 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePacer and Runner: Cooperative Learning Framework between Single- and Cross-Domain Sequential Recommendation
Jul 15, 2024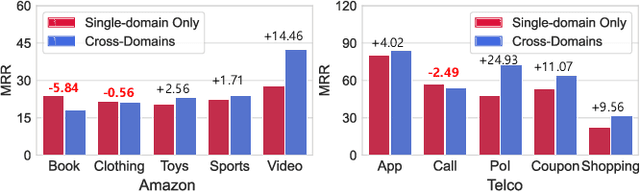
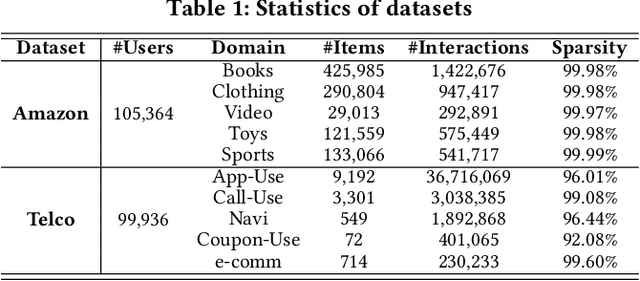
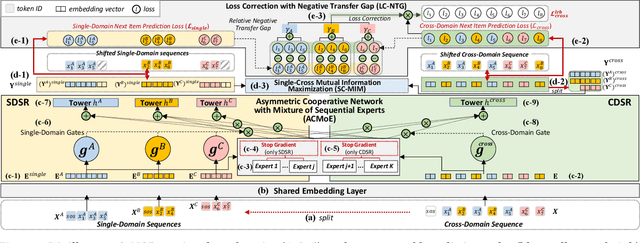
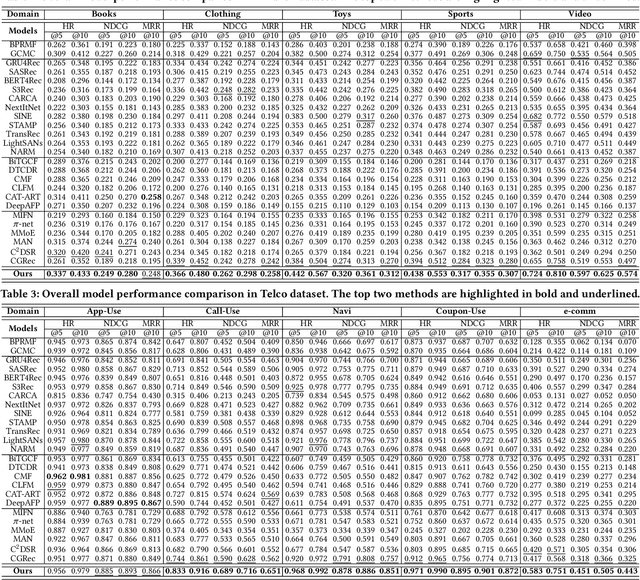
Cross-Domain Sequential Recommendation (CDSR) improves recommendation performance by utilizing information from multiple domains, which contrasts with Single-Domain Sequential Recommendation (SDSR) that relies on a historical interaction within a specific domain. However, CDSR may underperform compared to the SDSR approach in certain domains due to negative transfer, which occurs when there is a lack of relation between domains or different levels of data sparsity. To address the issue of negative transfer, our proposed CDSR model estimates the degree of negative transfer of each domain and adaptively assigns it as a weight factor to the prediction loss, to control gradient flows through domains with significant negative transfer. To this end, our model compares the performance of a model trained on multiple domains (CDSR) with a model trained solely on the specific domain (SDSR) to evaluate the negative transfer of each domain using our asymmetric cooperative network. In addition, to facilitate the transfer of valuable cues between the SDSR and CDSR tasks, we developed an auxiliary loss that maximizes the mutual information between the representation pairs from both tasks on a per-domain basis. This cooperative learning between SDSR and CDSR tasks is similar to the collaborative dynamics between pacers and runners in a marathon. Our model outperformed numerous previous works in extensive experiments on two real-world industrial datasets across ten service domains. We also have deployed our model in the recommendation system of our personal assistant app service, resulting in 21.4% increase in click-through rate compared to existing models, which is valuable to real-world business.
FedGeo: Privacy-Preserving User Next Location Prediction with Federated Learning
Dec 06, 2023



A User Next Location Prediction (UNLP) task, which predicts the next location that a user will move to given his/her trajectory, is an indispensable task for a wide range of applications. Previous studies using large-scale trajectory datasets in a single server have achieved remarkable performance in UNLP task. However, in real-world applications, legal and ethical issues have been raised regarding privacy concerns leading to restrictions against sharing human trajectory datasets to any other server. In response, Federated Learning (FL) has emerged to address the personal privacy issue by collaboratively training multiple clients (i.e., users) and then aggregating them. While previous studies employed FL for UNLP, they are still unable to achieve reliable performance because of the heterogeneity of clients' mobility. To tackle this problem, we propose the Federated Learning for Geographic Information (FedGeo), a FL framework specialized for UNLP, which alleviates the heterogeneity of clients' mobility and guarantees personal privacy protection. Firstly, we incorporate prior global geographic adjacency information to the local client model, since the spatial correlation between locations is trained partially in each client who has only a heterogeneous subset of the overall trajectories in FL. We also introduce a novel aggregation method that minimizes the gap between client models to solve the problem of client drift caused by differences between client models when learning with their heterogeneous data. Lastly, we probabilistically exclude clients with extremely heterogeneous data from the FL process by focusing on clients who visit relatively diverse locations. We show that FedGeo is superior to other FL methods for model performance in UNLP task. We also validated our model in a real-world application using our own customers' mobile phones and the FL agent system.
$t^3$-Variational Autoencoder: Learning Heavy-tailed Data with Student's t and Power Divergence
Dec 02, 2023
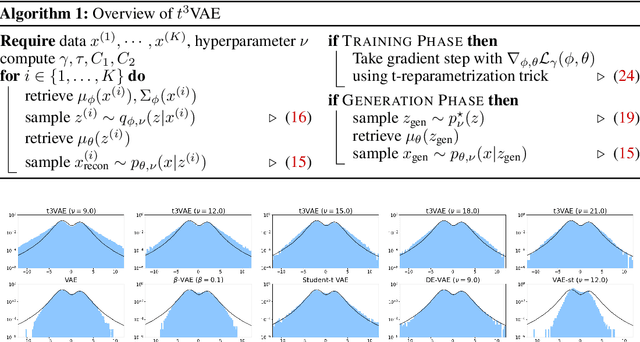


The variational autoencoder (VAE) typically employs a standard normal prior as a regularizer for the probabilistic latent encoder. However, the Gaussian tail often decays too quickly to effectively accommodate the encoded points, failing to preserve crucial structures hidden in the data. In this paper, we explore the use of heavy-tailed models to combat over-regularization. Drawing upon insights from information geometry, we propose $t^3$VAE, a modified VAE framework that incorporates Student's t-distributions for the prior, encoder, and decoder. This results in a joint model distribution of a power form which we argue can better fit real-world datasets. We derive a new objective by reformulating the evidence lower bound as joint optimization of KL divergence between two statistical manifolds and replacing with $\gamma$-power divergence, a natural alternative for power families. $t^3$VAE demonstrates superior generation of low-density regions when trained on heavy-tailed synthetic data. Furthermore, we show that $t^3$VAE significantly outperforms other models on CelebA and imbalanced CIFAR-100 datasets.
Cracking the Code of Negative Transfer: A Cooperative Game Theoretic Approach for Cross-Domain Sequential Recommendation
Nov 22, 2023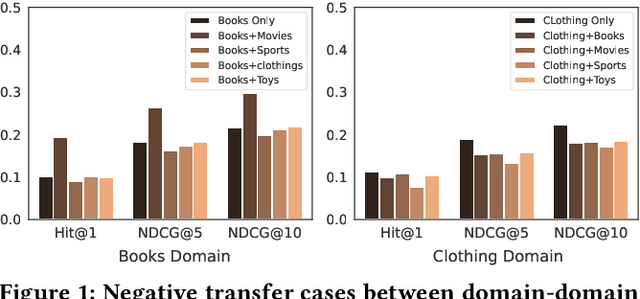
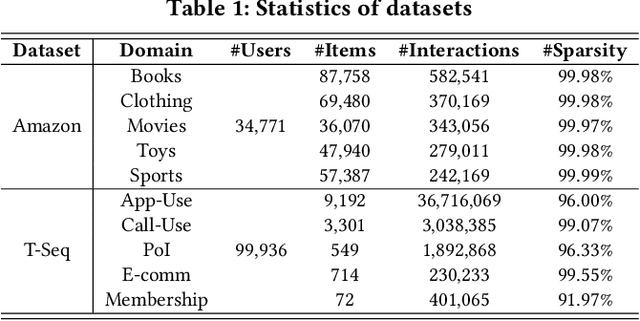

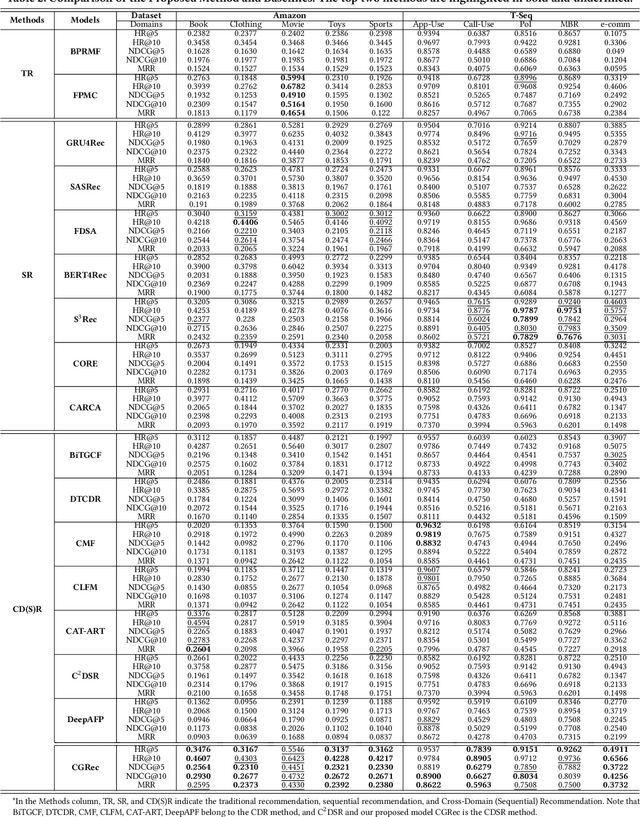
This paper investigates Cross-Domain Sequential Recommendation (CDSR), a promising method that uses information from multiple domains (more than three) to generate accurate and diverse recommendations, and takes into account the sequential nature of user interactions. The effectiveness of these systems often depends on the complex interplay among the multiple domains. In this dynamic landscape, the problem of negative transfer arises, where heterogeneous knowledge between dissimilar domains leads to performance degradation due to differences in user preferences across these domains. As a remedy, we propose a new CDSR framework that addresses the problem of negative transfer by assessing the extent of negative transfer from one domain to another and adaptively assigning low weight values to the corresponding prediction losses. To this end, the amount of negative transfer is estimated by measuring the marginal contribution of each domain to model performance based on a cooperative game theory. In addition, a hierarchical contrastive learning approach that incorporates information from the sequence of coarse-level categories into that of fine-level categories (e.g., item level) when implementing contrastive learning was developed to mitigate negative transfer. Despite the potentially low relevance between domains at the fine-level, there may be higher relevance at the category level due to its generalised and broader preferences. We show that our model is superior to prior works in terms of model performance on two real-world datasets across ten different domains.