 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeT2V-Turbo-v2: Enhancing Video Generation Model Post-Training through Data, Reward, and Conditional Guidance Design
Oct 08, 2024



In this paper, we focus on enhancing a diffusion-based text-to-video (T2V) model during the post-training phase by distilling a highly capable consistency model from a pretrained T2V model. Our proposed method, T2V-Turbo-v2, introduces a significant advancement by integrating various supervision signals, including high-quality training data, reward model feedback, and conditional guidance, into the consistency distillation process. Through comprehensive ablation studies, we highlight the crucial importance of tailoring datasets to specific learning objectives and the effectiveness of learning from diverse reward models for enhancing both the visual quality and text-video alignment. Additionally, we highlight the vast design space of conditional guidance strategies, which centers on designing an effective energy function to augment the teacher ODE solver. We demonstrate the potential of this approach by extracting motion guidance from the training datasets and incorporating it into the ODE solver, showcasing its effectiveness in improving the motion quality of the generated videos with the improved motion-related metrics from VBench and T2V-CompBench. Empirically, our T2V-Turbo-v2 establishes a new state-of-the-art result on VBench, with a Total score of 85.13, surpassing proprietary systems such as Gen-3 and Kling.
Ctrl-GenAug: Controllable Generative Augmentation for Medical Sequence Classification
Sep 25, 2024



In the medical field, the limited availability of large-scale datasets and labor-intensive annotation processes hinder the performance of deep models. Diffusion-based generative augmentation approaches present a promising solution to this issue, having been proven effective in advancing downstream medical recognition tasks. Nevertheless, existing works lack sufficient semantic and sequential steerability for challenging video/3D sequence generation, and neglect quality control of noisy synthesized samples, resulting in unreliable synthetic databases and severely limiting the performance of downstream tasks. In this work, we present Ctrl-GenAug, a novel and general generative augmentation framework that enables highly semantic- and sequential-customized sequence synthesis and suppresses incorrectly synthesized samples, to aid medical sequence classification. Specifically, we first design a multimodal conditions-guided sequence generator for controllably synthesizing diagnosis-promotive samples. A sequential augmentation module is integrated to enhance the temporal/stereoscopic coherence of generated samples. Then, we propose a noisy synthetic data filter to suppress unreliable cases at semantic and sequential levels. Extensive experiments on 3 medical datasets, using 11 networks trained on 3 paradigms, comprehensively analyze the effectiveness and generality of Ctrl-GenAug, particularly in underrepresented high-risk populations and out-domain conditions.
FlexEControl: Flexible and Efficient Multimodal Control for Text-to-Image Generation
May 08, 2024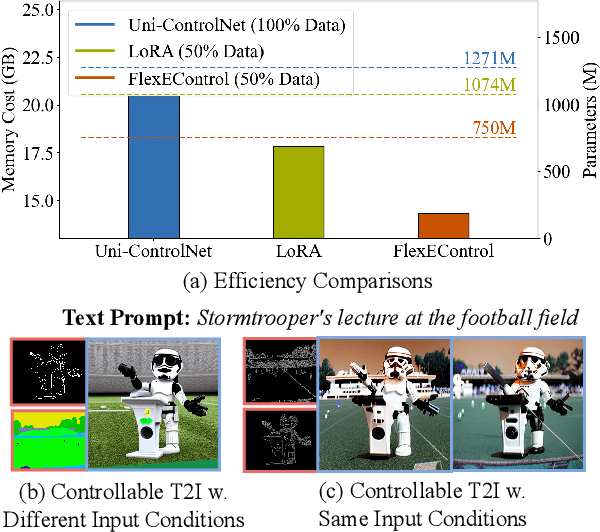

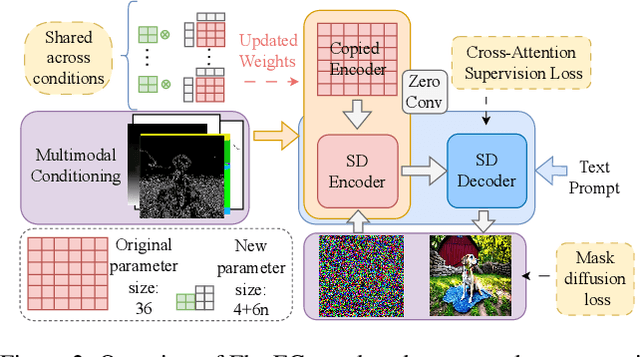
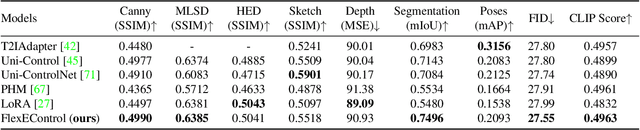
Controllable text-to-image (T2I) diffusion models generate images conditioned on both text prompts and semantic inputs of other modalities like edge maps. Nevertheless, current controllable T2I methods commonly face challenges related to efficiency and faithfulness, especially when conditioning on multiple inputs from either the same or diverse modalities. In this paper, we propose a novel Flexible and Efficient method, FlexEControl, for controllable T2I generation. At the core of FlexEControl is a unique weight decomposition strategy, which allows for streamlined integration of various input types. This approach not only enhances the faithfulness of the generated image to the control, but also significantly reduces the computational overhead typically associated with multimodal conditioning. Our approach achieves a reduction of 41% in trainable parameters and 30% in memory usage compared with Uni-ControlNet. Moreover, it doubles data efficiency and can flexibly generate images under the guidance of multiple input conditions of various modalities.
Bootstrapping Chest CT Image Understanding by Distilling Knowledge from X-ray Expert Models
Apr 07, 2024



Radiologists highly desire fully automated versatile AI for medical imaging interpretation. However, the lack of extensively annotated large-scale multi-disease datasets has hindered the achievement of this goal. In this paper, we explore the feasibility of leveraging language as a naturally high-quality supervision for chest CT imaging. In light of the limited availability of image-report pairs, we bootstrap the understanding of 3D chest CT images by distilling chest-related diagnostic knowledge from an extensively pre-trained 2D X-ray expert model. Specifically, we propose a language-guided retrieval method to match each 3D CT image with its semantically closest 2D X-ray image, and perform pair-wise and semantic relation knowledge distillation. Subsequently, we use contrastive learning to align images and reports within the same patient while distinguishing them from the other patients. However, the challenge arises when patients have similar semantic diagnoses, such as healthy patients, potentially confusing if treated as negatives. We introduce a robust contrastive learning that identifies and corrects these false negatives. We train our model with over 12,000 pairs of chest CT images and radiology reports. Extensive experiments across multiple scenarios, including zero-shot learning, report generation, and fine-tuning processes, demonstrate the model's feasibility in interpreting chest CT images.
Adaptive Critical Subgraph Mining for Cognitive Impairment Conversion Prediction with T1-MRI-based Brain Network
Mar 20, 2024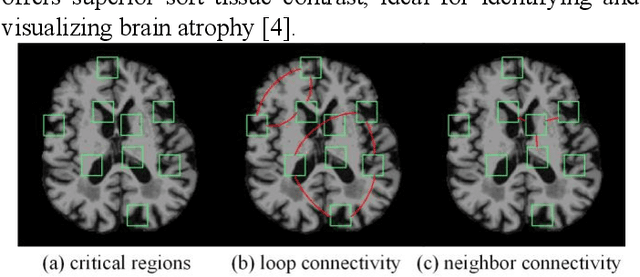
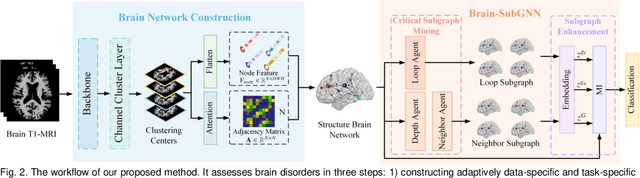
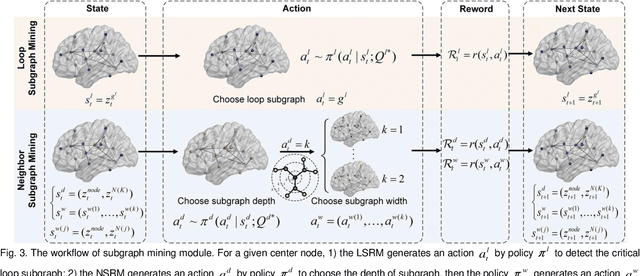
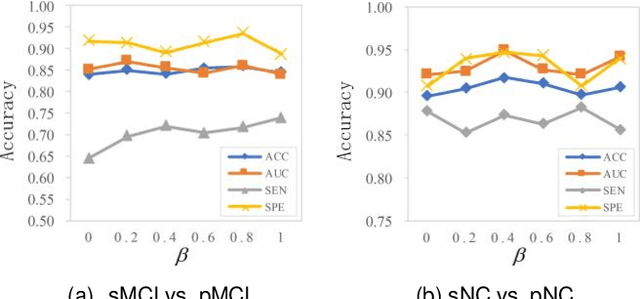
Prediction the conversion to early-stage dementia is critical for mitigating its progression but remains challenging due to subtle cognitive impairments and structural brain changes. Traditional T1-weighted magnetic resonance imaging (T1-MRI) research focus on identifying brain atrophy regions but often fails to address the intricate connectivity between them. This limitation underscores the necessity of focuing on inter-regional connectivity for a comprehensive understand of the brain's complex network. Moreover, there is a pressing demand for methods that adaptively preserve and extract critical information, particularly specialized subgraph mining techniques for brain networks. These are essential for developing high-quality feature representations that reveal critical spatial impacts of structural brain changes and its topology. In this paper, we propose Brain-SubGNN, a novel graph representation network to mine and enhance critical subgraphs based on T1-MRI. This network provides a subgraph-level interpretation, enhancing interpretability and insights for graph analysis. The process begins by extracting node features and a correlation matrix between nodes to construct a task-oriented brain network. Brain-SubGNN then adaptively identifies and enhances critical subgraphs, capturing both loop and neighbor subgraphs. This method reflects the loop topology and local changes, indicative of long-range connections, and maintains local and global brain attributes. Extensive experiments validate the effectiveness and advantages of Brain-SubGNN, demonstrating its potential as a powerful tool for understanding and diagnosing early-stage dementia. Source code is available at https://github.com/Leng-10/Brain-SubGNN.
Text-to-image Editing by Image Information Removal
May 27, 2023Diffusion models have demonstrated impressive performance in text-guided image generation. To leverage the knowledge of text-guided image generation models in image editing, current approaches either fine-tune the pretrained models using the input image (e.g., Imagic) or incorporate structure information as additional constraints into the pretrained models (e.g., ControlNet). However, fine-tuning large-scale diffusion models on a single image can lead to severe overfitting issues and lengthy inference time. The information leakage from pretrained models makes it challenging to preserve the text-irrelevant content of the input image while generating new features guided by language descriptions. On the other hand, methods that incorporate structural guidance (e.g., edge maps, semantic maps, keypoints) as additional constraints face limitations in preserving other attributes of the original image, such as colors or textures. A straightforward way to incorporate the original image is to directly use it as an additional control. However, since image editing methods are typically trained on the image reconstruction task, the incorporation can lead to the identical mapping issue, where the model learns to output an image identical to the input, resulting in limited editing capabilities. To address these challenges, we propose a text-to-image editing model with Image Information Removal module (IIR) to selectively erase color-related and texture-related information from the original image, allowing us to better preserve the text-irrelevant content and avoid the identical mapping issue. We evaluate our model on three benchmark datasets: CUB, Outdoor Scenes, and COCO. Our approach achieves the best editability-fidelity trade-off, and our edited images are approximately 35% more preferred by annotators than the prior-arts on COCO.
Dynamic Structural Brain Network Construction by Hierarchical Prototype Embedding GCN using T1-MRI
May 17, 2023Constructing structural brain networks using T1-weighted magnetic resonance imaging (T1-MRI) presents a significant challenge due to the lack of direct regional connectivity information. Current methods with T1-MRI rely on predefined regions or isolated pretrained location modules to obtain atrophic regions, which neglects individual specificity. Besides, existing methods capture global structural context only on the whole-image-level, which weaken correlation between regions and the hierarchical distribution nature of brain connectivity.We hereby propose a novel dynamic structural brain network construction method based on T1-MRI, which can dynamically localize critical regions and constrain the hierarchical distribution among them for constructing dynamic structural brain network. Specifically, we first cluster spatially-correlated channel and generate several critical brain regions as prototypes. Further, we introduce a contrastive loss function to constrain the prototypes distribution, which embed the hierarchical brain semantic structure into the latent space. Self-attention and GCN are then used to dynamically construct hierarchical correlations of critical regions for brain network and explore the correlation, respectively. Our method is evaluated on ADNI-1 and ADNI-2 databases for mild cognitive impairment (MCI) conversion prediction, and acheive the state-of-the-art (SOTA) performance. Our source code is available at http://github.com/*******.
Taking a Language Detour: How International Migrants Speaking a Minority Language Seek COVID-Related Information in Their Host Countries
Sep 07, 2022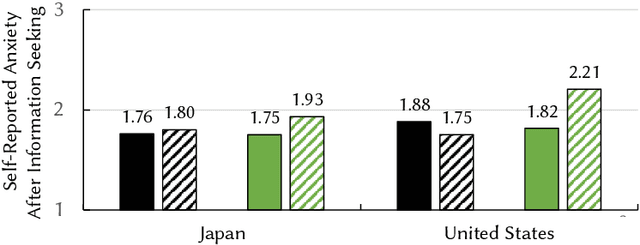
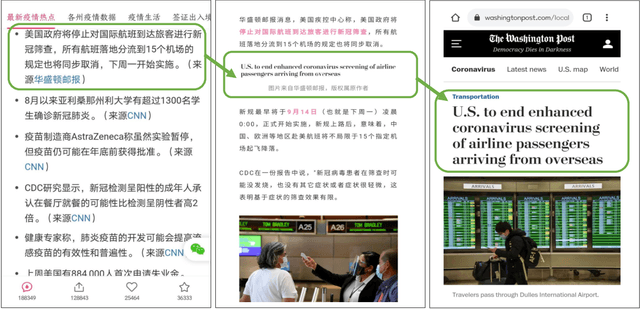
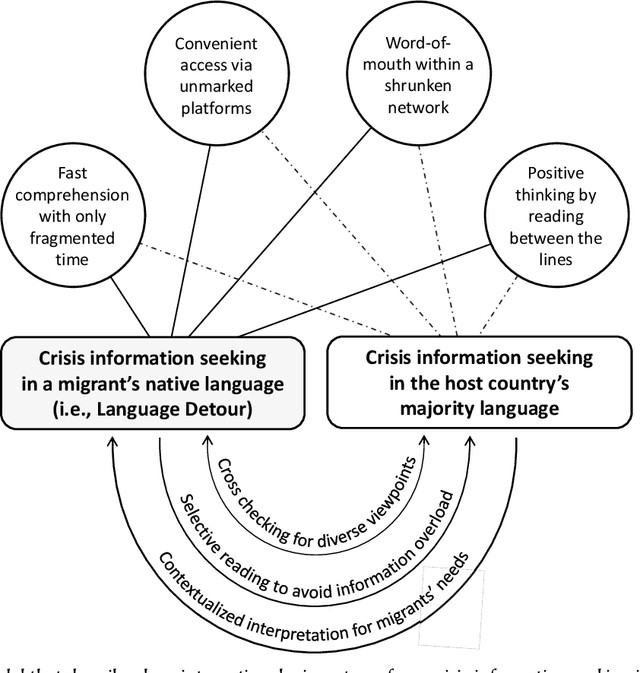
Information seeking is crucial for people's self-care and wellbeing in times of public crises. Extensive research has investigated empirical understandings as well as technical solutions to facilitate information seeking by domestic citizens of affected regions. However, limited knowledge is established to support international migrants who need to survive a crisis in their host countries. The current paper presents an interview study with two cohorts of Chinese migrants living in Japan (N=14) and the United States (N=14). Participants reflected on their information seeking experiences during the COVID pandemic. The reflection was supplemented by two weeks of self-tracking where participants maintained records of their COVIDrelated information seeking practice. Our data indicated that participants often took language detours, or visits to Mandarin resources for information about the COVID outbreak in their host countries. They also made strategic use of the Mandarin information to perform selective reading, cross-checking, and contextualized interpretation of COVID-related information in Japanese or English. While such practices enhanced participants' perceived effectiveness of COVID-related information gathering and sensemaking, they disadvantaged people through sometimes incognizant ways. Further, participants lacked the awareness or preference to review migrant-oriented information that was issued by the host country's public authorities despite its availability. Building upon these findings, we discussed solutions to improve international migrants' COVID-related information seeking in their non-native language and cultural environment. We advocated inclusive crisis infrastructures that would engage people with diverse levels of local language fluency, information literacy, and experience in leveraging public services.
ProxyBO: Accelerating Neural Architecture Search via Bayesian Optimization with Zero-cost Proxies
Oct 26, 2021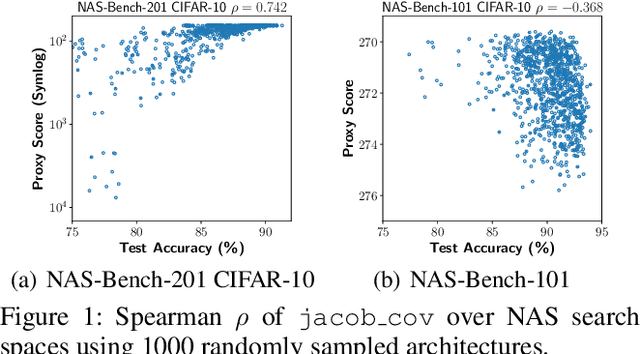
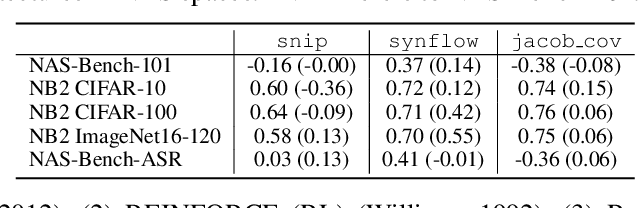
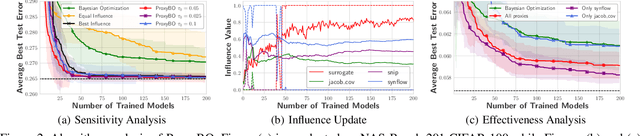
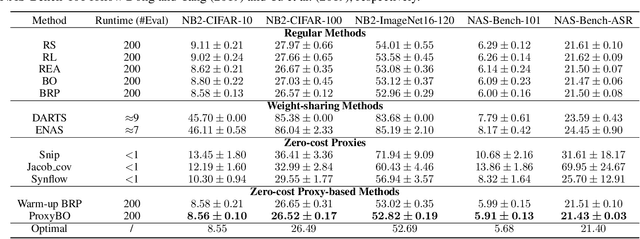
Designing neural architectures requires immense manual efforts. This has promoted the development of neural architecture search (NAS) to automate this design. While previous NAS methods achieve promising results but run slowly and zero-cost proxies run extremely fast but are less promising, recent work considers utilizing zero-cost proxies via a simple warm-up. The existing method has two limitations, which are unforeseeable reliability and one-shot usage. To address the limitations, we present ProxyBO, an efficient Bayesian optimization framework that utilizes the zero-cost proxies to accelerate neural architecture search. We propose the generalization ability measurement to estimate the fitness of proxies on the task during each iteration and then combine BO with zero-cost proxies via dynamic influence combination. Extensive empirical studies show that ProxyBO consistently outperforms competitive baselines on five tasks from three public benchmarks. Concretely, ProxyBO achieves up to 5.41x and 3.83x speedups over the state-of-the-art approach REA and BRP-NAS, respectively.
Temporal Attentive Alignment for Large-Scale Video Domain Adaptation
Sep 15, 2019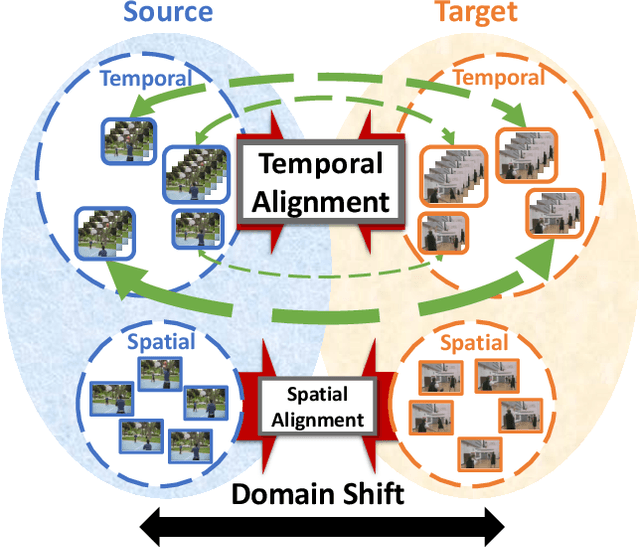

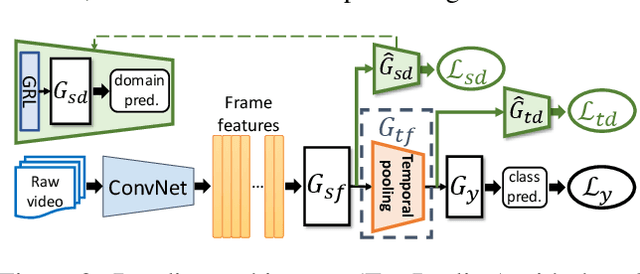
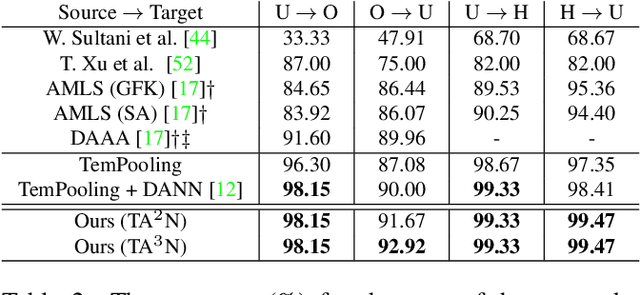
Although various image-based domain adaptation (DA) techniques have been proposed in recent years, domain shift in videos is still not well-explored. Most previous works only evaluate performance on small-scale datasets which are saturated. Therefore, we first propose two large-scale video DA datasets with much larger domain discrepancy: UCF-HMDB_full and Kinetics-Gameplay. Second, we investigate different DA integration methods for videos, and show that simultaneously aligning and learning temporal dynamics achieves effective alignment even without sophisticated DA methods. Finally, we propose Temporal Attentive Adversarial Adaptation Network (TA3N), which explicitly attends to the temporal dynamics using domain discrepancy for more effective domain alignment, achieving state-of-the-art performance on four video DA datasets (e.g. 7.9% accuracy gain over "Source only" from 73.9% to 81.8% on "HMDB --> UCF", and 10.3% gain on "Kinetics --> Gameplay"). The code and data are released at http://github.com/cmhungsteve/TA3N.