 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSharp Capacity Scaling of Spectral Optimizers in Learning Associative Memory
Mar 27, 2026Spectral optimizers such as Muon have recently shown strong empirical performance in large-scale language model training, but the source and extent of their advantage remain poorly understood. We study this question through the linear associative memory problem, a tractable model for factual recall in transformer-based models. In particular, we go beyond orthogonal embeddings and consider Gaussian inputs and outputs, which allows the number of stored associations to greatly exceed the embedding dimension. Our main result sharply characterizes the recovery rates of one step of Muon and SGD on the logistic regression loss under a power law frequency distribution. We show that the storage capacity of Muon significantly exceeds that of SGD, and moreover Muon saturates at a larger critical batch size. We further analyze the multi-step dynamics under a thresholded gradient approximation and show that Muon achieves a substantially faster initial recovery rate than SGD, while both methods eventually converge to the information-theoretic limit at comparable speeds. Experiments on synthetic tasks validate the predicted scaling laws. Our analysis provides a quantitative understanding of the signal amplification of Muon and lays the groundwork for establishing scaling laws across more practical language modeling tasks and optimizers.
Coverage Improvement and Fast Convergence of On-policy Preference Learning
Jan 13, 2026Online on-policy preference learning algorithms for language model alignment such as online direct policy optimization (DPO) can significantly outperform their offline counterparts. We provide a theoretical explanation for this phenomenon by analyzing how the sampling policy's coverage evolves throughout on-policy training. We propose and rigorously justify the \emph{coverage improvement principle}: with sufficient batch size, each update moves into a region around the target where coverage is uniformly better, making subsequent data increasingly informative and enabling rapid convergence. In the contextual bandit setting with Bradley-Terry preferences and linear softmax policy class, we show that on-policy DPO converges exponentially in the number of iterations for batch size exceeding a generalized coverage threshold. In contrast, any learner restricted to offline samples from the initial policy suffers a slower minimax rate, leading to a sharp separation in total sample complexity. Motivated by this analysis, we further propose a simple hybrid sampler based on a novel \emph{preferential} G-optimal design, which removes dependence on coverage and guarantees convergence in just two rounds. Finally, we develop principled on-policy schemes for reward distillation in the general function class setting, and show faster noiseless rates under an alternative deviation-based notion of coverage. Experimentally, we confirm that on-policy DPO and our proposed reward distillation algorithms outperform their off-policy counterparts and enjoy stable, monotonic performance gains across iterations.
OV-MAP : Open-Vocabulary Zero-Shot 3D Instance Segmentation Map for Robots
Jun 13, 2025



We introduce OV-MAP, a novel approach to open-world 3D mapping for mobile robots by integrating open-features into 3D maps to enhance object recognition capabilities. A significant challenge arises when overlapping features from adjacent voxels reduce instance-level precision, as features spill over voxel boundaries, blending neighboring regions together. Our method overcomes this by employing a class-agnostic segmentation model to project 2D masks into 3D space, combined with a supplemented depth image created by merging raw and synthetic depth from point clouds. This approach, along with a 3D mask voting mechanism, enables accurate zero-shot 3D instance segmentation without relying on 3D supervised segmentation models. We assess the effectiveness of our method through comprehensive experiments on public datasets such as ScanNet200 and Replica, demonstrating superior zero-shot performance, robustness, and adaptability across diverse environments. Additionally, we conducted real-world experiments to demonstrate our method's adaptability and robustness when applied to diverse real-world environments.
Mirror Mean-Field Langevin Dynamics
May 05, 2025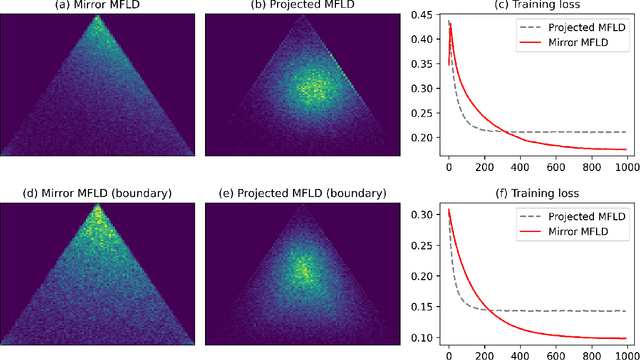
The mean-field Langevin dynamics (MFLD) minimizes an entropy-regularized nonlinear convex functional on the Wasserstein space over $\mathbb{R}^d$, and has gained attention recently as a model for the gradient descent dynamics of interacting particle systems such as infinite-width two-layer neural networks. However, many problems of interest have constrained domains, which are not solved by existing mean-field algorithms due to the global diffusion term. We study the optimization of probability measures constrained to a convex subset of $\mathbb{R}^d$ by proposing the \emph{mirror mean-field Langevin dynamics} (MMFLD), an extension of MFLD to the mirror Langevin framework. We obtain linear convergence guarantees for the continuous MMFLD via a uniform log-Sobolev inequality, and uniform-in-time propagation of chaos results for its time- and particle-discretized counterpart.
Metastable Dynamics of Chain-of-Thought Reasoning: Provable Benefits of Search, RL and Distillation
Feb 02, 2025A key paradigm to improve the reasoning capabilities of large language models (LLMs) is to allocate more inference-time compute to search against a verifier or reward model. This process can then be utilized to refine the pretrained model or distill its reasoning patterns into more efficient models. In this paper, we study inference-time compute by viewing chain-of-thought (CoT) generation as a metastable Markov process: easy reasoning steps (e.g., algebraic manipulations) form densely connected clusters, while hard reasoning steps (e.g., applying a relevant theorem) create sparse, low-probability edges between clusters, leading to phase transitions at longer timescales. Under this framework, we prove that implementing a search protocol that rewards sparse edges improves CoT by decreasing the expected number of steps to reach different clusters. In contrast, we establish a limit on reasoning capability when the model is restricted to local information of the pretrained graph. We also show that the information gained by search can be utilized to obtain a better reasoning model: (1) the pretrained model can be directly finetuned to favor sparse edges via policy gradient methods, and moreover (2) a compressed metastable representation of the reasoning dynamics can be distilled into a smaller, more efficient model.
Optimality and Adaptivity of Deep Neural Features for Instrumental Variable Regression
Jan 09, 2025

We provide a convergence analysis of deep feature instrumental variable (DFIV) regression (Xu et al., 2021), a nonparametric approach to IV regression using data-adaptive features learned by deep neural networks in two stages. We prove that the DFIV algorithm achieves the minimax optimal learning rate when the target structural function lies in a Besov space. This is shown under standard nonparametric IV assumptions, and an additional smoothness assumption on the regularity of the conditional distribution of the covariate given the instrument, which controls the difficulty of Stage 1. We further demonstrate that DFIV, as a data-adaptive algorithm, is superior to fixed-feature (kernel or sieve) IV methods in two ways. First, when the target function possesses low spatial homogeneity (i.e., it has both smooth and spiky/discontinuous regions), DFIV still achieves the optimal rate, while fixed-feature methods are shown to be strictly suboptimal. Second, comparing with kernel-based two-stage regression estimators, DFIV is provably more data efficient in the Stage 1 samples.
Developing Normative Gait Cycle Parameters for Clinical Analysis Using Human Pose Estimation
Nov 20, 2024



Gait analysis using computer vision is an emerging field in AI, offering clinicians an objective, multi-feature approach to analyse complex movements. Despite its promise, current applications using RGB video data alone are limited in measuring clinically relevant spatial and temporal kinematics and establishing normative parameters essential for identifying movement abnormalities within a gait cycle. This paper presents a data-driven method using RGB video data and 2D human pose estimation for developing normative kinematic gait parameters. By analysing joint angles, an established kinematic measure in biomechanics and clinical practice, we aim to enhance gait analysis capabilities and improve explainability. Our cycle-wise kinematic analysis enables clinicians to simultaneously measure and compare multiple joint angles, assessing individuals against a normative population using just monocular RGB video. This approach expands clinical capacity, supports objective decision-making, and automates the identification of specific spatial and temporal deviations and abnormalities within the gait cycle.
Transformers Provably Solve Parity Efficiently with Chain of Thought
Oct 11, 2024



This work provides the first theoretical analysis of training transformers to solve complex problems by recursively generating intermediate states, analogous to fine-tuning for chain-of-thought (CoT) reasoning. We consider training a one-layer transformer to solve the fundamental $k$-parity problem, extending the work on RNNs by Wies et al. (2023). We establish three key results: (1) any finite-precision gradient-based algorithm, without intermediate supervision, requires substantial iterations to solve parity with finite samples. (2) In contrast, when intermediate parities are incorporated into the loss function, our model can learn parity in one gradient update when aided by \emph{teacher forcing}, where ground-truth labels of the reasoning chain are provided at each generation step. (3) Even without teacher forcing, where the model must generate CoT chains end-to-end, parity can be learned efficiently if augmented data is employed to internally verify the soundness of intermediate steps. These results rigorously show that task decomposition and stepwise reasoning naturally arise from optimizing transformers with CoT; moreover, self-consistency checking can improve reasoning ability, aligning with empirical studies of CoT.
Transformers are Minimax Optimal Nonparametric In-Context Learners
Aug 22, 2024


In-context learning (ICL) of large language models has proven to be a surprisingly effective method of learning a new task from only a few demonstrative examples. In this paper, we study the efficacy of ICL from the viewpoint of statistical learning theory. We develop approximation and generalization error bounds for a transformer composed of a deep neural network and one linear attention layer, pretrained on nonparametric regression tasks sampled from general function spaces including the Besov space and piecewise $\gamma$-smooth class. We show that sufficiently trained transformers can achieve -- and even improve upon -- the minimax optimal estimation risk in context by encoding the most relevant basis representations during pretraining. Our analysis extends to high-dimensional or sequential data and distinguishes the \emph{pretraining} and \emph{in-context} generalization gaps. Furthermore, we establish information-theoretic lower bounds for meta-learners w.r.t. both the number of tasks and in-context examples. These findings shed light on the roles of task diversity and representation learning for ICL.
Computer Vision for Clinical Gait Analysis: A Gait Abnormality Video Dataset
Jul 05, 2024



Clinical gait analysis (CGA) using computer vision is an emerging field in artificial intelligence that faces barriers of accessible, real-world data, and clear task objectives. This paper lays the foundation for current developments in CGA as well as vision-based methods and datasets suitable for gait analysis. We introduce The Gait Abnormality in Video Dataset (GAVD) in response to our review of over 150 current gait-related computer vision datasets, which highlighted the need for a large and accessible gait dataset clinically annotated for CGA. GAVD stands out as the largest video gait dataset, comprising 1874 sequences of normal, abnormal and pathological gaits. Additionally, GAVD includes clinically annotated RGB data sourced from publicly available content on online platforms. It also encompasses over 400 subjects who have undergone clinical grade visual screening to represent a diverse range of abnormal gait patterns, captured in various settings, including hospital clinics and urban uncontrolled outdoor environments. We demonstrate the validity of the dataset and utility of action recognition models for CGA using pretrained models Temporal Segment Networks(TSN) and SlowFast network to achieve video abnormality detection of 94% and 92% respectively when tested on GAVD dataset. A GitHub repository https://github.com/Rahmyyy/GAVD consisting of convenient URL links, and clinically relevant annotation for CGA is provided for over 450 online videos, featuring diverse subjects performing a range of normal, pathological, and abnormal gait patterns.