 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerformance evaluation of SLAM-ASR: The Good, the Bad, the Ugly, and the Way Forward
Nov 06, 2024



Recent research has demonstrated that training a linear connector between speech foundation encoders and large language models (LLMs) enables this architecture to achieve strong ASR capabilities. Despite the impressive results, it remains unclear whether these simple approaches are robust enough across different scenarios and speech conditions, such as domain shifts and different speech perturbations. In this paper, we address these questions by conducting various ablation experiments using a recent and widely adopted approach called SLAM-ASR. We present novel empirical findings that offer insights on how to effectively utilize the SLAM-ASR architecture across a wide range of settings. Our main findings indicate that the SLAM-ASR exhibits poor performance in cross-domain evaluation settings. Additionally, speech perturbations within in-domain data, such as changes in speed or the presence of additive noise, can significantly impact performance. Our findings offer critical insights for fine-tuning and configuring robust LLM-based ASR models, tailored to different data characteristics and computational resources.
TokenVerse: Unifying Speech and NLP Tasks via Transducer-based ASR
Jul 05, 2024



In traditional conversational intelligence from speech, a cascaded pipeline is used, involving tasks such as voice activity detection, diarization, transcription, and subsequent processing with different NLP models for tasks like semantic endpointing and named entity recognition (NER). Our paper introduces TokenVerse, a single Transducer-based model designed to handle multiple tasks. This is achieved by integrating task-specific tokens into the reference text during ASR model training, streamlining the inference and eliminating the need for separate NLP models. In addition to ASR, we conduct experiments on 3 different tasks: speaker change detection, endpointing, and NER. Our experiments on a public and a private dataset show that the proposed method improves ASR by up to 7.7% in relative WER while outperforming the cascaded pipeline approach in individual task performance. Additionally, we present task transfer learning to a new task within an existing TokenVerse.
XLSR-Transducer: Streaming ASR for Self-Supervised Pretrained Models
Jul 05, 2024



Self-supervised pretrained models exhibit competitive performance in automatic speech recognition on finetuning, even with limited in-domain supervised data for training. However, popular pretrained models are not suitable for streaming ASR because they are trained with full attention context. In this paper, we introduce XLSR-Transducer, where the XLSR-53 model is used as encoder in transducer setup. Our experiments on the AMI dataset reveal that the XLSR-Transducer achieves 4% absolute WER improvement over Whisper large-v2 and 8% over a Zipformer transducer model trained from scratch.To enable streaming capabilities, we investigate different attention masking patterns in the self-attention computation of transformer layers within the XLSR-53 model. We validate XLSR-Transducer on AMI and 5 languages from CommonVoice under low-resource scenarios. Finally, with the introduction of attention sinks, we reduce the left context by half while achieving a relative 12% improvement in WER.
Implementing contextual biasing in GPU decoder for online ASR
Jun 23, 2023


GPU decoding significantly accelerates the output of ASR predictions. While GPUs are already being used for online ASR decoding, post-processing and rescoring on GPUs have not been properly investigated yet. Rescoring with available contextual information can considerably improve ASR predictions. Previous studies have proven the viability of lattice rescoring in decoding and biasing language model (LM) weights in offline and online CPU scenarios. In real-time GPU decoding, partial recognition hypotheses are produced without lattice generation, which makes the implementation of biasing more complex. The paper proposes and describes an approach to integrate contextual biasing in real-time GPU decoding while exploiting the standard Kaldi GPU decoder. Besides the biasing of partial ASR predictions, our approach also permits dynamic context switching allowing a flexible rescoring per each speech segment directly on GPU. The code is publicly released and tested with open-sourced test sets.
On the Efficacy and Noise-Robustness of Jointly Learned Speech Emotion and Automatic Speech Recognition
May 25, 2023


New-age conversational agent systems perform both speech emotion recognition (SER) and automatic speech recognition (ASR) using two separate and often independent approaches for real-world application in noisy environments. In this paper, we investigate a joint ASR-SER multitask learning approach in a low-resource setting and show that improvements are observed not only in SER, but also in ASR. We also investigate the robustness of such jointly trained models to the presence of background noise, babble, and music. Experimental results on the IEMOCAP dataset show that joint learning can improve ASR word error rate (WER) and SER classification accuracy by 10.7% and 2.3% respectively in clean scenarios. In noisy scenarios, results on data augmented with MUSAN show that the joint approach outperforms the independent ASR and SER approaches across many noisy conditions. Overall, the joint ASR-SER approach yielded more noise-resistant models than the independent ASR and SER approaches.
Effectiveness of Text, Acoustic, and Lattice-based representations in Spoken Language Understanding tasks
Dec 16, 2022



In this paper, we perform an exhaustive evaluation of different representations to address the intent classification problem in a Spoken Language Understanding (SLU) setup. We benchmark three types of systems to perform the SLU intent detection task: 1) text-based, 2) lattice-based, and a novel 3) multimodal approach. Our work provides a comprehensive analysis of what could be the achievable performance of different state-of-the-art SLU systems under different circumstances, e.g., automatically- vs. manually-generated transcripts. We evaluate the systems on the publicly available SLURP spoken language resource corpus. Our results indicate that using richer forms of Automatic Speech Recognition (ASR) outputs allows SLU systems to improve in comparison to the 1-best setup (4% relative improvement). However, crossmodal approaches, i.e., learning from acoustic and text embeddings, obtains performance similar to the oracle setup, and a relative improvement of 18% over the 1-best configuration. Thus, crossmodal architectures represent a good alternative to overcome the limitations of working purely automatically generated textual data.
Generation and Pruning of Pronunciation Variants to Improve ASR Accuracy
Jun 28, 2016
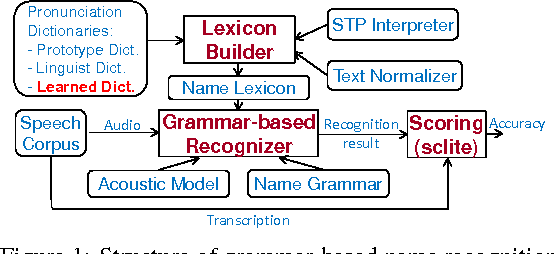
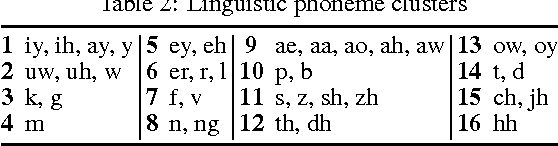
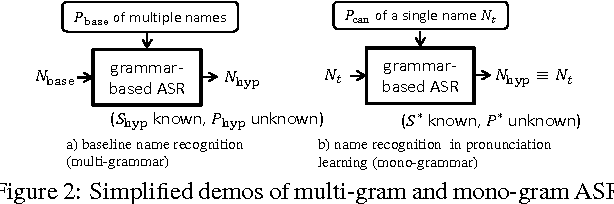
Speech recognition, especially name recognition, is widely used in phone services such as company directory dialers, stock quote providers or location finders. It is usually challenging due to pronunciation variations. This paper proposes an efficient and robust data-driven technique which automatically learns acceptable word pronunciations and updates the pronunciation dictionary to build a better lexicon without affecting recognition of other words similar to the target word. It generalizes well on datasets with various sizes, and reduces the error rate on a database with 13000+ human names by 42%, compared to a baseline with regular dictionaries already covering canonical pronunciations of 97%+ words in names, plus a well-trained spelling-to-pronunciation (STP) engine.
Accent Classification with Phonetic Vowel Representation
Feb 24, 2016



Previous accent classification research focused mainly on detecting accents with pure acoustic information without recognizing accented speech. This work combines phonetic knowledge such as vowels with acoustic information to build Guassian Mixture Model (GMM) classifier with Perceptual Linear Predictive (PLP) features, optimized by Hetroscedastic Linear Discriminant Analysis (HLDA). With input about 20-second accented speech, this system achieves classification rate of 51% on a 7-way classification system focusing on the major types of accents in English, which is competitive to the state-of-the-art results in this field.