 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntity-level Factual Adaptiveness of Fine-tuning based Abstractive Summarization Models
Paper and Code

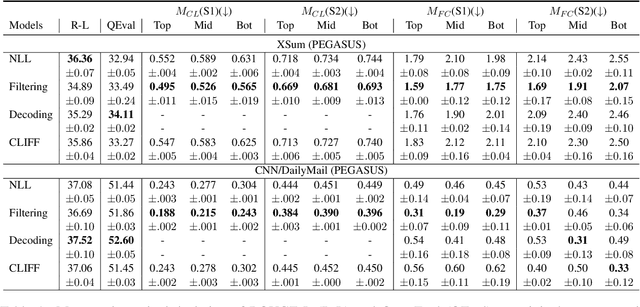
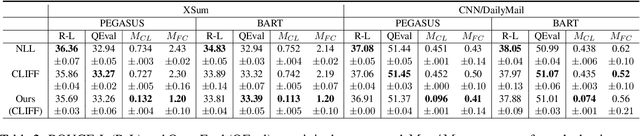
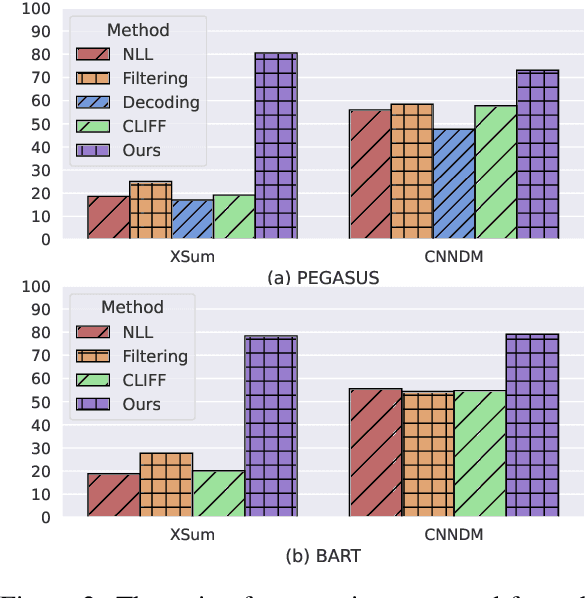
Abstractive summarization models often generate factually inconsistent content particularly when the parametric knowledge of the model conflicts with the knowledge in the input document. In this paper, we analyze the robustness of fine-tuning based summarization models to the knowledge conflict, which we call factual adaptiveness. We utilize pre-trained language models to construct evaluation sets and find that factual adaptiveness is not strongly correlated with factual consistency on original datasets. Furthermore, we introduce a controllable counterfactual data augmentation method where the degree of knowledge conflict within the augmented data can be adjustable. Our experimental results on two pre-trained language models (PEGASUS and BART) and two fine-tuning datasets (XSum and CNN/DailyMail) demonstrate that our method enhances factual adaptiveness while achieving factual consistency on original datasets on par with the contrastive learning baseline.