 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Attentive Alignment for Large-Scale Video Domain Adaptation
Sep 15, 2019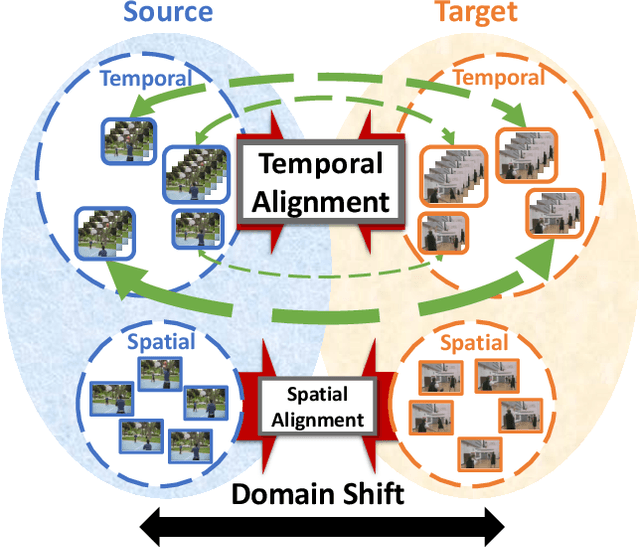

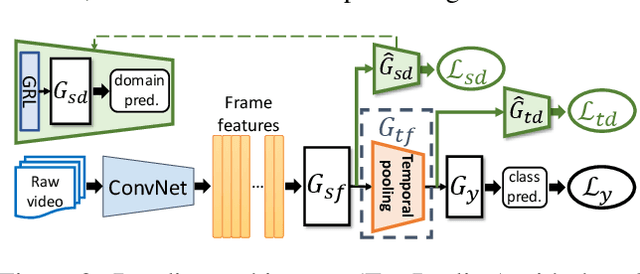
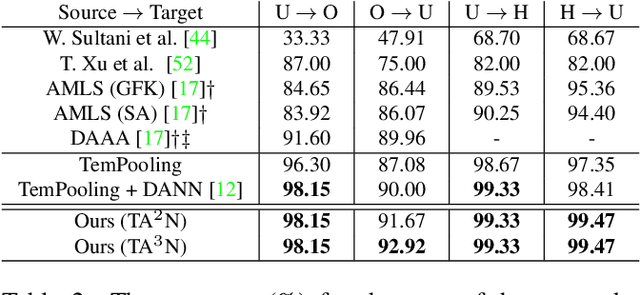
Although various image-based domain adaptation (DA) techniques have been proposed in recent years, domain shift in videos is still not well-explored. Most previous works only evaluate performance on small-scale datasets which are saturated. Therefore, we first propose two large-scale video DA datasets with much larger domain discrepancy: UCF-HMDB_full and Kinetics-Gameplay. Second, we investigate different DA integration methods for videos, and show that simultaneously aligning and learning temporal dynamics achieves effective alignment even without sophisticated DA methods. Finally, we propose Temporal Attentive Adversarial Adaptation Network (TA3N), which explicitly attends to the temporal dynamics using domain discrepancy for more effective domain alignment, achieving state-of-the-art performance on four video DA datasets (e.g. 7.9% accuracy gain over "Source only" from 73.9% to 81.8% on "HMDB --> UCF", and 10.3% gain on "Kinetics --> Gameplay"). The code and data are released at http://github.com/cmhungsteve/TA3N.
Image Captioning with Integrated Bottom-Up and Multi-level Residual Top-Down Attention for Game Scene Understanding
Jun 16, 2019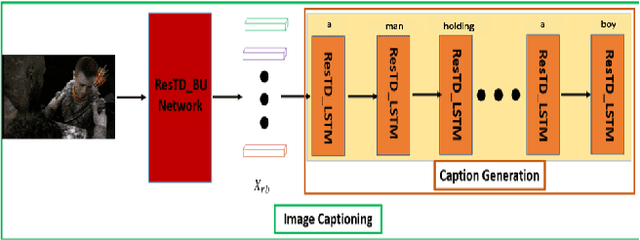

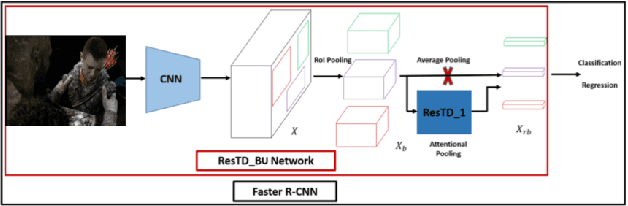
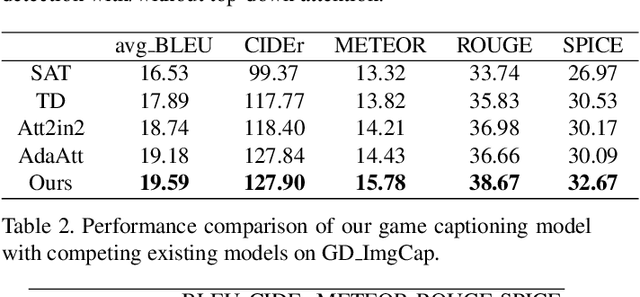
Image captioning has attracted considerable attention in recent years. However, little work has been done for game image captioning which has some unique characteristics and requirements. In this work we propose a novel game image captioning model which integrates bottom-up attention with a new multi-level residual top-down attention mechanism. Firstly, a lower-level residual top-down attention network is added to the Faster R-CNN based bottom-up attention network to address the problem that the latter may lose important spatial information when extracting regional features. Secondly, an upper-level residual top-down attention network is implemented in the caption generation network to better fuse the extracted regional features for subsequent caption prediction. We create two game datasets to evaluate the proposed model. Extensive experiments show that our proposed model outperforms existing baseline models.
Speaker Cluster-Based Speaker Adaptive Training for Deep Neural Network Acoustic Modeling
Apr 20, 2016
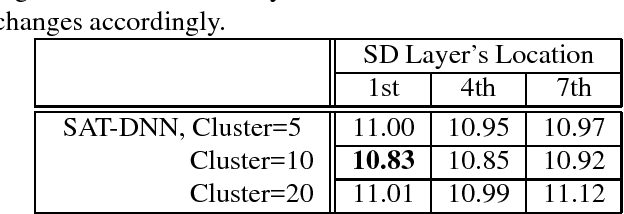

A speaker cluster-based speaker adaptive training (SAT) method under deep neural network-hidden Markov model (DNN-HMM) framework is presented in this paper. During training, speakers that are acoustically adjacent to each other are hierarchically clustered using an i-vector based distance metric. DNNs with speaker dependent layers are then adaptively trained for each cluster of speakers. Before decoding starts, an unseen speaker in test set is matched to the closest speaker cluster through comparing i-vector based distances. The previously trained DNN of the matched speaker cluster is used for decoding utterances of the test speaker. The performance of the proposed method on a large vocabulary spontaneous speech recognition task is evaluated on a training set of with 1500 hours of speech, and a test set of 24 speakers with 1774 utterances. Comparing to a speaker independent DNN with a baseline word error rate of 11.6%, a relative 6.8% reduction in word error rate is observed from the proposed method.