 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTracking the Discriminative Axis: Dual Prototypes for Test-Time OOD Detection Under Covariate Shift
Mar 17, 2026For reliable deployment of deep-learning systems, out-of-distribution (OOD) detection is indispensable. In the real world, where test-time inputs often arrive as streaming mixtures of in-distribution (ID) and OOD samples under evolving covariate shifts, OOD samples are domain-constrained and bounded by the environment, and both ID and OOD are jointly affected by the same covariate factors. Existing methods typically assume a stationary ID distribution, but this assumption breaks down in such settings, leading to severe performance degradation. We empirically discover that, even under covariate shift, covariate-shifted ID (csID) and OOD (csOOD) samples remain separable along a discriminative axis in feature space. Building on this observation, we propose DART, a test-time, online OOD detection method that dynamically tracks dual prototypes -- one for ID and the other for OOD -- to recover the drifting discriminative axis, augmented with multi-layer fusion and flip correction for robustness. Extensive experiments on a wide range of challenging benchmarks, where all datasets are subjected to 15 common corruption types at severity level 5, demonstrate that our method significantly improves performance, yielding 15.32 percentage points (pp) AUROC gain and 49.15 pp FPR@95TPR reduction on ImageNet-C vs. Textures-C compared to established baselines. These results highlight the potential of the test-time discriminative axis tracking for dependable OOD detection in dynamically changing environments.
From Tokens to Photons: Test-Time Physical Prompting for Vison-Language Models
Dec 14, 2025To extend the application of vision-language models (VLMs) from web images to sensor-mediated physical environments, we propose Multi-View Physical-prompt for Test-Time Adaptation (MVP), a forward-only framework that moves test-time adaptation (TTA) from tokens to photons by treating the camera exposure triangle--ISO, shutter speed, and aperture--as physical prompts. At inference, MVP acquires a library of physical views per scene, selects the top-k sensor settings using a source-affinity score, evaluates each retained view under lightweight digital augmentations, filters the lowest-entropy subset of augmented views, and aggregates predictions with Zero-temperature softmax (i.e., hard voting). This selection-then-vote design is simple, calibration-friendly, and requires no gradients or model modifications. On ImageNet-ES and ImageNet-ES-Diverse, MVP consistently outperforms digital-only TTA on single Auto-Exposure captures, by up to 25.6 percentage points (pp), and delivers up to 3.4 pp additional gains over pipelines that combine conventional sensor control with TTA. MVP remains effective under reduced parameter candidate sets that lower capture latency, demonstrating practicality. These results support the main claim that, beyond post-capture prompting, measurement-time control--selecting and combining real physical views--substantially improves robustness for VLMs.
MARS2 2025 Challenge on Multimodal Reasoning: Datasets, Methods, Results, Discussion, and Outlook
Sep 17, 2025



This paper reviews the MARS2 2025 Challenge on Multimodal Reasoning. We aim to bring together different approaches in multimodal machine learning and LLMs via a large benchmark. We hope it better allows researchers to follow the state-of-the-art in this very dynamic area. Meanwhile, a growing number of testbeds have boosted the evolution of general-purpose large language models. Thus, this year's MARS2 focuses on real-world and specialized scenarios to broaden the multimodal reasoning applications of MLLMs. Our organizing team released two tailored datasets Lens and AdsQA as test sets, which support general reasoning in 12 daily scenarios and domain-specific reasoning in advertisement videos, respectively. We evaluated 40+ baselines that include both generalist MLLMs and task-specific models, and opened up three competition tracks, i.e., Visual Grounding in Real-world Scenarios (VG-RS), Visual Question Answering with Spatial Awareness (VQA-SA), and Visual Reasoning in Creative Advertisement Videos (VR-Ads). Finally, 76 teams from the renowned academic and industrial institutions have registered and 40+ valid submissions (out of 1200+) have been included in our ranking lists. Our datasets, code sets (40+ baselines and 15+ participants' methods), and rankings are publicly available on the MARS2 workshop website and our GitHub organization page https://github.com/mars2workshop/, where our updates and announcements of upcoming events will be continuously provided.
Frequency Composition for Compressed and Domain-Adaptive Neural Networks
May 27, 2025Modern on-device neural network applications must operate under resource constraints while adapting to unpredictable domain shifts. However, this combined challenge-model compression and domain adaptation-remains largely unaddressed, as prior work has tackled each issue in isolation: compressed networks prioritize efficiency within a fixed domain, whereas large, capable models focus on handling domain shifts. In this work, we propose CoDA, a frequency composition-based framework that unifies compression and domain adaptation. During training, CoDA employs quantization-aware training (QAT) with low-frequency components, enabling a compressed model to selectively learn robust, generalizable features. At test time, it refines the compact model in a source-free manner (i.e., test-time adaptation, TTA), leveraging the full-frequency information from incoming data to adapt to target domains while treating high-frequency components as domain-specific cues. LFC are aligned with the trained distribution, while HFC unique to the target distribution are solely utilized for batch normalization. CoDA can be integrated synergistically into existing QAT and TTA methods. CoDA is evaluated on widely used domain-shift benchmarks, including CIFAR10-C and ImageNet-C, across various model architectures. With significant compression, it achieves accuracy improvements of 7.96%p on CIFAR10-C and 5.37%p on ImageNet-C over the full-precision TTA baseline.
AP-BSN: Self-Supervised Denoising for Real-World Images via Asymmetric PD and Blind-Spot Network
Mar 24, 2022
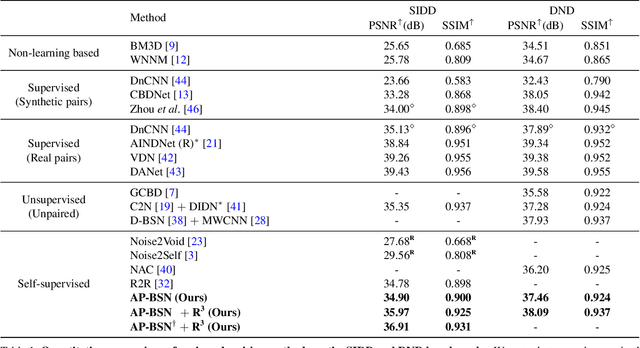
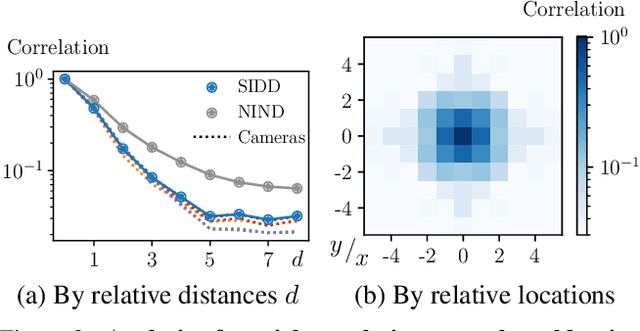

Blind-spot network (BSN) and its variants have made significant advances in self-supervised denoising. Nevertheless, they are still bound to synthetic noisy inputs due to less practical assumptions like pixel-wise independent noise. Hence, it is challenging to deal with spatially correlated real-world noise using self-supervised BSN. Recently, pixel-shuffle downsampling (PD) has been proposed to remove the spatial correlation of real-world noise. However, it is not trivial to integrate PD and BSN directly, which prevents the fully self-supervised denoising model on real-world images. We propose an Asymmetric PD (AP) to address this issue, which introduces different PD stride factors for training and inference. We systematically demonstrate that the proposed AP can resolve inherent trade-offs caused by specific PD stride factors and make BSN applicable to practical scenarios. To this end, we develop AP-BSN, a state-of-the-art self-supervised denoising method for real-world sRGB images. We further propose random-replacing refinement, which significantly improves the performance of our AP-BSN without any additional parameters. Extensive studies demonstrate that our method outperforms the other self-supervised and even unpaired denoising methods by a large margin, without using any additional knowledge, e.g., noise level, regarding the underlying unknown noise.
C2N: Practical Generative Noise Modeling for Real-World Denoising
Feb 19, 2022
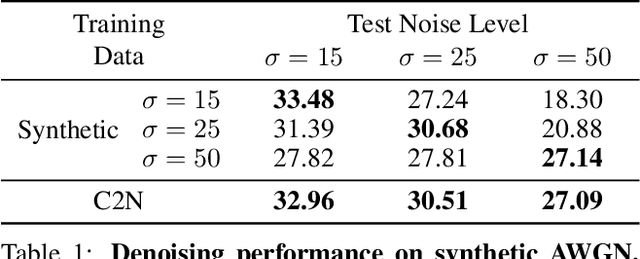
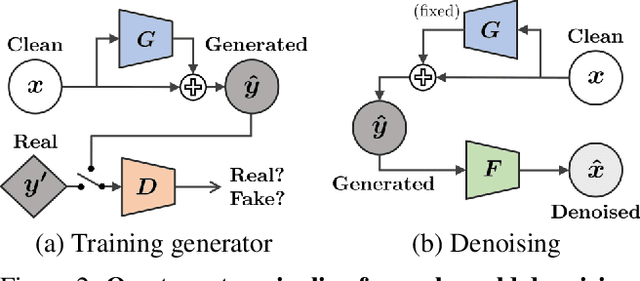

Learning-based image denoising methods have been bounded to situations where well-aligned noisy and clean images are given, or samples are synthesized from predetermined noise models, e.g., Gaussian. While recent generative noise modeling methods aim to simulate the unknown distribution of real-world noise, several limitations still exist. In a practical scenario, a noise generator should learn to simulate the general and complex noise distribution without using paired noisy and clean images. However, since existing methods are constructed on the unrealistic assumption of real-world noise, they tend to generate implausible patterns and cannot express complicated noise maps. Therefore, we introduce a Clean-to-Noisy image generation framework, namely C2N, to imitate complex real-world noise without using any paired examples. We construct the noise generator in C2N accordingly with each component of real-world noise characteristics to express a wide range of noise accurately. Combined with our C2N, conventional denoising CNNs can be trained to outperform existing unsupervised methods on challenging real-world benchmarks by a large margin.