 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanSER: Language-Model Supported Speech Emotion Recognition
Sep 07, 2023



Speech emotion recognition (SER) models typically rely on costly human-labeled data for training, making scaling methods to large speech datasets and nuanced emotion taxonomies difficult. We present LanSER, a method that enables the use of unlabeled data by inferring weak emotion labels via pre-trained large language models through weakly-supervised learning. For inferring weak labels constrained to a taxonomy, we use a textual entailment approach that selects an emotion label with the highest entailment score for a speech transcript extracted via automatic speech recognition. Our experimental results show that models pre-trained on large datasets with this weak supervision outperform other baseline models on standard SER datasets when fine-tuned, and show improved label efficiency. Despite being pre-trained on labels derived only from text, we show that the resulting representations appear to model the prosodic content of speech.
* Presented at INTERSPEECH 2023
Multitask vocal burst modeling with ResNets and pre-trained paralinguistic Conformers
Jun 24, 2022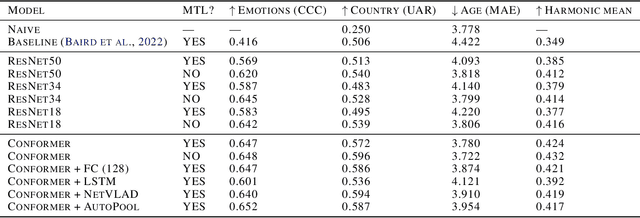
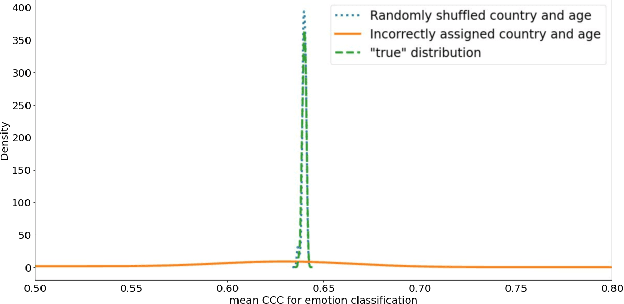
This technical report presents the modeling approaches used in our submission to the ICML Expressive Vocalizations Workshop & Competition multitask track (ExVo-MultiTask). We first applied image classification models of various sizes on mel-spectrogram representations of the vocal bursts, as is standard in sound event detection literature. Results from these models show an increase of 21.24% over the baseline system with respect to the harmonic mean of the task metrics, and comprise our team's main submission to the MultiTask track. We then sought to characterize the headroom in the MultiTask track by applying a large pre-trained Conformer model that previously achieved state-of-the-art results on paralinguistic tasks like speech emotion recognition and mask detection. We additionally investigated the relationship between the sub-tasks of emotional expression, country of origin, and age prediction, and discovered that the best performing models are trained as single-task models, questioning whether the problem truly benefits from a multitask setting.
DISSECT: Disentangled Simultaneous Explanations via Concept Traversals
May 31, 2021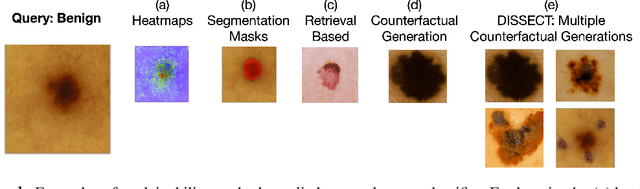


Explaining deep learning model inferences is a promising venue for scientific understanding, improving safety, uncovering hidden biases, evaluating fairness, and beyond, as argued by many scholars. One of the principal benefits of counterfactual explanations is allowing users to explore "what-if" scenarios through what does not and cannot exist in the data, a quality that many other forms of explanation such as heatmaps and influence functions are inherently incapable of doing. However, most previous work on generative explainability cannot disentangle important concepts effectively, produces unrealistic examples, or fails to retain relevant information. We propose a novel approach, DISSECT, that jointly trains a generator, a discriminator, and a concept disentangler to overcome such challenges using little supervision. DISSECT generates Concept Traversals (CTs), defined as a sequence of generated examples with increasing degrees of concepts that influence a classifier's decision. By training a generative model from a classifier's signal, DISSECT offers a way to discover a classifier's inherent "notion" of distinct concepts automatically rather than rely on user-predefined concepts. We show that DISSECT produces CTs that (1) disentangle several concepts, (2) are influential to a classifier's decision and are coupled to its reasoning due to joint training (3), are realistic, (4) preserve relevant information, and (5) are stable across similar inputs. We validate DISSECT on several challenging synthetic and realistic datasets where previous methods fall short of satisfying desirable criteria for interpretability and show that it performs consistently well and better than existing methods. Finally, we present experiments showing applications of DISSECT for detecting potential biases of a classifier and identifying spurious artifacts that impact predictions.
Characterizing Sources of Uncertainty to Proxy Calibration and Disambiguate Annotator and Data Bias
Oct 05, 2019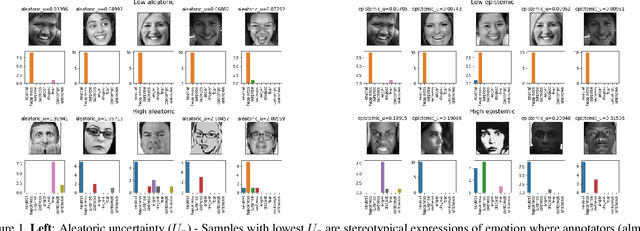
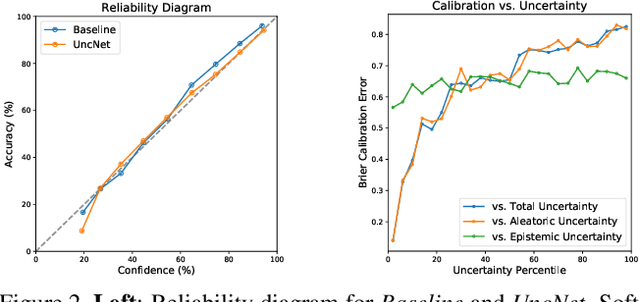

Supporting model interpretability for complex phenomena where annotators can legitimately disagree, such as emotion recognition, is a challenging machine learning task. In this work, we show that explicitly quantifying the uncertainty in such settings has interpretability benefits. We use a simple modification of a classical network inference using Monte Carlo dropout to give measures of epistemic and aleatoric uncertainty. We identify a significant correlation between aleatoric uncertainty and human annotator disagreement ($r\approx.3$). Additionally, we demonstrate how difficult and subjective training samples can be identified using aleatoric uncertainty and how epistemic uncertainty can reveal data bias that could result in unfair predictions. We identify the total uncertainty as a suitable surrogate for model calibration, i.e. the degree we can trust model's predicted confidence. In addition to explainability benefits, we observe modest performance boosts from incorporating model uncertainty.