 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage Captioning with Integrated Bottom-Up and Multi-level Residual Top-Down Attention for Game Scene Understanding
Jun 16, 2019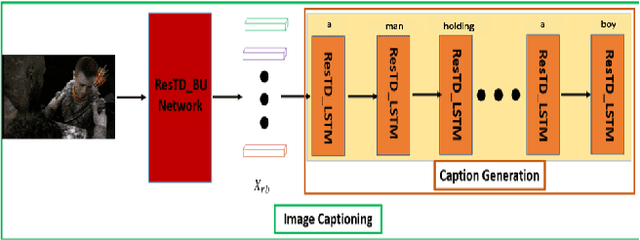

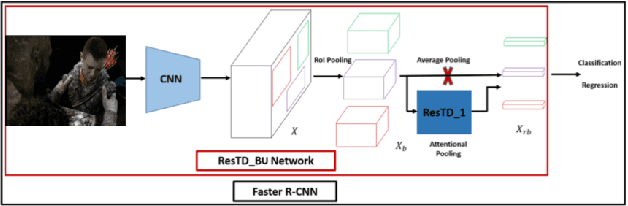
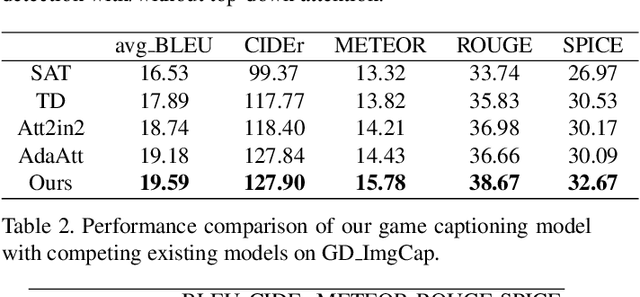
Image captioning has attracted considerable attention in recent years. However, little work has been done for game image captioning which has some unique characteristics and requirements. In this work we propose a novel game image captioning model which integrates bottom-up attention with a new multi-level residual top-down attention mechanism. Firstly, a lower-level residual top-down attention network is added to the Faster R-CNN based bottom-up attention network to address the problem that the latter may lose important spatial information when extracting regional features. Secondly, an upper-level residual top-down attention network is implemented in the caption generation network to better fuse the extracted regional features for subsequent caption prediction. We create two game datasets to evaluate the proposed model. Extensive experiments show that our proposed model outperforms existing baseline models.
Generation and Pruning of Pronunciation Variants to Improve ASR Accuracy
Jun 28, 2016
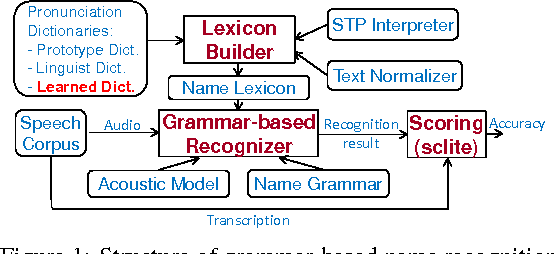
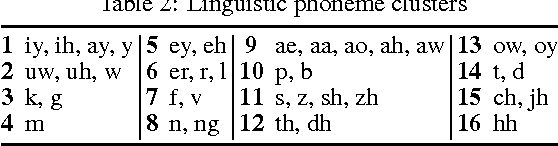
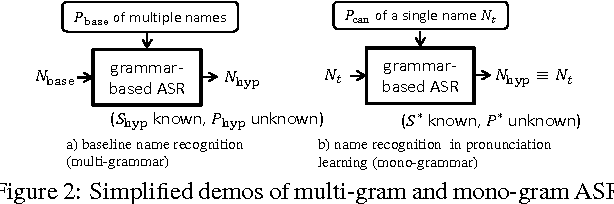
Speech recognition, especially name recognition, is widely used in phone services such as company directory dialers, stock quote providers or location finders. It is usually challenging due to pronunciation variations. This paper proposes an efficient and robust data-driven technique which automatically learns acceptable word pronunciations and updates the pronunciation dictionary to build a better lexicon without affecting recognition of other words similar to the target word. It generalizes well on datasets with various sizes, and reduces the error rate on a database with 13000+ human names by 42%, compared to a baseline with regular dictionaries already covering canonical pronunciations of 97%+ words in names, plus a well-trained spelling-to-pronunciation (STP) engine.
Adaptive Frequency Cepstral Coefficients for Word Mispronunciation Detection
Feb 25, 2016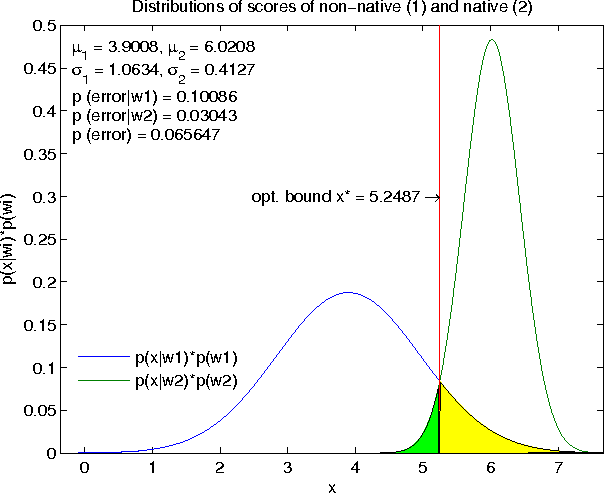
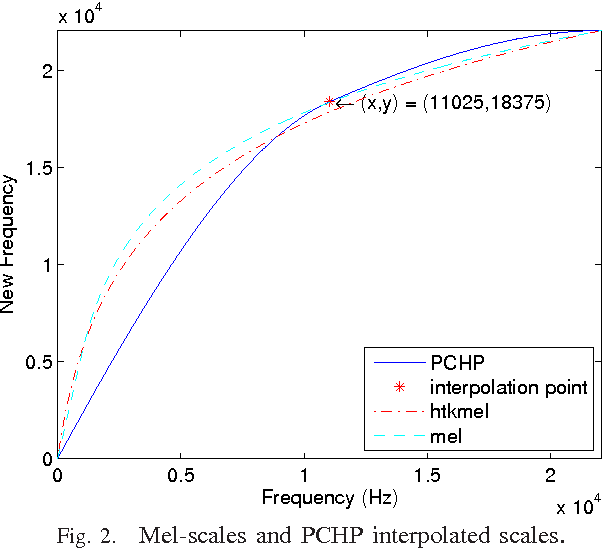
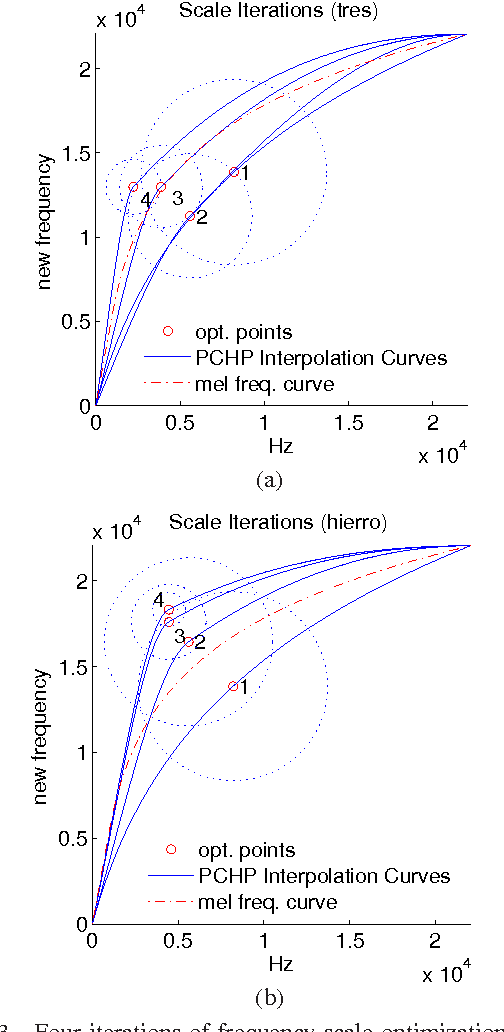
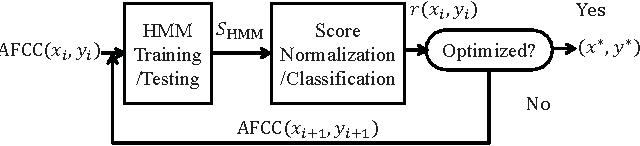
Systems based on automatic speech recognition (ASR) technology can provide important functionality in computer assisted language learning applications. This is a young but growing area of research motivated by the large number of students studying foreign languages. Here we propose a Hidden Markov Model (HMM)-based method to detect mispronunciations. Exploiting the specific dialog scripting employed in language learning software, HMMs are trained for different pronunciations. New adaptive features have been developed and obtained through an adaptive warping of the frequency scale prior to computing the cepstral coefficients. The optimization criterion used for the warping function is to maximize separation of two major groups of pronunciations (native and non-native) in terms of classification rate. Experimental results show that the adaptive frequency scale yields a better coefficient representation leading to higher classification rates in comparison with conventional HMMs using Mel-frequency cepstral coefficients.
PCA Method for Automated Detection of Mispronounced Words
Feb 25, 2016This paper presents a method for detecting mispronunciations with the aim of improving Computer Assisted Language Learning (CALL) tools used by foreign language learners. The algorithm is based on Principle Component Analysis (PCA). It is hierarchical with each successive step refining the estimate to classify the test word as being either mispronounced or correct. Preprocessing before detection, like normalization and time-scale modification, is implemented to guarantee uniformity of the feature vectors input to the detection system. The performance using various features including spectrograms and Mel-Frequency Cepstral Coefficients (MFCCs) are compared and evaluated. Best results were obtained using MFCCs, achieving up to 99% accuracy in word verification and 93% in native/non-native classification. Compared with Hidden Markov Models (HMMs) which are used pervasively in recognition application, this particular approach is computational efficient and effective when training data is limited.
PCA/LDA Approach for Text-Independent Speaker Recognition
Feb 25, 2016Various algorithms for text-independent speaker recognition have been developed through the decades, aiming to improve both accuracy and efficiency. This paper presents a novel PCA/LDA-based approach that is faster than traditional statistical model-based methods and achieves competitive results. First, the performance based on only PCA and only LDA is measured; then a mixed model, taking advantages of both methods, is introduced. A subset of the TIMIT corpus composed of 200 male speakers, is used for enrollment, validation and testing. The best results achieve 100%; 96% and 95% classification rate at population level 50; 100 and 200, using 39-dimensional MFCC features with delta and double delta. These results are based on 12-second text-independent speech for training and 4-second data for test. These are comparable to the conventional MFCC-GMM methods, but require significantly less time to train and operate.
Improved Accent Classification Combining Phonetic Vowels with Acoustic Features
Feb 24, 2016



Researches have shown accent classification can be improved by integrating semantic information into pure acoustic approach. In this work, we combine phonetic knowledge, such as vowels, with enhanced acoustic features to build an improved accent classification system. The classifier is based on Gaussian Mixture Model-Universal Background Model (GMM-UBM), with normalized Perceptual Linear Predictive (PLP) features. The features are further optimized by Principle Component Analysis (PCA) and Hetroscedastic Linear Discriminant Analysis (HLDA). Using 7 major types of accented speech from the Foreign Accented English (FAE) corpus, the system achieves classification accuracy 54% with input test data as short as 20 seconds, which is competitive to the state of the art in this field.
Domain Specific Author Attribution Based on Feedforward Neural Network Language Models
Feb 24, 2016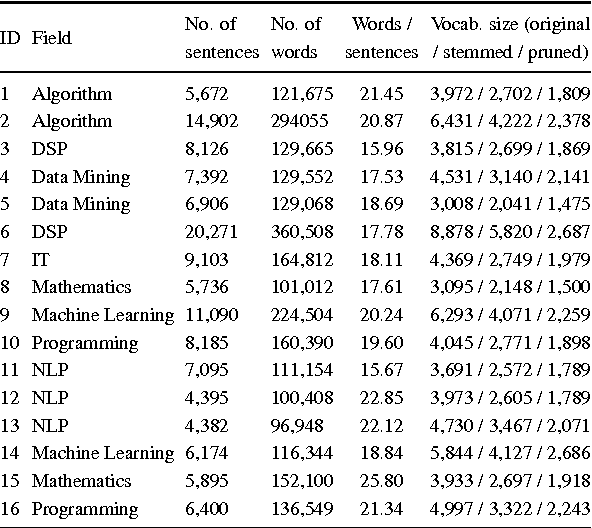
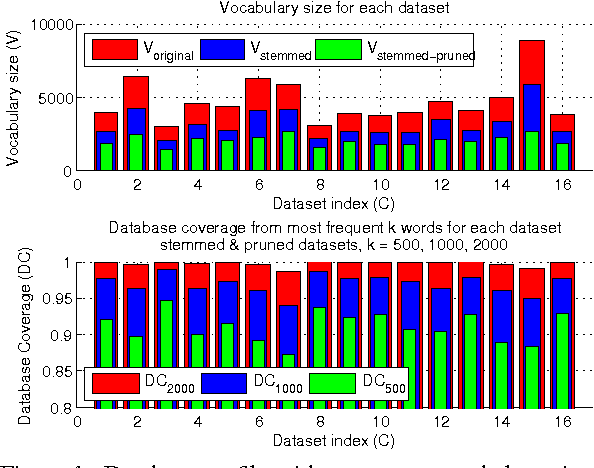
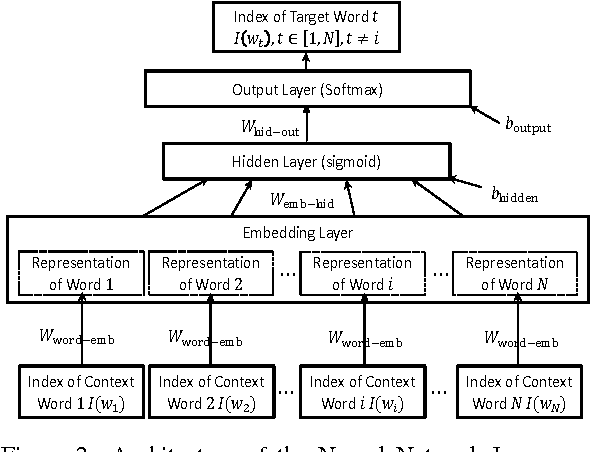
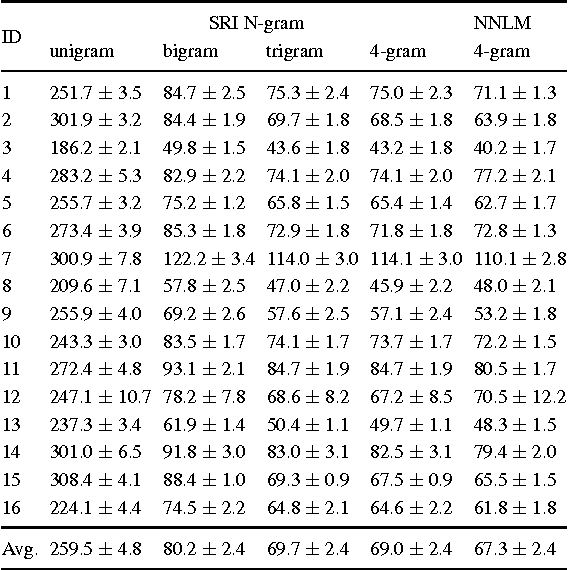
Authorship attribution refers to the task of automatically determining the author based on a given sample of text. It is a problem with a long history and has a wide range of application. Building author profiles using language models is one of the most successful methods to automate this task. New language modeling methods based on neural networks alleviate the curse of dimensionality and usually outperform conventional N-gram methods. However, there have not been much research applying them to authorship attribution. In this paper, we present a novel setup of a Neural Network Language Model (NNLM) and apply it to a database of text samples from different authors. We investigate how the NNLM performs on a task with moderate author set size and relatively limited training and test data, and how the topics of the text samples affect the accuracy. NNLM achieves nearly 2.5% reduction in perplexity, a measurement of fitness of a trained language model to the test data. Given 5 random test sentences, it also increases the author classification accuracy by 3.43% on average, compared with the N-gram methods using SRILM tools. An open source implementation of our methodology is freely available at https://github.com/zge/authorship-attribution/.
Accent Classification with Phonetic Vowel Representation
Feb 24, 2016



Previous accent classification research focused mainly on detecting accents with pure acoustic information without recognizing accented speech. This work combines phonetic knowledge such as vowels with acoustic information to build Guassian Mixture Model (GMM) classifier with Perceptual Linear Predictive (PLP) features, optimized by Hetroscedastic Linear Discriminant Analysis (HLDA). With input about 20-second accented speech, this system achieves classification rate of 51% on a 7-way classification system focusing on the major types of accents in English, which is competitive to the state-of-the-art results in this field.
Authorship Attribution Using a Neural Network Language Model
Feb 17, 2016
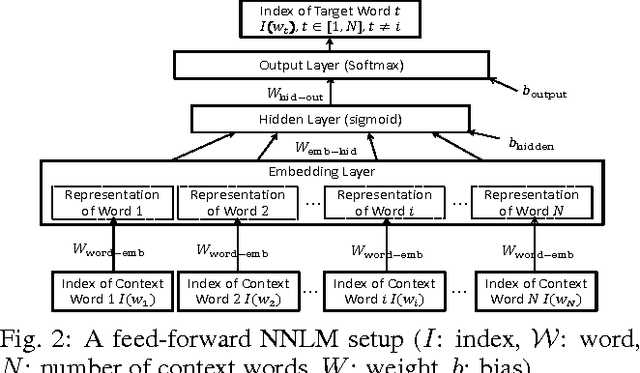
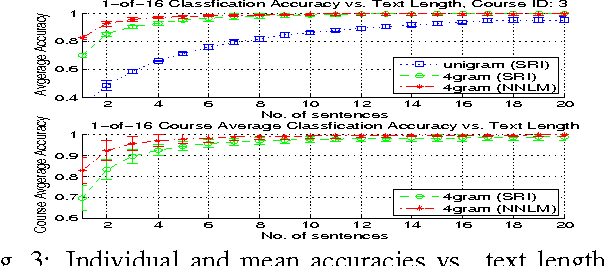
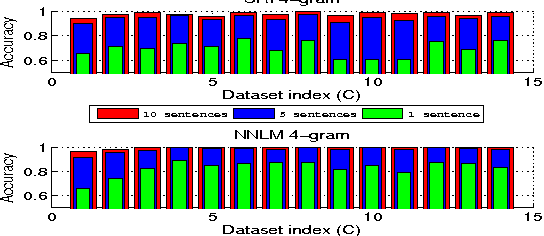
In practice, training language models for individual authors is often expensive because of limited data resources. In such cases, Neural Network Language Models (NNLMs), generally outperform the traditional non-parametric N-gram models. Here we investigate the performance of a feed-forward NNLM on an authorship attribution problem, with moderate author set size and relatively limited data. We also consider how the text topics impact performance. Compared with a well-constructed N-gram baseline method with Kneser-Ney smoothing, the proposed method achieves nearly 2:5% reduction in perplexity and increases author classification accuracy by 3:43% on average, given as few as 5 test sentences. The performance is very competitive with the state of the art in terms of accuracy and demand on test data. The source code, preprocessed datasets, a detailed description of the methodology and results are available at https://github.com/zge/authorship-attribution.