 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSNAP: Low-Latency Test-Time Adaptation with Sparse Updates
Nov 19, 2025Test-Time Adaptation (TTA) adjusts models using unlabeled test data to handle dynamic distribution shifts. However, existing methods rely on frequent adaptation and high computational cost, making them unsuitable for resource-constrained edge environments. To address this, we propose SNAP, a sparse TTA framework that reduces adaptation frequency and data usage while preserving accuracy. SNAP maintains competitive accuracy even when adapting based on only 1% of the incoming data stream, demonstrating its robustness under infrequent updates. Our method introduces two key components: (i) Class and Domain Representative Memory (CnDRM), which identifies and stores a small set of samples that are representative of both class and domain characteristics to support efficient adaptation with limited data; and (ii) Inference-only Batch-aware Memory Normalization (IoBMN), which dynamically adjusts normalization statistics at inference time by leveraging these representative samples, enabling efficient alignment to shifting target domains. Integrated with five state-of-the-art TTA algorithms, SNAP reduces latency by up to 93.12%, while keeping the accuracy drop below 3.3%, even across adaptation rates ranging from 1% to 50%. This demonstrates its strong potential for practical use on edge devices serving latency-sensitive applications. The source code is available at https://github.com/chahh9808/SNAP.
AI Should Sense Better, Not Just Scale Bigger: Adaptive Sensing as a Paradigm Shift
Jul 10, 2025Current AI advances largely rely on scaling neural models and expanding training datasets to achieve generalization and robustness. Despite notable successes, this paradigm incurs significant environmental, economic, and ethical costs, limiting sustainability and equitable access. Inspired by biological sensory systems, where adaptation occurs dynamically at the input (e.g., adjusting pupil size, refocusing vision)--we advocate for adaptive sensing as a necessary and foundational shift. Adaptive sensing proactively modulates sensor parameters (e.g., exposure, sensitivity, multimodal configurations) at the input level, significantly mitigating covariate shifts and improving efficiency. Empirical evidence from recent studies demonstrates that adaptive sensing enables small models (e.g., EfficientNet-B0) to surpass substantially larger models (e.g., OpenCLIP-H) trained with significantly more data and compute. We (i) outline a roadmap for broadly integrating adaptive sensing into real-world applications spanning humanoid, healthcare, autonomous systems, agriculture, and environmental monitoring, (ii) critically assess technical and ethical integration challenges, and (iii) propose targeted research directions, such as standardized benchmarks, real-time adaptive algorithms, multimodal integration, and privacy-preserving methods. Collectively, these efforts aim to transition the AI community toward sustainable, robust, and equitable artificial intelligence systems.
Frequency Composition for Compressed and Domain-Adaptive Neural Networks
May 27, 2025Modern on-device neural network applications must operate under resource constraints while adapting to unpredictable domain shifts. However, this combined challenge-model compression and domain adaptation-remains largely unaddressed, as prior work has tackled each issue in isolation: compressed networks prioritize efficiency within a fixed domain, whereas large, capable models focus on handling domain shifts. In this work, we propose CoDA, a frequency composition-based framework that unifies compression and domain adaptation. During training, CoDA employs quantization-aware training (QAT) with low-frequency components, enabling a compressed model to selectively learn robust, generalizable features. At test time, it refines the compact model in a source-free manner (i.e., test-time adaptation, TTA), leveraging the full-frequency information from incoming data to adapt to target domains while treating high-frequency components as domain-specific cues. LFC are aligned with the trained distribution, while HFC unique to the target distribution are solely utilized for batch normalization. CoDA can be integrated synergistically into existing QAT and TTA methods. CoDA is evaluated on widely used domain-shift benchmarks, including CIFAR10-C and ImageNet-C, across various model architectures. With significant compression, it achieves accuracy improvements of 7.96%p on CIFAR10-C and 5.37%p on ImageNet-C over the full-precision TTA baseline.
Test-Time Adaptation with Binary Feedback
May 24, 2025


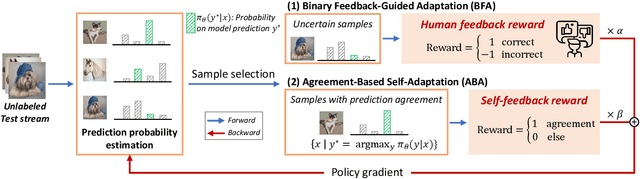
Deep learning models perform poorly when domain shifts exist between training and test data. Test-time adaptation (TTA) is a paradigm to mitigate this issue by adapting pre-trained models using only unlabeled test samples. However, existing TTA methods can fail under severe domain shifts, while recent active TTA approaches requiring full-class labels are impractical due to high labeling costs. To address this issue, we introduce a new setting of TTA with binary feedback. This setting uses a few binary feedback inputs from annotators to indicate whether model predictions are correct, thereby significantly reducing the labeling burden of annotators. Under the setting, we propose BiTTA, a novel dual-path optimization framework that leverages reinforcement learning to balance binary feedback-guided adaptation on uncertain samples with agreement-based self-adaptation on confident predictions. Experiments show BiTTA achieves 13.3%p accuracy improvements over state-of-the-art baselines, demonstrating its effectiveness in handling severe distribution shifts with minimal labeling effort. The source code is available at https://github.com/taeckyung/BiTTA.
Adaptive Camera Sensor for Vision Models
Mar 04, 2025



Domain shift remains a persistent challenge in deep-learning-based computer vision, often requiring extensive model modifications or large labeled datasets to address. Inspired by human visual perception, which adjusts input quality through corrective lenses rather than over-training the brain, we propose Lens, a novel camera sensor control method that enhances model performance by capturing high-quality images from the model's perspective rather than relying on traditional human-centric sensor control. Lens is lightweight and adapts sensor parameters to specific models and scenes in real-time. At its core, Lens utilizes VisiT, a training-free, model-specific quality indicator that evaluates individual unlabeled samples at test time using confidence scores without additional adaptation costs. To validate Lens, we introduce ImageNet-ES Diverse, a new benchmark dataset capturing natural perturbations from varying sensor and lighting conditions. Extensive experiments on both ImageNet-ES and our new ImageNet-ES Diverse show that Lens significantly improves model accuracy across various baseline schemes for sensor control and model modification while maintaining low latency in image captures. Lens effectively compensates for large model size differences and integrates synergistically with model improvement techniques. Our code and dataset are available at github.com/Edw2n/Lens.git.
DEX: Data Channel Extension for Efficient CNN Inference on Tiny AI Accelerators
Dec 09, 2024Tiny machine learning (TinyML) aims to run ML models on small devices and is increasingly favored for its enhanced privacy, reduced latency, and low cost. Recently, the advent of tiny AI accelerators has revolutionized the TinyML field by significantly enhancing hardware processing power. These accelerators, equipped with multiple parallel processors and dedicated per-processor memory instances, offer substantial performance improvements over traditional microcontroller units (MCUs). However, their limited data memory often necessitates downsampling input images, resulting in accuracy degradation. To address this challenge, we propose Data channel EXtension (DEX), a novel approach for efficient CNN execution on tiny AI accelerators. DEX incorporates additional spatial information from original images into input images through patch-wise even sampling and channel-wise stacking, effectively extending data across input channels. By leveraging underutilized processors and data memory for channel extension, DEX facilitates parallel execution without increasing inference latency. Our evaluation with four models and four datasets on tiny AI accelerators demonstrates that this simple idea improves accuracy on average by 3.5%p while keeping the inference latency the same on the AI accelerator. The source code is available at https://github.com/Nokia-Bell-Labs/data-channel-extension.
By My Eyes: Grounding Multimodal Large Language Models with Sensor Data via Visual Prompting
Jul 15, 2024



Large language models (LLMs) have demonstrated exceptional abilities across various domains. However, utilizing LLMs for ubiquitous sensing applications remains challenging as existing text-prompt methods show significant performance degradation when handling long sensor data sequences. We propose a visual prompting approach for sensor data using multimodal LLMs (MLLMs). We design a visual prompt that directs MLLMs to utilize visualized sensor data alongside the target sensory task descriptions. Additionally, we introduce a visualization generator that automates the creation of optimal visualizations tailored to a given sensory task, eliminating the need for prior task-specific knowledge. We evaluated our approach on nine sensory tasks involving four sensing modalities, achieving an average of 10% higher accuracy than text-based prompts and reducing token costs by 15.8x. Our findings highlight the effectiveness and cost-efficiency of visual prompts with MLLMs for various sensory tasks.
AETTA: Label-Free Accuracy Estimation for Test-Time Adaptation
Apr 01, 2024



Test-time adaptation (TTA) has emerged as a viable solution to adapt pre-trained models to domain shifts using unlabeled test data. However, TTA faces challenges of adaptation failures due to its reliance on blind adaptation to unknown test samples in dynamic scenarios. Traditional methods for out-of-distribution performance estimation are limited by unrealistic assumptions in the TTA context, such as requiring labeled data or re-training models. To address this issue, we propose AETTA, a label-free accuracy estimation algorithm for TTA. We propose the prediction disagreement as the accuracy estimate, calculated by comparing the target model prediction with dropout inferences. We then improve the prediction disagreement to extend the applicability of AETTA under adaptation failures. Our extensive evaluation with four baselines and six TTA methods demonstrates that AETTA shows an average of 19.8%p more accurate estimation compared with the baselines. We further demonstrate the effectiveness of accuracy estimation with a model recovery case study, showcasing the practicality of our model recovery based on accuracy estimation. The source code is available at https://github.com/taeckyung/AETTA.
SoTTA: Robust Test-Time Adaptation on Noisy Data Streams
Oct 16, 2023



Test-time adaptation (TTA) aims to address distributional shifts between training and testing data using only unlabeled test data streams for continual model adaptation. However, most TTA methods assume benign test streams, while test samples could be unexpectedly diverse in the wild. For instance, an unseen object or noise could appear in autonomous driving. This leads to a new threat to existing TTA algorithms; we found that prior TTA algorithms suffer from those noisy test samples as they blindly adapt to incoming samples. To address this problem, we present Screening-out Test-Time Adaptation (SoTTA), a novel TTA algorithm that is robust to noisy samples. The key enabler of SoTTA is two-fold: (i) input-wise robustness via high-confidence uniform-class sampling that effectively filters out the impact of noisy samples and (ii) parameter-wise robustness via entropy-sharpness minimization that improves the robustness of model parameters against large gradients from noisy samples. Our evaluation with standard TTA benchmarks with various noisy scenarios shows that our method outperforms state-of-the-art TTA methods under the presence of noisy samples and achieves comparable accuracy to those methods without noisy samples. The source code is available at https://github.com/taeckyung/SoTTA .
LanSER: Language-Model Supported Speech Emotion Recognition
Sep 07, 2023



Speech emotion recognition (SER) models typically rely on costly human-labeled data for training, making scaling methods to large speech datasets and nuanced emotion taxonomies difficult. We present LanSER, a method that enables the use of unlabeled data by inferring weak emotion labels via pre-trained large language models through weakly-supervised learning. For inferring weak labels constrained to a taxonomy, we use a textual entailment approach that selects an emotion label with the highest entailment score for a speech transcript extracted via automatic speech recognition. Our experimental results show that models pre-trained on large datasets with this weak supervision outperform other baseline models on standard SER datasets when fine-tuned, and show improved label efficiency. Despite being pre-trained on labels derived only from text, we show that the resulting representations appear to model the prosodic content of speech.
* Presented at INTERSPEECH 2023