducted on identifying personal identity or gender using given signals. Various types of biometrics such as electrocardiogram (ECG), electroencephalogram (EEG), face, fingerprint, and voice have been used for these tasks. Most research has only focused on single modality or a single task, while the combination of input modality or tasks is yet to be investigated. In this paper, we propose deep identification and gender classification using multimodal biometrics. Our model uses ECG, fingerprint, and facial data. It then performs two tasks: gender identification and classification. By engaging multi-modality, a single model can handle various input domains without training each modality independently, and the correlation between domains can increase its generalization performance on the tasks.