 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Graph Enhanced Memory-Augmented Retrieval for Long Context Modeling
Jun 12, 2026Long-context language modeling requires not only extending context windows but maintaining coherent understanding of entity states and relationships across thousands of tokens -- a challenge that semantic similarity alone cannot address. KGERMAR addresses this by constructing dynamic, context-specific knowledge graphs from input text during inference, enabling domain-adaptive retrieval that leverages both semantic similarity and explicit entity relationships. The framework performs real-time entity and relation extraction to build contextual knowledge graphs, then integrates graph-structural embeddings with textual semantics through a multi-component memory architecture. Three memory banks -- contextual, semantic, and structural -- are maintained with retrieval signals fused via learned weights to capture both surface-level semantics and deeper relational patterns. Evaluated on SlimPajama (84.7K training examples), WikiText-103 (4,358 examples), PG-19 (100 examples), and Proof-pile (46.3K examples), KGERMAR achieves up to 8.5\% lower perplexity and 2--2.5x better memory efficiency than memory-augmented baselines across context lengths from 1K to 32K tokens, with superior in-context learning performance across five NLU tasks. The dynamic knowledge graph construction approach advances memory-augmented language modeling by enabling domain-specific knowledge representation that adapts to input contexts rather than relying on fixed knowledge bases.
TeamUp: Semantic Project Matching and Team Formation for Learning at Scale
May 05, 2026Project-based learning improves student engagement and learning outcomes, yet allocating students to appropriately challenging projects while forming cognitively diverse teams remains difficult at scale. Traditional allocation methods (manual spreadsheets, preference surveys) can't construct the cognitively diverse teams that that collaborate cognitively. This mismatch perpetuates equity issues: high-performing students self-select visible projects while under-represented students face reduced access to opportunity. We propose TeamUp, a lightweight, embedding-based team-forming system designed to improve learning outcomes and equity in large-scale project-based courses. TeamUp uses semantic embeddings from pretrained language models to match students to projects aligned with their skill level. The system employs a hybrid ranking algorithm combining cosine similarity with pedagogical constraints (difficulty alignment, domain preferences, and demand balancing) to generate personalised and transparent recommendations. Beyond individual matching, TeamUp constructs cognitively diverse teams by modelling skill complementarity through embedding variance, ensuring teams possess well-distributed capabilities rather than homogeneous strengths. We evaluated TeamUp through a virtual experiment using 250 student profiles and 60 project descriptions. Results show: (1) substantially higher match quality (mean cosine similarity of 0.74 vs. 0.43); (2) better difficulty alignment (83% placed within one level vs. 34%); (3) more diverse teams (82% covering three or more technical areas vs. 41%); and (4) sub-second recommendation latency at operational costs under $0.10 per student.
Benchmarking Preprocessing and Integration Methods in Single-Cell Genomics
Jan 01, 2026Single-cell data analysis has the potential to revolutionize personalized medicine by characterizing disease-associated molecular changes at the single-cell level. Advanced single-cell multimodal assays can now simultaneously measure various molecules (e.g., DNA, RNA, Protein) across hundreds of thousands of individual cells, providing a comprehensive molecular readout. A significant analytical challenge is integrating single-cell measurements across different modalities. Various methods have been developed to address this challenge, but there has been no systematic evaluation of these techniques with different preprocessing strategies. This study examines a general pipeline for single-cell data analysis, which includes normalization, data integration, and dimensionality reduction. The performance of different algorithm combinations often depends on the dataset sizes and characteristics. We evaluate six datasets across diverse modalities, tissues, and organisms using three metrics: Silhouette Coefficient Score, Adjusted Rand Index, and Calinski-Harabasz Index. Our experiments involve combinations of seven normalization methods, four dimensional reduction methods, and five integration methods. The results show that Seurat and Harmony excel in data integration, with Harmony being more time-efficient, especially for large datasets. UMAP is the most compatible dimensionality reduction method with the integration techniques, and the choice of normalization method varies depending on the integration method used.
TriFlow: A Progressive Multi-Agent Framework for Intelligent Trip Planning
Dec 12, 2025



Real-world trip planning requires transforming open-ended user requests into executable itineraries under strict spatial, temporal, and budgetary constraints while aligning with user preferences. Existing LLM-based agents struggle with constraint satisfaction, tool coordination, and efficiency, often producing infeasible or costly plans. To address these limitations, we present TriFlow, a progressive multi-agent framework that unifies structured reasoning and language-based flexibility through a three-stage pipeline of retrieval, planning, and governance. By this design, TriFlow progressively narrows the search space, assembles constraint-consistent itineraries via rule-LLM collaboration, and performs bounded iterative refinement to ensure global feasibility and personalisation. Evaluations on TravelPlanner and TripTailor benchmarks demonstrated state-of-the-art results, achieving 91.1% and 97% final pass rates, respectively, with over 10x runtime efficiency improvement compared to current SOTA.
Improving Graduate Outcomes by Identifying Skills Gaps and Recommending Courses Based on Career Interests
Nov 12, 2025


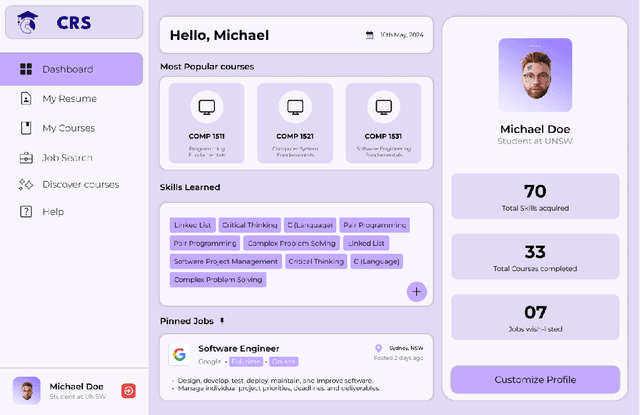
This paper aims to address the challenge of selecting relevant courses for students by proposing the design and development of a course recommendation system. The course recommendation system utilises a combination of data analytics techniques and machine learning algorithms to recommend courses that align with current industry trends and requirements. In order to provide customised suggestions, the study entails the design and implementation of an extensive algorithmic framework that combines machine learning methods, user preferences, and academic criteria. The system employs data mining and collaborative filtering techniques to examine past courses and individual career goals in order to provide course recommendations. Moreover, to improve the accessibility and usefulness of the recommendation system, special attention is given to the development of an easy-to-use front-end interface. The front-end design prioritises visual clarity, interaction, and simplicity through iterative prototyping and user input revisions, guaranteeing a smooth and captivating user experience. We refined and optimised the proposed system by incorporating user feedback, ensuring that it effectively meets the needs and preferences of its target users. The proposed course recommendation system could be a useful tool for students, instructors, and career advisers to use in promoting lifelong learning and professional progression as it fills the gap between university learning and industry expectations. We hope that the proposed course recommendation system will help university students in making data-drive and industry-informed course decisions, in turn, improving graduate outcomes for the university sector.
New Money: A Systematic Review of Synthetic Data Generation for Finance
Oct 30, 2025



Synthetic data generation has emerged as a promising approach to address the challenges of using sensitive financial data in machine learning applications. By leveraging generative models, such as Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs), it is possible to create artificial datasets that preserve the statistical properties of real financial records while mitigating privacy risks and regulatory constraints. Despite the rapid growth of this field, a comprehensive synthesis of the current research landscape has been lacking. This systematic review consolidates and analyses 72 studies published since 2018 that focus on synthetic financial data generation. We categorise the types of financial information synthesised, the generative methods employed, and the evaluation strategies used to assess data utility and privacy. The findings indicate that GAN-based approaches dominate the literature, particularly for generating time-series market data and tabular credit data. While several innovative techniques demonstrate potential for improved realism and privacy preservation, there remains a notable lack of rigorous evaluation of privacy safeguards across studies. By providing an integrated overview of generative techniques, applications, and evaluation methods, this review highlights critical research gaps and offers guidance for future work aimed at developing robust, privacy-preserving synthetic data solutions for the financial domain.
KeyKnowledgeRAG (K^2RAG): An Enhanced RAG method for improved LLM question-answering capabilities
Jul 10, 2025Fine-tuning is an immensely resource-intensive process when retraining Large Language Models (LLMs) to incorporate a larger body of knowledge. Although many fine-tuning techniques have been developed to reduce the time and computational cost involved, the challenge persists as LLMs continue to grow in size and complexity. To address this, a new approach to knowledge expansion in LLMs is needed. Retrieval-Augmented Generation (RAG) offers one such alternative by storing external knowledge in a database and retrieving relevant chunks to support question answering. However, naive implementations of RAG face significant limitations in scalability and answer accuracy. This paper introduces KeyKnowledgeRAG (K2RAG), a novel framework designed to overcome these limitations. Inspired by the divide-and-conquer paradigm, K2RAG integrates dense and sparse vector search, knowledge graphs, and text summarization to improve retrieval quality and system efficiency. The framework also includes a preprocessing step that summarizes the training data, significantly reducing the training time. K2RAG was evaluated using the MultiHopRAG dataset, where the proposed pipeline was trained on the document corpus and tested on a separate evaluation set. Results demonstrated notable improvements over common naive RAG implementations. K2RAG achieved the highest mean answer similarity score of 0.57, and reached the highest third quartile (Q3) similarity of 0.82, indicating better alignment with ground-truth answers. In addition to improved accuracy, the framework proved highly efficient. The summarization step reduced the average training time of individual components by 93%, and execution speed was up to 40% faster than traditional knowledge graph-based RAG systems. K2RAG also demonstrated superior scalability, requiring three times less VRAM than several naive RAG implementations tested in this study.
Automated Unit Test Case Generation: A Systematic Literature Review
Apr 29, 2025Software is omnipresent within all factors of society. It is thus important to ensure that software are well tested to mitigate bad user experiences as well as the potential for severe financial and human losses. Software testing is however expensive and absorbs valuable time and resources. As a result, the field of automated software testing has grown of interest to researchers in past decades. In our review of present and past research papers, we have identified an information gap in the areas of improvement for the Genetic Algorithm and Particle Swarm Optimisation. A gap in knowledge in the current challenges that face automated testing has also been identified. We therefore present this systematic literature review in an effort to consolidate existing knowledge in regards to the evolutionary approaches as well as their improvements and resulting limitations. These improvements include hybrid algorithm combinations as well as interoperability with mutation testing and neural networks. We will also explore the main test criterion that are used in these algorithms alongside the challenges currently faced in the field related to readability, mocking and more.
Long Context Modeling with Ranked Memory-Augmented Retrieval
Mar 19, 2025



Effective long-term memory management is crucial for language models handling extended contexts. We introduce a novel framework that dynamically ranks memory entries based on relevance. Unlike previous works, our model introduces a novel relevance scoring and a pointwise re-ranking model for key-value embeddings, inspired by learning-to-rank techniques in information retrieval. Enhanced Ranked Memory Augmented Retrieval ERMAR achieves state-of-the-art results on standard benchmarks.
Enforcing Consistency and Fairness in Multi-level Hierarchical Classification with a Mask-based Output Layer
Mar 19, 2025Traditional Multi-level Hierarchical Classification (MLHC) classifiers often rely on backbone models with $n$ independent output layers. This structure tends to overlook the hierarchical relationships between classes, leading to inconsistent predictions that violate the underlying taxonomy. Additionally, once a backbone architecture for an MLHC classifier is selected, adapting the model to accommodate new tasks can be challenging. For example, incorporating fairness to protect sensitive attributes within a hierarchical classifier necessitates complex adjustments to maintain the class hierarchy while enforcing fairness constraints. In this paper, we extend this concept to hierarchical classification by introducing a fair, model-agnostic layer designed to enforce taxonomy and optimize specific objectives, including consistency, fairness, and exact match. Our evaluations demonstrate that the proposed layer not only improves the fairness of predictions but also enforces the taxonomy, resulting in consistent predictions and superior performance. Compared to Large Language Models (LLMs) employing in-processing de-biasing techniques and models without any bias correction, our approach achieves better outcomes in both fairness and accuracy, making it particularly valuable in sectors like e-commerce, healthcare, and education, where predictive reliability is crucial.