 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe RoboSense Challenge: Sense Anything, Navigate Anywhere, Adapt Across Platforms
Jan 08, 2026Autonomous systems are increasingly deployed in open and dynamic environments -- from city streets to aerial and indoor spaces -- where perception models must remain reliable under sensor noise, environmental variation, and platform shifts. However, even state-of-the-art methods often degrade under unseen conditions, highlighting the need for robust and generalizable robot sensing. The RoboSense 2025 Challenge is designed to advance robustness and adaptability in robot perception across diverse sensing scenarios. It unifies five complementary research tracks spanning language-grounded decision making, socially compliant navigation, sensor configuration generalization, cross-view and cross-modal correspondence, and cross-platform 3D perception. Together, these tasks form a comprehensive benchmark for evaluating real-world sensing reliability under domain shifts, sensor failures, and platform discrepancies. RoboSense 2025 provides standardized datasets, baseline models, and unified evaluation protocols, enabling large-scale and reproducible comparison of robust perception methods. The challenge attracted 143 teams from 85 institutions across 16 countries, reflecting broad community engagement. By consolidating insights from 23 winning solutions, this report highlights emerging methodological trends, shared design principles, and open challenges across all tracks, marking a step toward building robots that can sense reliably, act robustly, and adapt across platforms in real-world environments.
ConcreTizer: Model Inversion Attack via Occupancy Classification and Dispersion Control for 3D Point Cloud Restoration
Mar 10, 2025The growing use of 3D point cloud data in autonomous vehicles (AVs) has raised serious privacy concerns, particularly due to the sensitive information that can be extracted from 3D data. While model inversion attacks have been widely studied in the context of 2D data, their application to 3D point clouds remains largely unexplored. To fill this gap, we present the first in-depth study of model inversion attacks aimed at restoring 3D point cloud scenes. Our analysis reveals the unique challenges, the inherent sparsity of 3D point clouds and the ambiguity between empty and non-empty voxels after voxelization, which are further exacerbated by the dispersion of non-empty voxels across feature extractor layers. To address these challenges, we introduce ConcreTizer, a simple yet effective model inversion attack designed specifically for voxel-based 3D point cloud data. ConcreTizer incorporates Voxel Occupancy Classification to distinguish between empty and non-empty voxels and Dispersion-Controlled Supervision to mitigate non-empty voxel dispersion. Extensive experiments on widely used 3D feature extractors and benchmark datasets, such as KITTI and Waymo, demonstrate that ConcreTizer concretely restores the original 3D point cloud scene from disrupted 3D feature data. Our findings highlight both the vulnerability of 3D data to inversion attacks and the urgent need for robust defense strategies.
LabelDistill: Label-guided Cross-modal Knowledge Distillation for Camera-based 3D Object Detection
Jul 14, 2024



Recent advancements in camera-based 3D object detection have introduced cross-modal knowledge distillation to bridge the performance gap with LiDAR 3D detectors, leveraging the precise geometric information in LiDAR point clouds. However, existing cross-modal knowledge distillation methods tend to overlook the inherent imperfections of LiDAR, such as the ambiguity of measurements on distant or occluded objects, which should not be transferred to the image detector. To mitigate these imperfections in LiDAR teacher, we propose a novel method that leverages aleatoric uncertainty-free features from ground truth labels. In contrast to conventional label guidance approaches, we approximate the inverse function of the teacher's head to effectively embed label inputs into feature space. This approach provides additional accurate guidance alongside LiDAR teacher, thereby boosting the performance of the image detector. Additionally, we introduce feature partitioning, which effectively transfers knowledge from the teacher modality while preserving the distinctive features of the student, thereby maximizing the potential of both modalities. Experimental results demonstrate that our approach improves mAP and NDS by 5.1 points and 4.9 points compared to the baseline model, proving the effectiveness of our approach. The code is available at https://github.com/sanmin0312/LabelDistill
Align-to-Distill: Trainable Attention Alignment for Knowledge Distillation in Neural Machine Translation
Mar 03, 2024The advent of scalable deep models and large datasets has improved the performance of Neural Machine Translation. Knowledge Distillation (KD) enhances efficiency by transferring knowledge from a teacher model to a more compact student model. However, KD approaches to Transformer architecture often rely on heuristics, particularly when deciding which teacher layers to distill from. In this paper, we introduce the 'Align-to-Distill' (A2D) strategy, designed to address the feature mapping problem by adaptively aligning student attention heads with their teacher counterparts during training. The Attention Alignment Module in A2D performs a dense head-by-head comparison between student and teacher attention heads across layers, turning the combinatorial mapping heuristics into a learning problem. Our experiments show the efficacy of A2D, demonstrating gains of up to +3.61 and +0.63 BLEU points for WMT-2022 De->Dsb and WMT-2014 En->De, respectively, compared to Transformer baselines.
Predict to Detect: Prediction-guided 3D Object Detection using Sequential Images
Jun 14, 2023Recent camera-based 3D object detection methods have introduced sequential frames to improve the detection performance hoping that multiple frames would mitigate the large depth estimation error. Despite improved detection performance, prior works rely on naive fusion methods (e.g., concatenation) or are limited to static scenes (e.g., temporal stereo), neglecting the importance of the motion cue of objects. These approaches do not fully exploit the potential of sequential images and show limited performance improvements. To address this limitation, we propose a novel 3D object detection model, P2D (Predict to Detect), that integrates a prediction scheme into a detection framework to explicitly extract and leverage motion features. P2D predicts object information in the current frame using solely past frames to learn temporal motion features. We then introduce a novel temporal feature aggregation method that attentively exploits Bird's-Eye-View (BEV) features based on predicted object information, resulting in accurate 3D object detection. Experimental results demonstrate that P2D improves mAP and NDS by 3.0% and 3.7% compared to the sequential image-based baseline, illustrating that incorporating a prediction scheme can significantly improve detection accuracy.
CRN: Camera Radar Net for Accurate, Robust, Efficient 3D Perception
Apr 03, 2023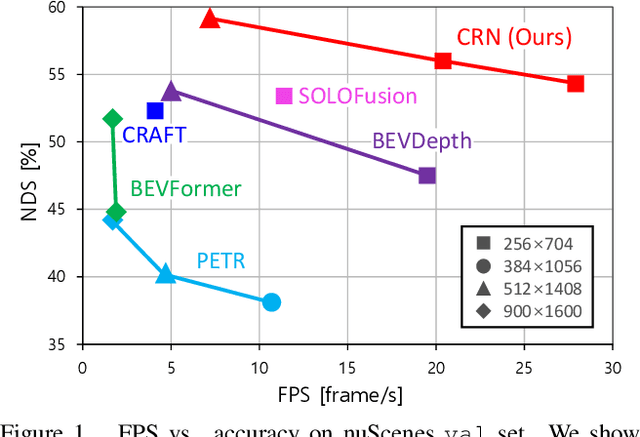
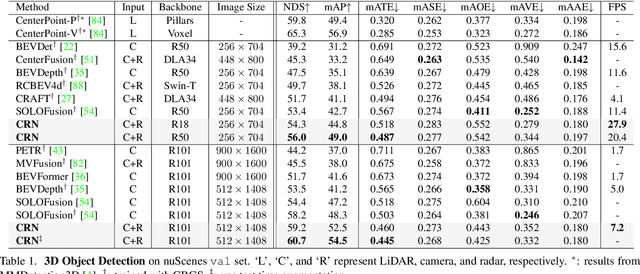
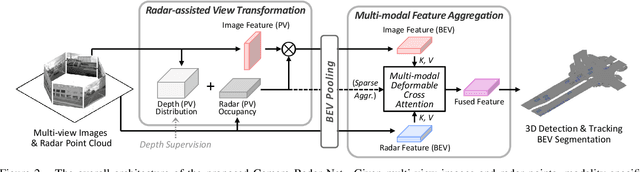
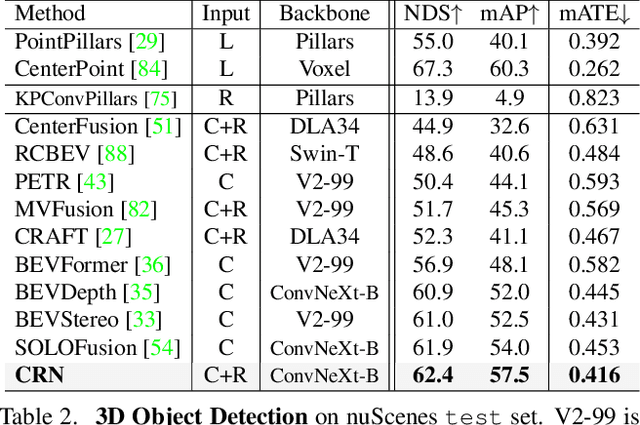
Autonomous driving requires an accurate and fast 3D perception system that includes 3D object detection, tracking, and segmentation. Although recent low-cost camera-based approaches have shown promising results, they are susceptible to poor illumination or bad weather conditions and have a large localization error. Hence, fusing camera with low-cost radar, which provides precise long-range measurement and operates reliably in all environments, is promising but has not yet been thoroughly investigated. In this paper, we propose Camera Radar Net (CRN), a novel camera-radar fusion framework that generates a semantically rich and spatially accurate bird's-eye-view (BEV) feature map for various tasks. To overcome the lack of spatial information in an image, we transform perspective view image features to BEV with the help of sparse but accurate radar points. We further aggregate image and radar feature maps in BEV using multi-modal deformable attention designed to tackle the spatial misalignment between inputs. CRN with real-time setting operates at 20 FPS while achieving comparable performance to LiDAR detectors on nuScenes, and even outperforms at a far distance on 100m setting. Moreover, CRN with offline setting yields 62.4% NDS, 57.5% mAP on nuScenes test set and ranks first among all camera and camera-radar 3D object detectors.
UpCycling: Semi-supervised 3D Object Detection without Sharing Raw-level Unlabeled Scenes
Nov 22, 2022



Semi-supervised Learning (SSL) has received increasing attention in autonomous driving to relieve enormous burden for 3D annotation. In this paper, we propose UpCycling, a novel SSL framework for 3D object detection with zero additional raw-level point cloud: learning from unlabeled de-identified intermediate features (i.e., smashed data) for privacy preservation. The intermediate features do not require additional computation on autonomous vehicles since they are naturally produced by the inference pipeline. However, augmenting 3D scenes at a feature level turns out to be a critical issue: applying the augmentation methods in the latest semi-supervised 3D object detectors distorts intermediate features, which causes the pseudo-labels to suffer from significant noise. To solve the distortion problem while achieving highly effective SSL, we introduce hybrid pseudo labels, feature-level Ground Truth sampling (F-GT) and Rotation (F-RoT), which safely augment unlabeled multi-type 3D scene features and provide high-quality supervision. We implement UpCycling on two representative 3D object detection models, SECOND-IoU and PV-RCNN, and perform experiments on widely-used datasets (Waymo, KITTI, and Lyft). While preserving privacy with zero raw-point scene, UpCycling significantly outperforms the state-of-the-art SSL methods that utilize raw-point scenes, in both domain adaptation and partial-label scenarios.
Boosting Monocular 3D Object Detection with Object-Centric Auxiliary Depth Supervision
Oct 29, 2022Recent advances in monocular 3D detection leverage a depth estimation network explicitly as an intermediate stage of the 3D detection network. Depth map approaches yield more accurate depth to objects than other methods thanks to the depth estimation network trained on a large-scale dataset. However, depth map approaches can be limited by the accuracy of the depth map, and sequentially using two separated networks for depth estimation and 3D detection significantly increases computation cost and inference time. In this work, we propose a method to boost the RGB image-based 3D detector by jointly training the detection network with a depth prediction loss analogous to the depth estimation task. In this way, our 3D detection network can be supervised by more depth supervision from raw LiDAR points, which does not require any human annotation cost, to estimate accurate depth without explicitly predicting the depth map. Our novel object-centric depth prediction loss focuses on depth around foreground objects, which is important for 3D object detection, to leverage pixel-wise depth supervision in an object-centric manner. Our depth regression model is further trained to predict the uncertainty of depth to represent the 3D confidence of objects. To effectively train the 3D detector with raw LiDAR points and to enable end-to-end training, we revisit the regression target of 3D objects and design a network architecture. Extensive experiments on KITTI and nuScenes benchmarks show that our method can significantly boost the monocular image-based 3D detector to outperform depth map approaches while maintaining the real-time inference speed.
CRAFT: Camera-Radar 3D Object Detection with Spatio-Contextual Fusion Transformer
Sep 14, 2022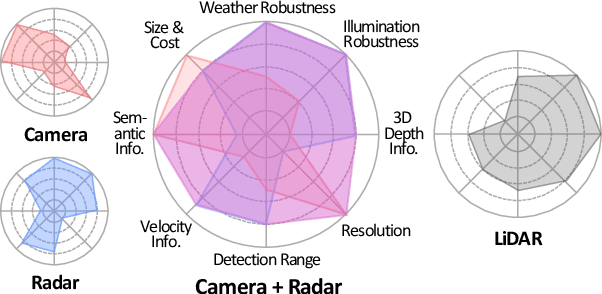
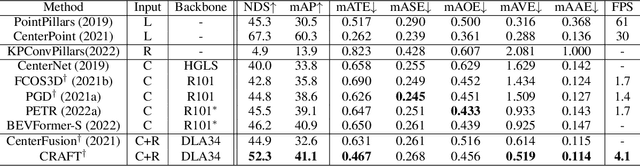
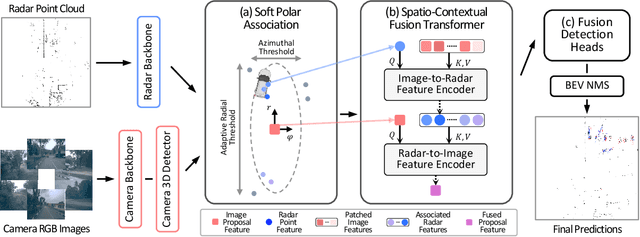

Camera and radar sensors have significant advantages in cost, reliability, and maintenance compared to LiDAR. Existing fusion methods often fuse the outputs of single modalities at the result-level, called the late fusion strategy. This can benefit from using off-the-shelf single sensor detection algorithms, but late fusion cannot fully exploit the complementary properties of sensors, thus having limited performance despite the huge potential of camera-radar fusion. Here we propose a novel proposal-level early fusion approach that effectively exploits both spatial and contextual properties of camera and radar for 3D object detection. Our fusion framework first associates image proposal with radar points in the polar coordinate system to efficiently handle the discrepancy between the coordinate system and spatial properties. Using this as a first stage, following consecutive cross-attention based feature fusion layers adaptively exchange spatio-contextual information between camera and radar, leading to a robust and attentive fusion. Our camera-radar fusion approach achieves the state-of-the-art 41.1% mAP and 52.3% NDS on the nuScenes test set, which is 8.7 and 10.8 points higher than the camera-only baseline, as well as yielding competitive performance on the LiDAR method.
A flexible empirical Bayes approach to multiple linear regression and connections with penalized regression
Aug 23, 2022
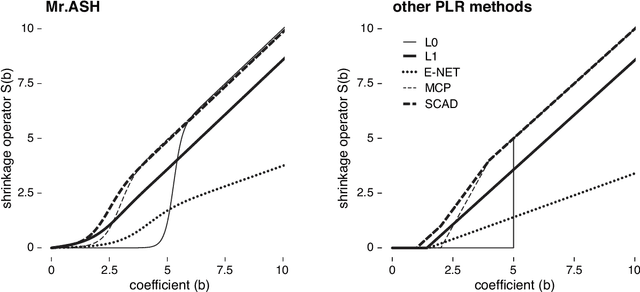

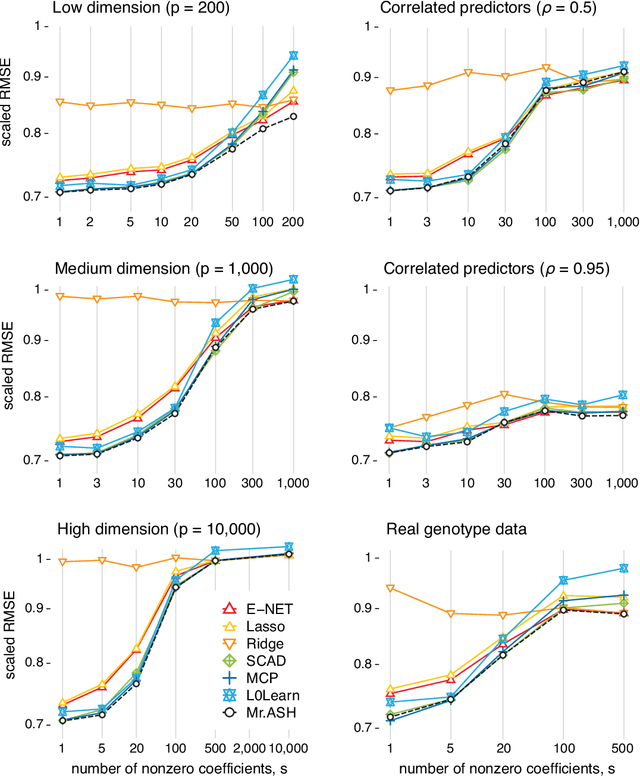
We introduce a new empirical Bayes approach for large-scale multiple linear regression. Our approach combines two key ideas: (i) the use of flexible "adaptive shrinkage" priors, which approximate the nonparametric family of scale mixture of normal distributions by a finite mixture of normal distributions; and (ii) the use of variational approximations to efficiently estimate prior hyperparameters and compute approximate posteriors. Combining these two ideas results in fast and flexible methods, with computational speed comparable to fast penalized regression methods such as the Lasso, and with superior prediction accuracy across a wide range of scenarios. Furthermore, we show that the posterior mean from our method can be interpreted as solving a penalized regression problem, with the precise form of the penalty function being learned from the data by directly solving an optimization problem (rather than being tuned by cross-validation). Our methods are implemented in an R package, mr.ash.alpha, available from https://github.com/stephenslab/mr.ash.alpha