 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubtyping Breast Lesions via Generative Augmentation based Long-tailed Recognition in Ultrasound
Jul 30, 2025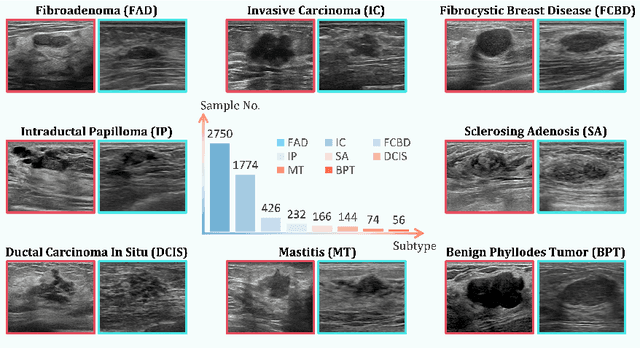
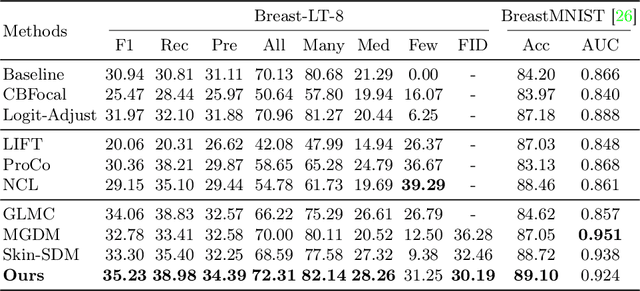
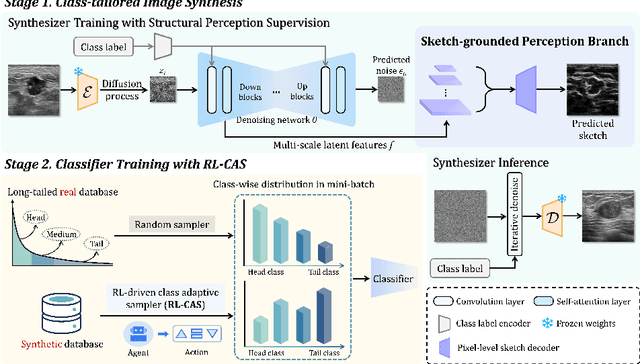
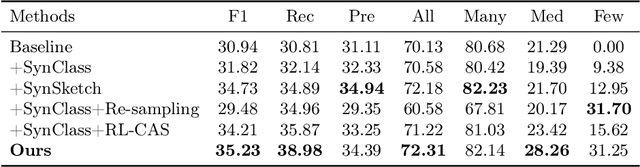
Accurate identification of breast lesion subtypes can facilitate personalized treatment and interventions. Ultrasound (US), as a safe and accessible imaging modality, is extensively employed in breast abnormality screening and diagnosis. However, the incidence of different subtypes exhibits a skewed long-tailed distribution, posing significant challenges for automated recognition. Generative augmentation provides a promising solution to rectify data distribution. Inspired by this, we propose a dual-phase framework for long-tailed classification that mitigates distributional bias through high-fidelity data synthesis while avoiding overuse that corrupts holistic performance. The framework incorporates a reinforcement learning-driven adaptive sampler, dynamically calibrating synthetic-real data ratios by training a strategic multi-agent to compensate for scarcities of real data while ensuring stable discriminative capability. Furthermore, our class-controllable synthetic network integrates a sketch-grounded perception branch that harnesses anatomical priors to maintain distinctive class features while enabling annotation-free inference. Extensive experiments on an in-house long-tailed and a public imbalanced breast US datasets demonstrate that our method achieves promising performance compared to state-of-the-art approaches. More synthetic images can be found at https://github.com/Stinalalala/Breast-LT-GenAug.
KeyKnowledgeRAG (K^2RAG): An Enhanced RAG method for improved LLM question-answering capabilities
Jul 10, 2025Fine-tuning is an immensely resource-intensive process when retraining Large Language Models (LLMs) to incorporate a larger body of knowledge. Although many fine-tuning techniques have been developed to reduce the time and computational cost involved, the challenge persists as LLMs continue to grow in size and complexity. To address this, a new approach to knowledge expansion in LLMs is needed. Retrieval-Augmented Generation (RAG) offers one such alternative by storing external knowledge in a database and retrieving relevant chunks to support question answering. However, naive implementations of RAG face significant limitations in scalability and answer accuracy. This paper introduces KeyKnowledgeRAG (K2RAG), a novel framework designed to overcome these limitations. Inspired by the divide-and-conquer paradigm, K2RAG integrates dense and sparse vector search, knowledge graphs, and text summarization to improve retrieval quality and system efficiency. The framework also includes a preprocessing step that summarizes the training data, significantly reducing the training time. K2RAG was evaluated using the MultiHopRAG dataset, where the proposed pipeline was trained on the document corpus and tested on a separate evaluation set. Results demonstrated notable improvements over common naive RAG implementations. K2RAG achieved the highest mean answer similarity score of 0.57, and reached the highest third quartile (Q3) similarity of 0.82, indicating better alignment with ground-truth answers. In addition to improved accuracy, the framework proved highly efficient. The summarization step reduced the average training time of individual components by 93%, and execution speed was up to 40% faster than traditional knowledge graph-based RAG systems. K2RAG also demonstrated superior scalability, requiring three times less VRAM than several naive RAG implementations tested in this study.
Enforcing Consistency and Fairness in Multi-level Hierarchical Classification with a Mask-based Output Layer
Mar 19, 2025Traditional Multi-level Hierarchical Classification (MLHC) classifiers often rely on backbone models with $n$ independent output layers. This structure tends to overlook the hierarchical relationships between classes, leading to inconsistent predictions that violate the underlying taxonomy. Additionally, once a backbone architecture for an MLHC classifier is selected, adapting the model to accommodate new tasks can be challenging. For example, incorporating fairness to protect sensitive attributes within a hierarchical classifier necessitates complex adjustments to maintain the class hierarchy while enforcing fairness constraints. In this paper, we extend this concept to hierarchical classification by introducing a fair, model-agnostic layer designed to enforce taxonomy and optimize specific objectives, including consistency, fairness, and exact match. Our evaluations demonstrate that the proposed layer not only improves the fairness of predictions but also enforces the taxonomy, resulting in consistent predictions and superior performance. Compared to Large Language Models (LLMs) employing in-processing de-biasing techniques and models without any bias correction, our approach achieves better outcomes in both fairness and accuracy, making it particularly valuable in sectors like e-commerce, healthcare, and education, where predictive reliability is crucial.
Leveraging Taxonomy and LLMs for Improved Multimodal Hierarchical Classification
Jan 12, 2025Multi-level Hierarchical Classification (MLHC) tackles the challenge of categorizing items within a complex, multi-layered class structure. However, traditional MLHC classifiers often rely on a backbone model with independent output layers, which tend to ignore the hierarchical relationships between classes. This oversight can lead to inconsistent predictions that violate the underlying taxonomy. Leveraging Large Language Models (LLMs), we propose a novel taxonomy-embedded transitional LLM-agnostic framework for multimodality classification. The cornerstone of this advancement is the ability of models to enforce consistency across hierarchical levels. Our evaluations on the MEP-3M dataset - a multi-modal e-commerce product dataset with various hierarchical levels - demonstrated a significant performance improvement compared to conventional LLM structures.
Ctrl-GenAug: Controllable Generative Augmentation for Medical Sequence Classification
Sep 25, 2024



In the medical field, the limited availability of large-scale datasets and labor-intensive annotation processes hinder the performance of deep models. Diffusion-based generative augmentation approaches present a promising solution to this issue, having been proven effective in advancing downstream medical recognition tasks. Nevertheless, existing works lack sufficient semantic and sequential steerability for challenging video/3D sequence generation, and neglect quality control of noisy synthesized samples, resulting in unreliable synthetic databases and severely limiting the performance of downstream tasks. In this work, we present Ctrl-GenAug, a novel and general generative augmentation framework that enables highly semantic- and sequential-customized sequence synthesis and suppresses incorrectly synthesized samples, to aid medical sequence classification. Specifically, we first design a multimodal conditions-guided sequence generator for controllably synthesizing diagnosis-promotive samples. A sequential augmentation module is integrated to enhance the temporal/stereoscopic coherence of generated samples. Then, we propose a noisy synthetic data filter to suppress unreliable cases at semantic and sequential levels. Extensive experiments on 3 medical datasets, using 11 networks trained on 3 paradigms, comprehensively analyze the effectiveness and generality of Ctrl-GenAug, particularly in underrepresented high-risk populations and out-domain conditions.
TriAug: Out-of-Distribution Detection for Imbalanced Breast Lesion in Ultrasound
Feb 27, 2024



Different diseases, such as histological subtypes of breast lesions, have severely varying incidence rates. Even trained with substantial amount of in-distribution (ID) data, models often encounter out-of-distribution (OOD) samples belonging to unseen classes in clinical reality. To address this, we propose a novel framework built upon a long-tailed OOD detection task for breast ultrasound images. It is equipped with a triplet state augmentation (TriAug) which improves ID classification accuracy while maintaining a promising OOD detection performance. Meanwhile, we designed a balanced sphere loss to handle the class imbalanced problem. Experimental results show that the model outperforms state-of-art OOD approaches both in ID classification (F1-score=42.12%) and OOD detection (AUROC=78.06%).