 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgoXtreme: A Dataset for Robust Object Pose Estimation in Egocentric Views under Extreme Conditions
Mar 26, 2026Smart glass is emerging as an useful device since it provides plenty of insights under hands-busy, eyes-on-task situations. To understand the context of the wearer, 6D object pose estimation in egocentric view is becoming essential. However, existing 6D object pose estimation benchmarks fail to capture the challenges of real-world egocentric applications, which are often dominated by severe motion blur, dynamic illumination, and visual obstructions. This discrepancy creates a significant gap between controlled lab data and chaotic real-world application. To bridge this gap, we introduce EgoXtreme, a new large-scale 6D pose estimation dataset captured entirely from an egocentric perspective. EgoXtreme features three challenging scenarios - industrial maintenance, sports, and emergency rescue - designed to introduce severe perceptual ambiguities through extreme lighting, heavy motion blur, and smoke. Evaluations of state-of-the-art generalizable pose estimators on EgoXtreme indicate that their generalization fails to hold in extreme conditions, especially under low light. We further demonstrate that simply applying image restoration (e.g., deblurring) offers no positive improvement for extreme conditions. While performance gain has appeared in tracking-based approach, implying using temporal information in fast-motion scenarios is meaningful. We conclude that EgoXtreme is an essential resource for developing and evaluating the next generation of pose estimation models robust enough for real-world egocentric vision. The dataset and code are available at https://taegyoun88.github.io/EgoXtreme/
CORE: Robust Out-of-Distribution Detection via Confidence and Orthogonal Residual Scoring
Mar 18, 2026Out-of-distribution (OOD) detection is essential for deploying deep learning models reliably, yet no single method performs consistently across architectures and datasets -- a scorer that leads on one benchmark often falters on another. We attribute this inconsistency to a shared structural limitation: logit-based methods see only the classifier's confidence signal, while feature-based methods attempt to measure membership in the training distribution but do so in the full feature space where confidence and membership are entangled, inheriting architecture-sensitive failure modes. We observe that penultimate features naturally decompose into two orthogonal subspaces: a classifier-aligned component encoding confidence, and a residual the classifier discards. We discover that this residual carries a class-specific directional signature for in-distribution data -- a membership signal invisible to logit-based methods and entangled with noise in feature-based methods. We propose CORE (COnfidence + REsidual), which disentangles the two signals by scoring each subspace independently and combines them via normalized summation. Because the two signals are orthogonal by construction, their failure modes are approximately independent, producing robust detection where either view alone is unreliable. CORE achieves competitive or state-of-the-art performance across five architectures and five benchmark configurations, ranking first in three of five settings and achieving the highest grand average AUROC with negligible computational overhead.
Tracking the Discriminative Axis: Dual Prototypes for Test-Time OOD Detection Under Covariate Shift
Mar 17, 2026For reliable deployment of deep-learning systems, out-of-distribution (OOD) detection is indispensable. In the real world, where test-time inputs often arrive as streaming mixtures of in-distribution (ID) and OOD samples under evolving covariate shifts, OOD samples are domain-constrained and bounded by the environment, and both ID and OOD are jointly affected by the same covariate factors. Existing methods typically assume a stationary ID distribution, but this assumption breaks down in such settings, leading to severe performance degradation. We empirically discover that, even under covariate shift, covariate-shifted ID (csID) and OOD (csOOD) samples remain separable along a discriminative axis in feature space. Building on this observation, we propose DART, a test-time, online OOD detection method that dynamically tracks dual prototypes -- one for ID and the other for OOD -- to recover the drifting discriminative axis, augmented with multi-layer fusion and flip correction for robustness. Extensive experiments on a wide range of challenging benchmarks, where all datasets are subjected to 15 common corruption types at severity level 5, demonstrate that our method significantly improves performance, yielding 15.32 percentage points (pp) AUROC gain and 49.15 pp FPR@95TPR reduction on ImageNet-C vs. Textures-C compared to established baselines. These results highlight the potential of the test-time discriminative axis tracking for dependable OOD detection in dynamically changing environments.
T1: One-to-One Channel-Head Binding for Multivariate Time-Series Imputation
Feb 24, 2026Imputing missing values in multivariate time series remains challenging, especially under diverse missing patterns and heavy missingness. Existing methods suffer from suboptimal performance as corrupted temporal features hinder effective cross-variable information transfer, amplifying reconstruction errors. Robust imputation requires both extracting temporal patterns from sparse observations within each variable and selectively transferring information across variables--yet current approaches excel at one while compromising the other. We introduce T1 (Time series imputation with 1-to-1 channel-head binding), a CNN-Transformer hybrid architecture that achieves robust imputation through Channel-Head Binding--a mechanism creating one-to-one correspondence between CNN channels and attention heads. This design enables selective information transfer: when missingness corrupts certain temporal patterns, their corresponding attention pathways adaptively down-weight based on remaining observable patterns while preserving reliable cross-variable connections through unaffected channels. Experiments on 11 benchmark datasets demonstrate that T1 achieves state-of-the-art performance, reducing MSE by 46% on average compared to the second-best baseline, with particularly strong gains under extreme sparsity (70% missing ratio). The model generalizes to unseen missing patterns without retraining and uses a consistent hyperparameter configuration across all datasets. The code is available at https://github.com/Oppenheimerdinger/T1.
SleepMaMi: A Universal Sleep Foundation Model for Integrating Macro- and Micro-structures
Feb 07, 2026While the shift toward unified foundation models has revolutionized many deep learning domains, sleep medicine remains largely restricted to task-specific models that focus on localized micro-structure features. These approaches often neglect the rich, multi-modal context of Polysomnography (PSG) and fail to capture the global macro-structure of a full night's sleep. To address this, we introduce SleepMaMi , a Sleep Foundation Model engineered to master both hour-long sleep architectures and fine-grained signal morphologies. Our framework utilizes a hierarchical dual-encoder design: a Macro-Encoder to model full-night temporal dependencies and a Micro-Encoder to capture short-term characteristics from biosignals. Macro-Encoder is trained via Demographic-Guided Contrastive Learning, which aligns overnight sleep patterns with objective subject metadata, such as age, sex and BMI to refine global representations. Micro-Encoder is optimized via a hybrid Masked Autoencoder (MAE) and multi-modal contrastive objective. Pre-trained on a massive corpus of $>$20,000 PSG recordings (158K hours),SleepMaMi outperforms existing foundation models across a diverse suite of downstream tasks, demonstrating superior generalizability and label-efficient adaptation for clinical sleep analysis.
From Tokens to Photons: Test-Time Physical Prompting for Vison-Language Models
Dec 14, 2025To extend the application of vision-language models (VLMs) from web images to sensor-mediated physical environments, we propose Multi-View Physical-prompt for Test-Time Adaptation (MVP), a forward-only framework that moves test-time adaptation (TTA) from tokens to photons by treating the camera exposure triangle--ISO, shutter speed, and aperture--as physical prompts. At inference, MVP acquires a library of physical views per scene, selects the top-k sensor settings using a source-affinity score, evaluates each retained view under lightweight digital augmentations, filters the lowest-entropy subset of augmented views, and aggregates predictions with Zero-temperature softmax (i.e., hard voting). This selection-then-vote design is simple, calibration-friendly, and requires no gradients or model modifications. On ImageNet-ES and ImageNet-ES-Diverse, MVP consistently outperforms digital-only TTA on single Auto-Exposure captures, by up to 25.6 percentage points (pp), and delivers up to 3.4 pp additional gains over pipelines that combine conventional sensor control with TTA. MVP remains effective under reduced parameter candidate sets that lower capture latency, demonstrating practicality. These results support the main claim that, beyond post-capture prompting, measurement-time control--selecting and combining real physical views--substantially improves robustness for VLMs.
AI Should Sense Better, Not Just Scale Bigger: Adaptive Sensing as a Paradigm Shift
Jul 10, 2025Current AI advances largely rely on scaling neural models and expanding training datasets to achieve generalization and robustness. Despite notable successes, this paradigm incurs significant environmental, economic, and ethical costs, limiting sustainability and equitable access. Inspired by biological sensory systems, where adaptation occurs dynamically at the input (e.g., adjusting pupil size, refocusing vision)--we advocate for adaptive sensing as a necessary and foundational shift. Adaptive sensing proactively modulates sensor parameters (e.g., exposure, sensitivity, multimodal configurations) at the input level, significantly mitigating covariate shifts and improving efficiency. Empirical evidence from recent studies demonstrates that adaptive sensing enables small models (e.g., EfficientNet-B0) to surpass substantially larger models (e.g., OpenCLIP-H) trained with significantly more data and compute. We (i) outline a roadmap for broadly integrating adaptive sensing into real-world applications spanning humanoid, healthcare, autonomous systems, agriculture, and environmental monitoring, (ii) critically assess technical and ethical integration challenges, and (iii) propose targeted research directions, such as standardized benchmarks, real-time adaptive algorithms, multimodal integration, and privacy-preserving methods. Collectively, these efforts aim to transition the AI community toward sustainable, robust, and equitable artificial intelligence systems.
Frequency Composition for Compressed and Domain-Adaptive Neural Networks
May 27, 2025Modern on-device neural network applications must operate under resource constraints while adapting to unpredictable domain shifts. However, this combined challenge-model compression and domain adaptation-remains largely unaddressed, as prior work has tackled each issue in isolation: compressed networks prioritize efficiency within a fixed domain, whereas large, capable models focus on handling domain shifts. In this work, we propose CoDA, a frequency composition-based framework that unifies compression and domain adaptation. During training, CoDA employs quantization-aware training (QAT) with low-frequency components, enabling a compressed model to selectively learn robust, generalizable features. At test time, it refines the compact model in a source-free manner (i.e., test-time adaptation, TTA), leveraging the full-frequency information from incoming data to adapt to target domains while treating high-frequency components as domain-specific cues. LFC are aligned with the trained distribution, while HFC unique to the target distribution are solely utilized for batch normalization. CoDA can be integrated synergistically into existing QAT and TTA methods. CoDA is evaluated on widely used domain-shift benchmarks, including CIFAR10-C and ImageNet-C, across various model architectures. With significant compression, it achieves accuracy improvements of 7.96%p on CIFAR10-C and 5.37%p on ImageNet-C over the full-precision TTA baseline.
The Others: Naturally Isolating Out-of-Distribution Samples for Robust Open-Set Semi-Supervised Learning
Apr 17, 2025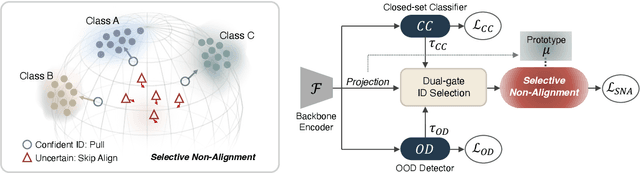
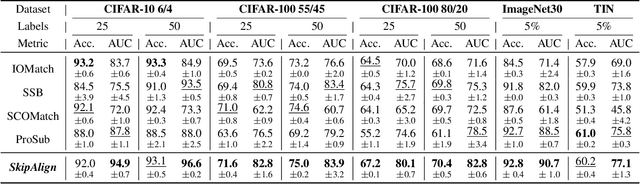
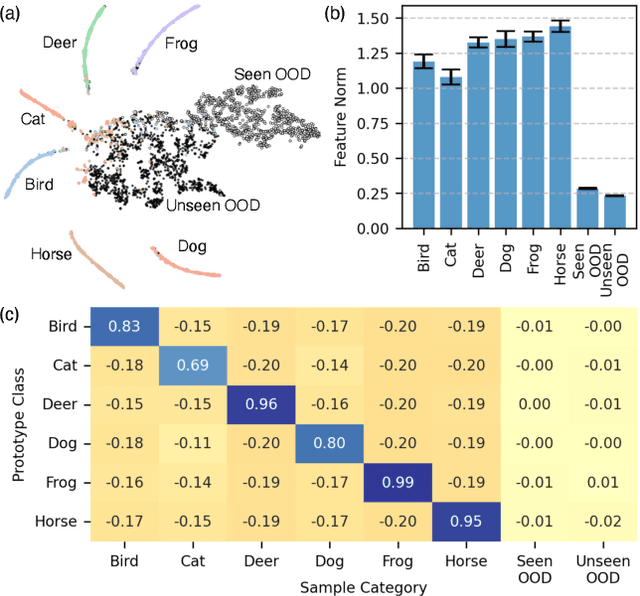
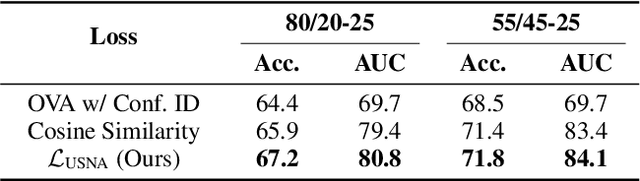
Open-Set Semi-Supervised Learning (OSSL) tackles the practical challenge of learning from unlabeled data that may include both in-distribution (ID) and unknown out-of-distribution (OOD) classes. However, existing OSSL methods form suboptimal feature spaces by either excluding OOD samples, interfering with them, or overtrusting their information during training. In this work, we introduce MagMatch, a novel framework that naturally isolates OOD samples through a prototype-based contrastive learning paradigm. Unlike conventional methods, MagMatch does not assign any prototypes to OOD samples; instead, it selectively aligns ID samples with class prototypes using an ID-Selective Magnetic (ISM) module, while allowing OOD samples - the "others" - to remain unaligned in the feature space. To support this process, we propose Selective Magnetic Alignment (SMA) loss for unlabeled data, which dynamically adjusts alignment based on sample confidence. Extensive experiments on diverse datasets demonstrate that MagMatch significantly outperforms existing methods in both closed-set classification accuracy and OOD detection AUROC, especially in generalizing to unseen OOD data.
A Revisit to the Decoder for Camouflaged Object Detection
Mar 18, 2025

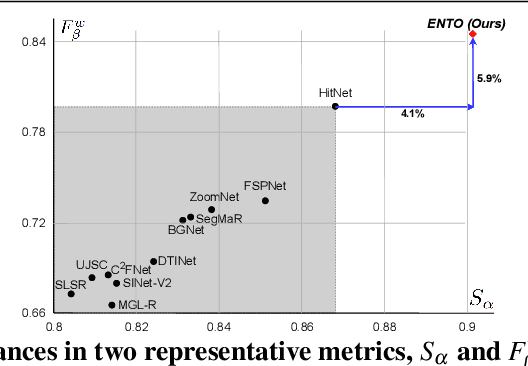
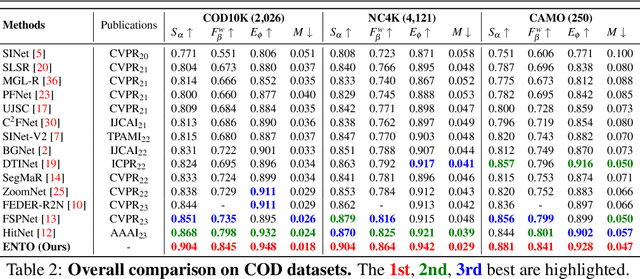
Camouflaged object detection (COD) aims to generate a fine-grained segmentation map of camouflaged objects hidden in their background. Due to the hidden nature of camouflaged objects, it is essential for the decoder to be tailored to effectively extract proper features of camouflaged objects and extra-carefully generate their complex boundaries. In this paper, we propose a novel architecture that augments the prevalent decoding strategy in COD with Enrich Decoder and Retouch Decoder, which help to generate a fine-grained segmentation map. Specifically, the Enrich Decoder amplifies the channels of features that are important for COD using channel-wise attention. Retouch Decoder further refines the segmentation maps by spatially attending to important pixels, such as the boundary regions. With extensive experiments, we demonstrate that ENTO shows superior performance using various encoders, with the two novel components playing their unique roles that are mutually complementary.
* Published in BMVC 2024, 13 pages, 7 figures (Appendix: 5 pages, 2 figures)