 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCORE: Robust Out-of-Distribution Detection via Confidence and Orthogonal Residual Scoring
Mar 18, 2026Out-of-distribution (OOD) detection is essential for deploying deep learning models reliably, yet no single method performs consistently across architectures and datasets -- a scorer that leads on one benchmark often falters on another. We attribute this inconsistency to a shared structural limitation: logit-based methods see only the classifier's confidence signal, while feature-based methods attempt to measure membership in the training distribution but do so in the full feature space where confidence and membership are entangled, inheriting architecture-sensitive failure modes. We observe that penultimate features naturally decompose into two orthogonal subspaces: a classifier-aligned component encoding confidence, and a residual the classifier discards. We discover that this residual carries a class-specific directional signature for in-distribution data -- a membership signal invisible to logit-based methods and entangled with noise in feature-based methods. We propose CORE (COnfidence + REsidual), which disentangles the two signals by scoring each subspace independently and combines them via normalized summation. Because the two signals are orthogonal by construction, their failure modes are approximately independent, producing robust detection where either view alone is unreliable. CORE achieves competitive or state-of-the-art performance across five architectures and five benchmark configurations, ranking first in three of five settings and achieving the highest grand average AUROC with negligible computational overhead.
Tracking the Discriminative Axis: Dual Prototypes for Test-Time OOD Detection Under Covariate Shift
Mar 17, 2026For reliable deployment of deep-learning systems, out-of-distribution (OOD) detection is indispensable. In the real world, where test-time inputs often arrive as streaming mixtures of in-distribution (ID) and OOD samples under evolving covariate shifts, OOD samples are domain-constrained and bounded by the environment, and both ID and OOD are jointly affected by the same covariate factors. Existing methods typically assume a stationary ID distribution, but this assumption breaks down in such settings, leading to severe performance degradation. We empirically discover that, even under covariate shift, covariate-shifted ID (csID) and OOD (csOOD) samples remain separable along a discriminative axis in feature space. Building on this observation, we propose DART, a test-time, online OOD detection method that dynamically tracks dual prototypes -- one for ID and the other for OOD -- to recover the drifting discriminative axis, augmented with multi-layer fusion and flip correction for robustness. Extensive experiments on a wide range of challenging benchmarks, where all datasets are subjected to 15 common corruption types at severity level 5, demonstrate that our method significantly improves performance, yielding 15.32 percentage points (pp) AUROC gain and 49.15 pp FPR@95TPR reduction on ImageNet-C vs. Textures-C compared to established baselines. These results highlight the potential of the test-time discriminative axis tracking for dependable OOD detection in dynamically changing environments.
ALERT Open Dataset and Input-Size-Agnostic Vision Transformer for Driver Activity Recognition using IR-UWB
Dec 13, 2025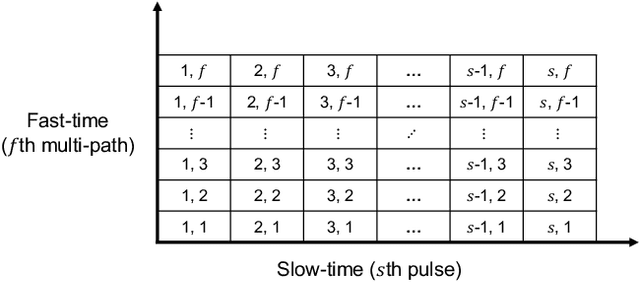
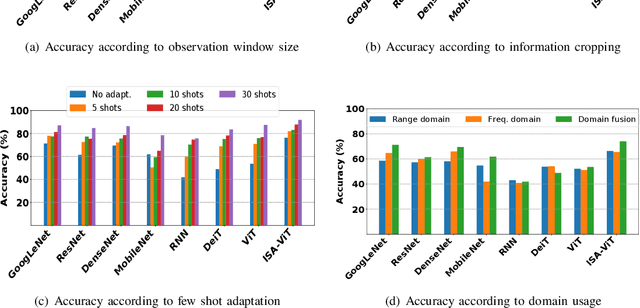
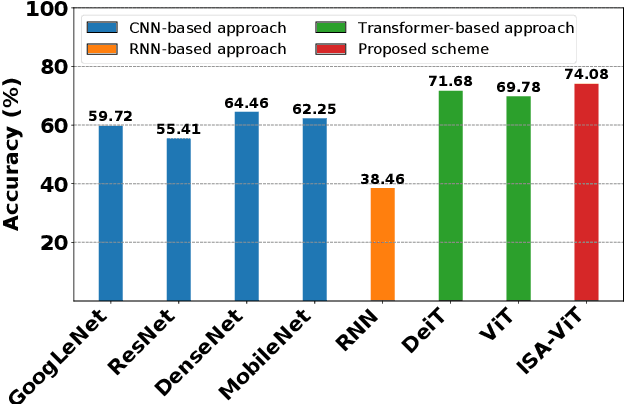
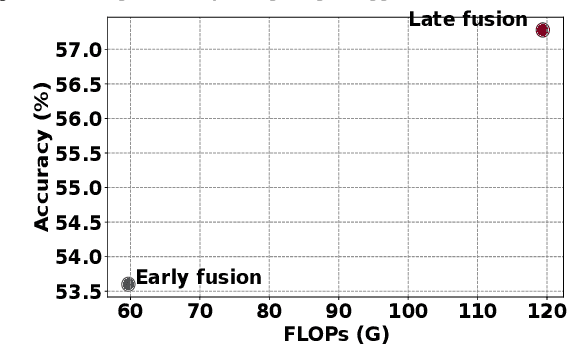
Distracted driving contributes to fatal crashes worldwide. To address this, researchers are using driver activity recognition (DAR) with impulse radio ultra-wideband (IR-UWB) radar, which offers advantages such as interference resistance, low power consumption, and privacy preservation. However, two challenges limit its adoption: the lack of large-scale real-world UWB datasets covering diverse distracted driving behaviors, and the difficulty of adapting fixed-input Vision Transformers (ViTs) to UWB radar data with non-standard dimensions. This work addresses both challenges. We present the ALERT dataset, which contains 10,220 radar samples of seven distracted driving activities collected in real driving conditions. We also propose the input-size-agnostic Vision Transformer (ISA-ViT), a framework designed for radar-based DAR. The proposed method resizes UWB data to meet ViT input requirements while preserving radar-specific information such as Doppler shifts and phase characteristics. By adjusting patch configurations and leveraging pre-trained positional embedding vectors (PEVs), ISA-ViT overcomes the limitations of naive resizing approaches. In addition, a domain fusion strategy combines range- and frequency-domain features to further improve classification performance. Comprehensive experiments demonstrate that ISA-ViT achieves a 22.68% accuracy improvement over an existing ViT-based approach for UWB-based DAR. By publicly releasing the ALERT dataset and detailing our input-size-agnostic strategy, this work facilitates the development of more robust and scalable distracted driving detection systems for real-world deployment.
ConcreTizer: Model Inversion Attack via Occupancy Classification and Dispersion Control for 3D Point Cloud Restoration
Mar 10, 2025The growing use of 3D point cloud data in autonomous vehicles (AVs) has raised serious privacy concerns, particularly due to the sensitive information that can be extracted from 3D data. While model inversion attacks have been widely studied in the context of 2D data, their application to 3D point clouds remains largely unexplored. To fill this gap, we present the first in-depth study of model inversion attacks aimed at restoring 3D point cloud scenes. Our analysis reveals the unique challenges, the inherent sparsity of 3D point clouds and the ambiguity between empty and non-empty voxels after voxelization, which are further exacerbated by the dispersion of non-empty voxels across feature extractor layers. To address these challenges, we introduce ConcreTizer, a simple yet effective model inversion attack designed specifically for voxel-based 3D point cloud data. ConcreTizer incorporates Voxel Occupancy Classification to distinguish between empty and non-empty voxels and Dispersion-Controlled Supervision to mitigate non-empty voxel dispersion. Extensive experiments on widely used 3D feature extractors and benchmark datasets, such as KITTI and Waymo, demonstrate that ConcreTizer concretely restores the original 3D point cloud scene from disrupted 3D feature data. Our findings highlight both the vulnerability of 3D data to inversion attacks and the urgent need for robust defense strategies.
UpCycling: Semi-supervised 3D Object Detection without Sharing Raw-level Unlabeled Scenes
Nov 22, 2022



Semi-supervised Learning (SSL) has received increasing attention in autonomous driving to relieve enormous burden for 3D annotation. In this paper, we propose UpCycling, a novel SSL framework for 3D object detection with zero additional raw-level point cloud: learning from unlabeled de-identified intermediate features (i.e., smashed data) for privacy preservation. The intermediate features do not require additional computation on autonomous vehicles since they are naturally produced by the inference pipeline. However, augmenting 3D scenes at a feature level turns out to be a critical issue: applying the augmentation methods in the latest semi-supervised 3D object detectors distorts intermediate features, which causes the pseudo-labels to suffer from significant noise. To solve the distortion problem while achieving highly effective SSL, we introduce hybrid pseudo labels, feature-level Ground Truth sampling (F-GT) and Rotation (F-RoT), which safely augment unlabeled multi-type 3D scene features and provide high-quality supervision. We implement UpCycling on two representative 3D object detection models, SECOND-IoU and PV-RCNN, and perform experiments on widely-used datasets (Waymo, KITTI, and Lyft). While preserving privacy with zero raw-point scene, UpCycling significantly outperforms the state-of-the-art SSL methods that utilize raw-point scenes, in both domain adaptation and partial-label scenarios.
Bitwidth-Adaptive Quantization-Aware Neural Network Training: A Meta-Learning Approach
Jul 20, 2022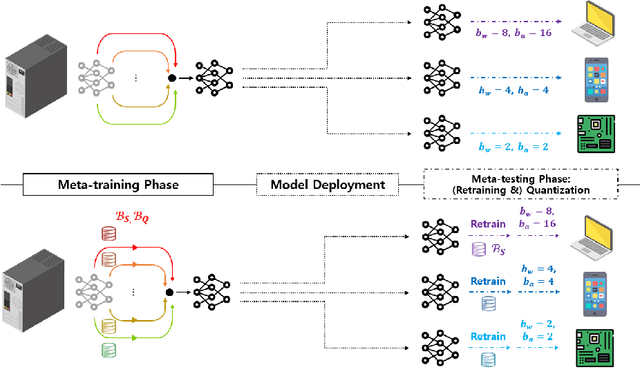



Deep neural network quantization with adaptive bitwidths has gained increasing attention due to the ease of model deployment on various platforms with different resource budgets. In this paper, we propose a meta-learning approach to achieve this goal. Specifically, we propose MEBQAT, a simple yet effective way of bitwidth-adaptive quantization aware training (QAT) where meta-learning is effectively combined with QAT by redefining meta-learning tasks to incorporate bitwidths. After being deployed on a platform, MEBQAT allows the (meta-)trained model to be quantized to any candidate bitwidth then helps to conduct inference without much accuracy drop from quantization. Moreover, with a few-shot learning scenario, MEBQAT can also adapt a model to any bitwidth as well as any unseen target classes by adding conventional optimization or metric-based meta-learning. We design variants of MEBQAT to support both (1) a bitwidth-adaptive quantization scenario and (2) a new few-shot learning scenario where both quantization bitwidths and target classes are jointly adapted. We experimentally demonstrate their validity in multiple QAT schemes. By comparing their performance to (bitwidth-dedicated) QAT, existing bitwidth adaptive QAT and vanilla meta-learning, we find that merging bitwidths into meta-learning tasks achieves a higher level of robustness.