 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep User Identification Model with Multiple Biometrics
Sep 03, 2019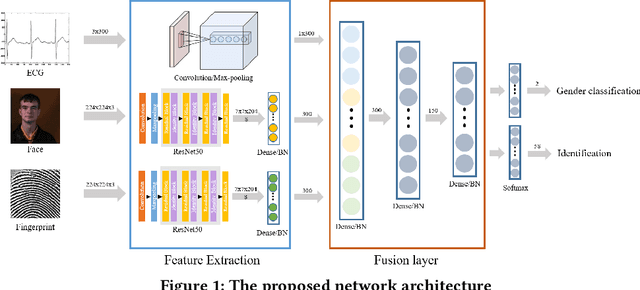
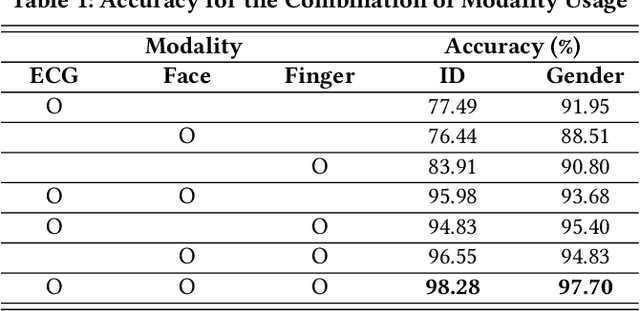
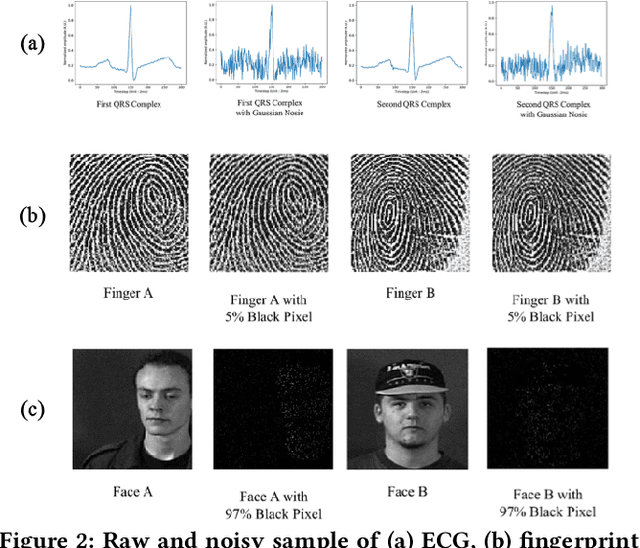

Identification using biometrics is an important yet challenging task. Abundant research has been conducted on identifying personal identity or gender using given signals. Various types of biometrics such as electrocardiogram (ECG), electroencephalogram (EEG), face, fingerprint, and voice have been used for these tasks. Most research has only focused on single modality or a single task, while the combination of input modality or tasks is yet to be investigated. In this paper, we propose deep identification and gender classification using multimodal biometrics. Our model uses ECG, fingerprint, and facial data. It then performs two tasks: gender identification and classification. By engaging multi-modality, a single model can handle various input domains without training each modality independently, and the correlation between domains can increase its generalization performance on the tasks.
Effective Network Compression Using Simulation-Guided Iterative Pruning
Feb 12, 2019

Existing high-performance deep learning models require very intensive computing. For this reason, it is difficult to embed a deep learning model into a system with limited resources. In this paper, we propose the novel idea of the network compression as a method to solve this limitation. The principle of this idea is to make iterative pruning more effective and sophisticated by simulating the reduced network. A simple experiment was conducted to evaluate the method; the results showed that the proposed method achieved higher performance than existing methods at the same pruning level.
End-to-end Multimodal Emotion and Gender Recognition with Dynamic Joint Loss Weights
Oct 02, 2018


Multi-task learning is a method for improving the generalizability of multiple tasks. In order to perform multiple classification tasks with one neural network model, the losses of each task should be combined. Previous studies have mostly focused on multiple prediction tasks using joint loss with static weights for training models, choosing the weights between tasks without making sufficient considerations by setting them uniformly or empirically. In this study, we propose a method to calculate joint loss using dynamic weights to improve the total performance, instead of the individual performance, of tasks. We apply this method to design an end-to-end multimodal emotion and gender recognition model using audio and video data. This approach provides proper weights for the loss of each task when the training process ends. In our experiments, emotion and gender recognition with the proposed method yielded a lower joint loss, which is computed as the negative log-likelihood, than using static weights for joint loss. Moreover, our proposed model has better generalizability than other models. To the best of our knowledge, this research is the first to demonstrate the strength of using dynamic weights for joint loss for maximizing overall performance in emotion and gender recognition tasks.