 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConSensus: Multi-Agent Collaboration for Multimodal Sensing
Jan 10, 2026Large language models (LLMs) are increasingly grounded in sensor data to perceive and reason about human physiology and the physical world. However, accurately interpreting heterogeneous multimodal sensor data remains a fundamental challenge. We show that a single monolithic LLM often fails to reason coherently across modalities, leading to incomplete interpretations and prior-knowledge bias. We introduce ConSensus, a training-free multi-agent collaboration framework that decomposes multimodal sensing tasks into specialized, modality-aware agents. To aggregate agent-level interpretations, we propose a hybrid fusion mechanism that balances semantic aggregation, which enables cross-modal reasoning and contextual understanding, with statistical consensus, which provides robustness through agreement across modalities. While each approach has complementary failure modes, their combination enables reliable inference under sensor noise and missing data. We evaluate ConSensus on five diverse multimodal sensing benchmarks, demonstrating an average accuracy improvement of 7.1% over the single-agent baseline. Furthermore, ConSensus matches or exceeds the performance of iterative multi-agent debate methods while achieving a 12.7 times reduction in average fusion token cost through a single-round hybrid fusion protocol, yielding a robust and efficient solution for real-world multimodal sensing tasks.
Pacer and Runner: Cooperative Learning Framework between Single- and Cross-Domain Sequential Recommendation
Jul 15, 2024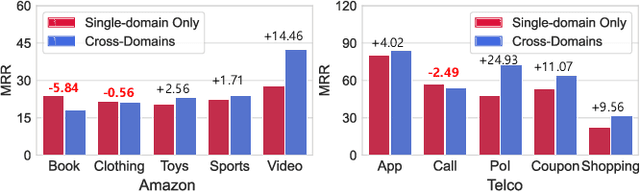
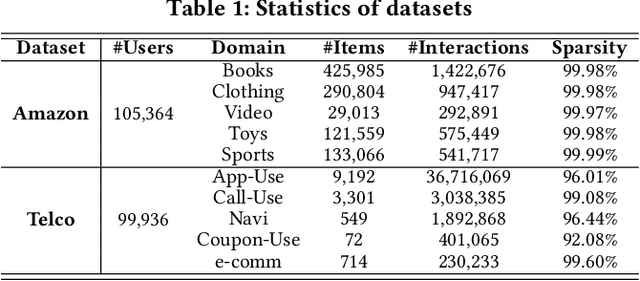
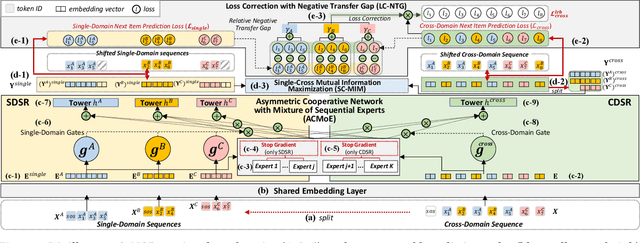
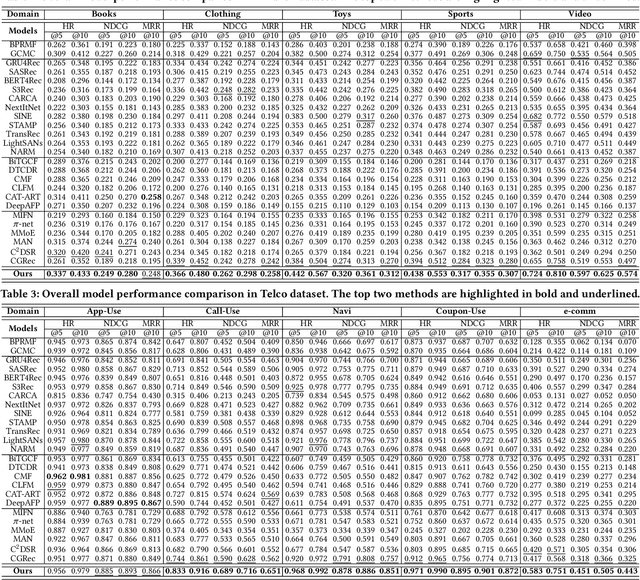
Cross-Domain Sequential Recommendation (CDSR) improves recommendation performance by utilizing information from multiple domains, which contrasts with Single-Domain Sequential Recommendation (SDSR) that relies on a historical interaction within a specific domain. However, CDSR may underperform compared to the SDSR approach in certain domains due to negative transfer, which occurs when there is a lack of relation between domains or different levels of data sparsity. To address the issue of negative transfer, our proposed CDSR model estimates the degree of negative transfer of each domain and adaptively assigns it as a weight factor to the prediction loss, to control gradient flows through domains with significant negative transfer. To this end, our model compares the performance of a model trained on multiple domains (CDSR) with a model trained solely on the specific domain (SDSR) to evaluate the negative transfer of each domain using our asymmetric cooperative network. In addition, to facilitate the transfer of valuable cues between the SDSR and CDSR tasks, we developed an auxiliary loss that maximizes the mutual information between the representation pairs from both tasks on a per-domain basis. This cooperative learning between SDSR and CDSR tasks is similar to the collaborative dynamics between pacers and runners in a marathon. Our model outperformed numerous previous works in extensive experiments on two real-world industrial datasets across ten service domains. We also have deployed our model in the recommendation system of our personal assistant app service, resulting in 21.4% increase in click-through rate compared to existing models, which is valuable to real-world business.
By My Eyes: Grounding Multimodal Large Language Models with Sensor Data via Visual Prompting
Jul 15, 2024



Large language models (LLMs) have demonstrated exceptional abilities across various domains. However, utilizing LLMs for ubiquitous sensing applications remains challenging as existing text-prompt methods show significant performance degradation when handling long sensor data sequences. We propose a visual prompting approach for sensor data using multimodal LLMs (MLLMs). We design a visual prompt that directs MLLMs to utilize visualized sensor data alongside the target sensory task descriptions. Additionally, we introduce a visualization generator that automates the creation of optimal visualizations tailored to a given sensory task, eliminating the need for prior task-specific knowledge. We evaluated our approach on nine sensory tasks involving four sensing modalities, achieving an average of 10% higher accuracy than text-based prompts and reducing token costs by 15.8x. Our findings highlight the effectiveness and cost-efficiency of visual prompts with MLLMs for various sensory tasks.
Cracking the Code of Negative Transfer: A Cooperative Game Theoretic Approach for Cross-Domain Sequential Recommendation
Nov 22, 2023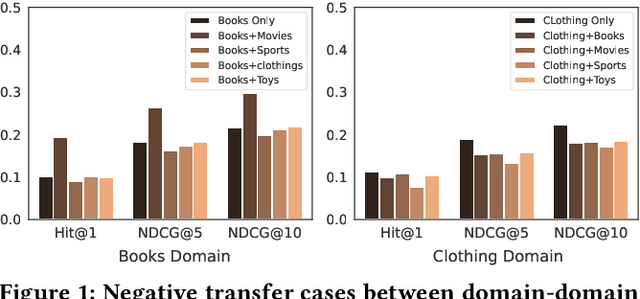

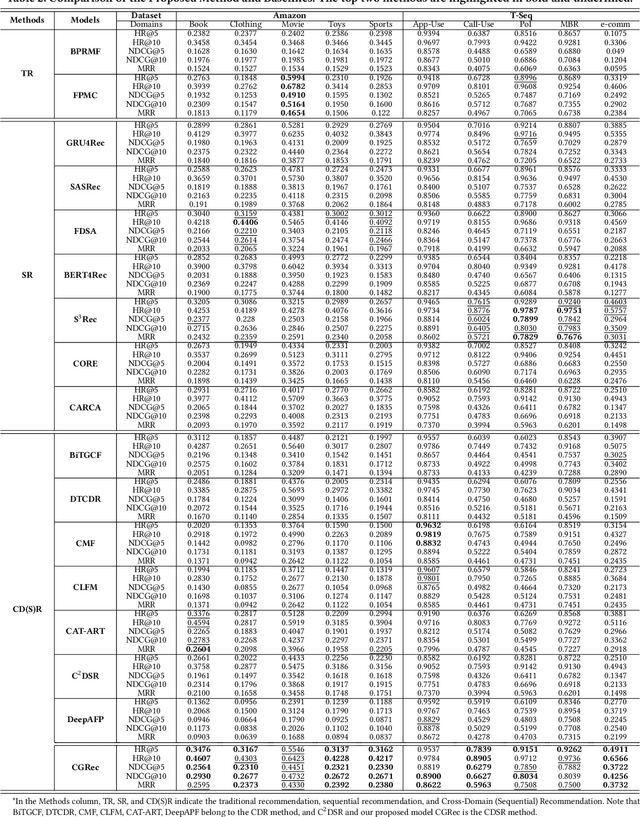
This paper investigates Cross-Domain Sequential Recommendation (CDSR), a promising method that uses information from multiple domains (more than three) to generate accurate and diverse recommendations, and takes into account the sequential nature of user interactions. The effectiveness of these systems often depends on the complex interplay among the multiple domains. In this dynamic landscape, the problem of negative transfer arises, where heterogeneous knowledge between dissimilar domains leads to performance degradation due to differences in user preferences across these domains. As a remedy, we propose a new CDSR framework that addresses the problem of negative transfer by assessing the extent of negative transfer from one domain to another and adaptively assigning low weight values to the corresponding prediction losses. To this end, the amount of negative transfer is estimated by measuring the marginal contribution of each domain to model performance based on a cooperative game theory. In addition, a hierarchical contrastive learning approach that incorporates information from the sequence of coarse-level categories into that of fine-level categories (e.g., item level) when implementing contrastive learning was developed to mitigate negative transfer. Despite the potentially low relevance between domains at the fine-level, there may be higher relevance at the category level due to its generalised and broader preferences. We show that our model is superior to prior works in terms of model performance on two real-world datasets across ten different domains.
FedTherapist: Mental Health Monitoring with User-Generated Linguistic Expressions on Smartphones via Federated Learning
Oct 25, 2023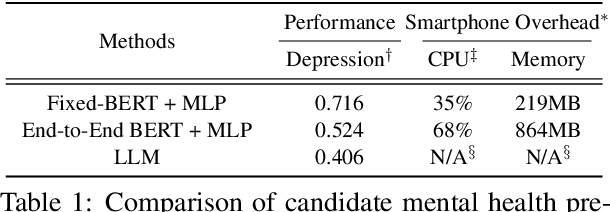
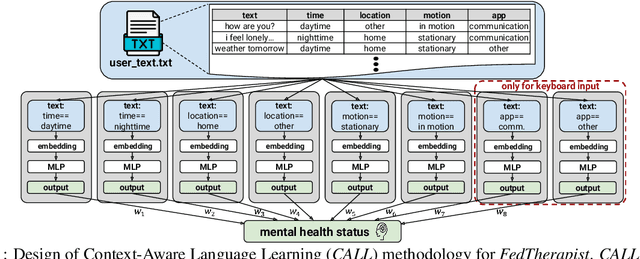
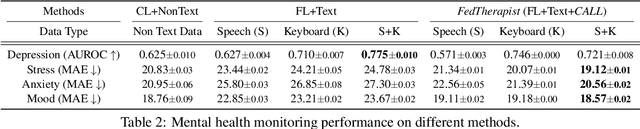
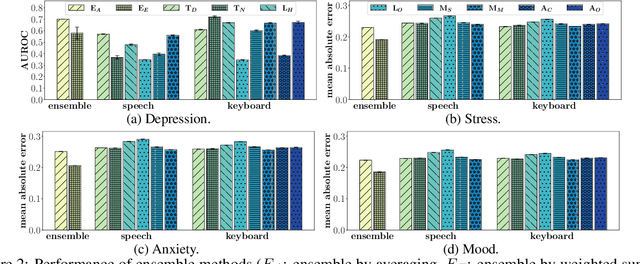
Psychiatrists diagnose mental disorders via the linguistic use of patients. Still, due to data privacy, existing passive mental health monitoring systems use alternative features such as activity, app usage, and location via mobile devices. We propose FedTherapist, a mobile mental health monitoring system that utilizes continuous speech and keyboard input in a privacy-preserving way via federated learning. We explore multiple model designs by comparing their performance and overhead for FedTherapist to overcome the complex nature of on-device language model training on smartphones. We further propose a Context-Aware Language Learning (CALL) methodology to effectively utilize smartphones' large and noisy text for mental health signal sensing. Our IRB-approved evaluation of the prediction of self-reported depression, stress, anxiety, and mood from 46 participants shows higher accuracy of FedTherapist compared with the performance with non-language features, achieving 0.15 AUROC improvement and 8.21% MAE reduction.
IMG2IMU: Applying Knowledge from Large-Scale Images to IMU Applications via Contrastive Learning
Sep 02, 2022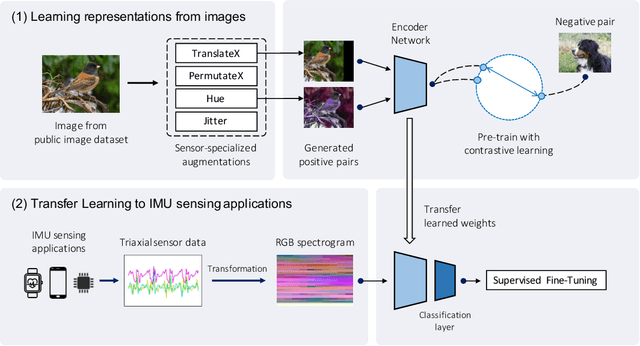



Recent advances in machine learning showed that pre-training representations acquired via self-supervised learning could achieve high accuracy on tasks with small training data. Unlike in vision and natural language processing domains, such pre-training for IMU-based applications is challenging, as there are only a few publicly available datasets with sufficient size and diversity to learn generalizable representations. To overcome this problem, we propose IMG2IMU, a novel approach that adapts pre-train representation from large-scale images to diverse few-shot IMU sensing tasks. We convert the sensor data into visually interpretable spectrograms for the model to utilize the knowledge gained from vision. Further, we apply contrastive learning on an augmentation set we designed to learn representations that are tailored to interpreting sensor data. Our extensive evaluations on five different IMU sensing tasks show that IMG2IMU consistently outperforms the baselines, illustrating that vision knowledge can be incorporated into a few-shot learning environment for IMU sensing tasks.