 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffectiveness of Text, Acoustic, and Lattice-based representations in Spoken Language Understanding tasks
Dec 16, 2022In this paper, we perform an exhaustive evaluation of different representations to address the intent classification problem in a Spoken Language Understanding (SLU) setup. We benchmark three types of systems to perform the SLU intent detection task: 1) text-based, 2) lattice-based, and a novel 3) multimodal approach. Our work provides a comprehensive analysis of what could be the achievable performance of different state-of-the-art SLU systems under different circumstances, e.g., automatically- vs. manually-generated transcripts. We evaluate the systems on the publicly available SLURP spoken language resource corpus. Our results indicate that using richer forms of Automatic Speech Recognition (ASR) outputs allows SLU systems to improve in comparison to the 1-best setup (4% relative improvement). However, crossmodal approaches, i.e., learning from acoustic and text embeddings, obtains performance similar to the oracle setup, and a relative improvement of 18% over the 1-best configuration. Thus, crossmodal architectures represent a good alternative to overcome the limitations of working purely automatically generated textual data.
ATCO2 corpus: A Large-Scale Dataset for Research on Automatic Speech Recognition and Natural Language Understanding of Air Traffic Control Communications
Nov 08, 2022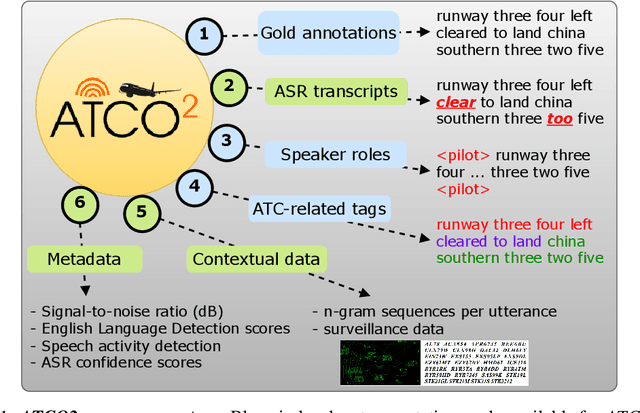
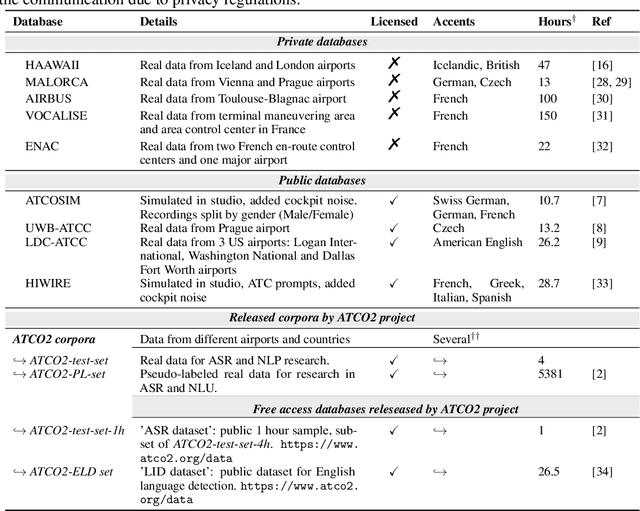
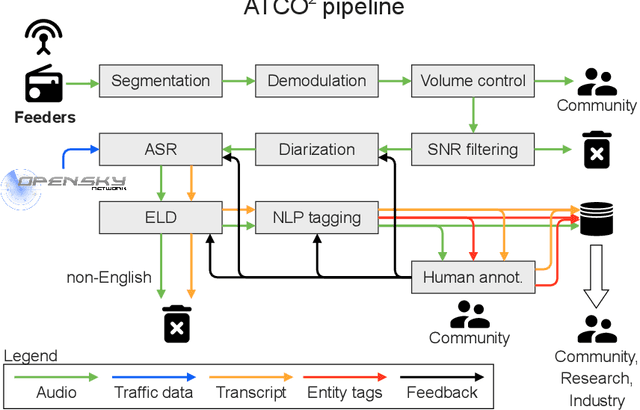

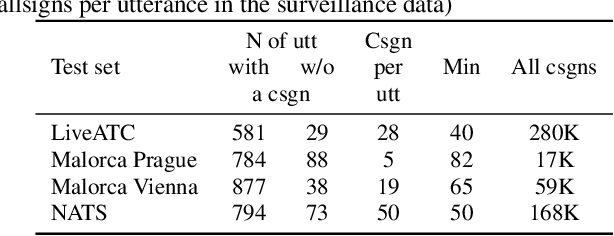
Personal assistants, automatic speech recognizers and dialogue understanding systems are becoming more critical in our interconnected digital world. A clear example is air traffic control (ATC) communications. ATC aims at guiding aircraft and controlling the airspace in a safe and optimal manner. These voice-based dialogues are carried between an air traffic controller (ATCO) and pilots via very-high frequency radio channels. In order to incorporate these novel technologies into ATC (low-resource domain), large-scale annotated datasets are required to develop the data-driven AI systems. Two examples are automatic speech recognition (ASR) and natural language understanding (NLU). In this paper, we introduce the ATCO2 corpus, a dataset that aims at fostering research on the challenging ATC field, which has lagged behind due to lack of annotated data. The ATCO2 corpus covers 1) data collection and pre-processing, 2) pseudo-annotations of speech data, and 3) extraction of ATC-related named entities. The ATCO2 corpus is split into three subsets. 1) ATCO2-test-set corpus contains 4 hours of ATC speech with manual transcripts and a subset with gold annotations for named-entity recognition (callsign, command, value). 2) The ATCO2-PL-set corpus consists of 5281 hours of unlabeled ATC data enriched with automatic transcripts from an in-domain speech recognizer, contextual information, speaker turn information, signal-to-noise ratio estimate and English language detection score per sample. Both available for purchase through ELDA at http://catalog.elra.info/en-us/repository/browse/ELRA-S0484. 3) The ATCO2-test-set-1h corpus is a one-hour subset from the original test set corpus, that we are offering for free at https://www.atco2.org/data. We expect the ATCO2 corpus will foster research on robust ASR and NLU not only in the field of ATC communications but also in the general research community.
A two-step approach to leverage contextual data: speech recognition in air-traffic communications
Feb 08, 2022

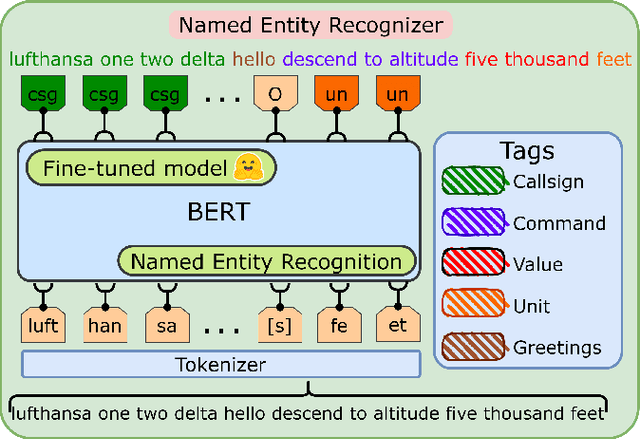
Automatic Speech Recognition (ASR), as the assistance of speech communication between pilots and air-traffic controllers, can significantly reduce the complexity of the task and increase the reliability of transmitted information. ASR application can lead to a lower number of incidents caused by misunderstanding and improve air traffic management (ATM) efficiency. Evidently, high accuracy predictions, especially, of key information, i.e., callsigns and commands, are required to minimize the risk of errors. We prove that combining the benefits of ASR and Natural Language Processing (NLP) methods to make use of surveillance data (i.e. additional modality) helps to considerably improve the recognition of callsigns (named entity). In this paper, we investigate a two-step callsign boosting approach: (1) at the 1 step (ASR), weights of probable callsign n-grams are reduced in G.fst and/or in the decoding FST (lattices), (2) at the 2 step (NLP), callsigns extracted from the improved recognition outputs with Named Entity Recognition (NER) are correlated with the surveillance data to select the most suitable one. Boosting callsign n-grams with the combination of ASR and NLP methods eventually leads up to 53.7% of an absolute, or 60.4% of a relative, improvement in callsign recognition.
* 20XX IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works. arXiv admin note: text overlap with arXiv:2108.12156
BERTraffic: A Robust BERT-Based Approach for Speaker Change Detection and Role Identification of Air-Traffic Communications
Oct 12, 2021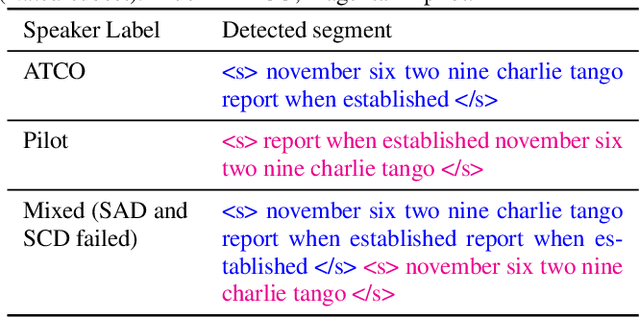
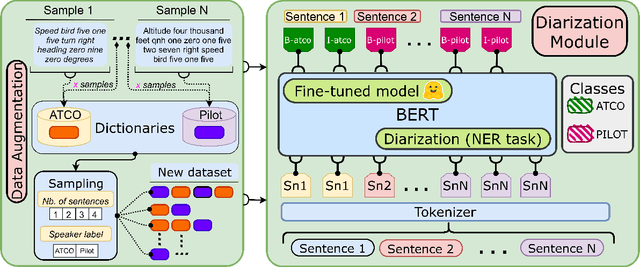
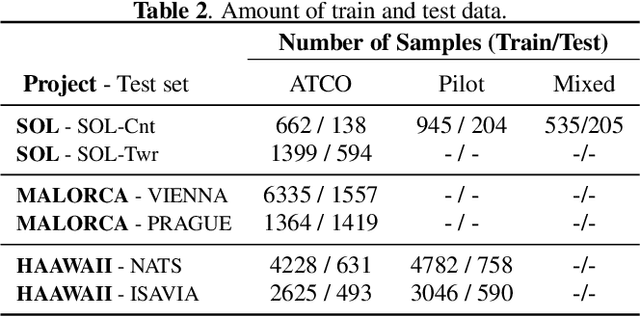
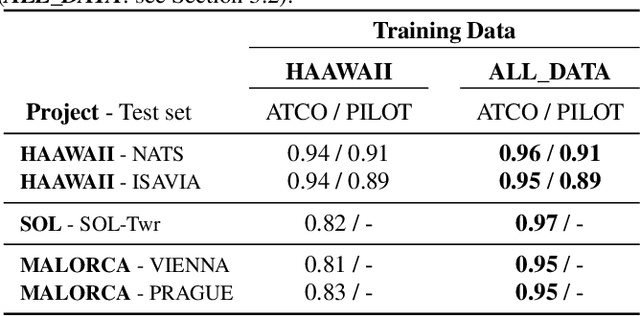
Automatic Speech Recognition (ASR) is gaining special interest in Air Traffic Control (ATC). ASR allows transcribing the communications between air traffic controllers (ATCOs) and pilots. These transcriptions are used to extract ATC command types and named entities such as aircraft callsigns. One common problem is when the Speech Activity Detection (SAD) or diarization system fails and then two or more single speaker segments are in the same recording, jeopardizing the overall system's performance. We developed a system that combines the segmentation of a SAD module with a BERT-based model that performs Speaker Change Detection (SCD) and Speaker Role Identification (SRI) based on ASR transcripts (i.e., diarization + SRI). This research demonstrates on a real-life ATC test set that performing diarization directly on textual data surpass acoustic level diarization. The proposed model reaches up to ~0.90/~0.95 F1-score on ATCO/pilot for SRI on several test sets. The text-based diarization system brings a 27% relative improvement on Diarization Error Rate (DER) compared to standard acoustic-based diarization. These results were on ASR transcripts of a challenging ATC test set with an estimated ~13% word error rate, validating the approach's robustness even on noisy ASR transcripts.
Incorporation of Speech Duration Information in Score Fusion of Speaker Recognition Systems
Aug 07, 2016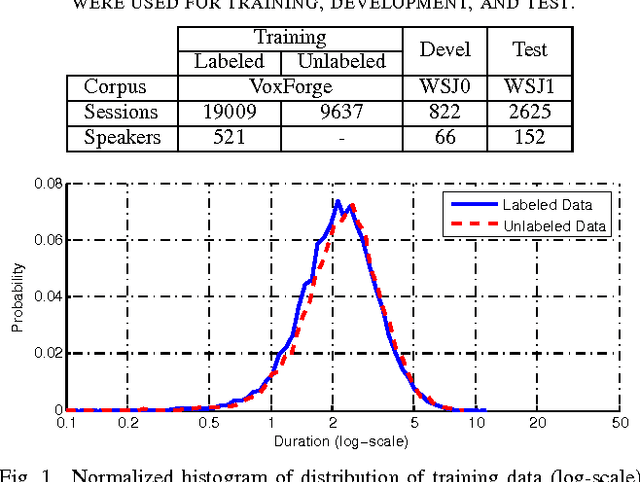
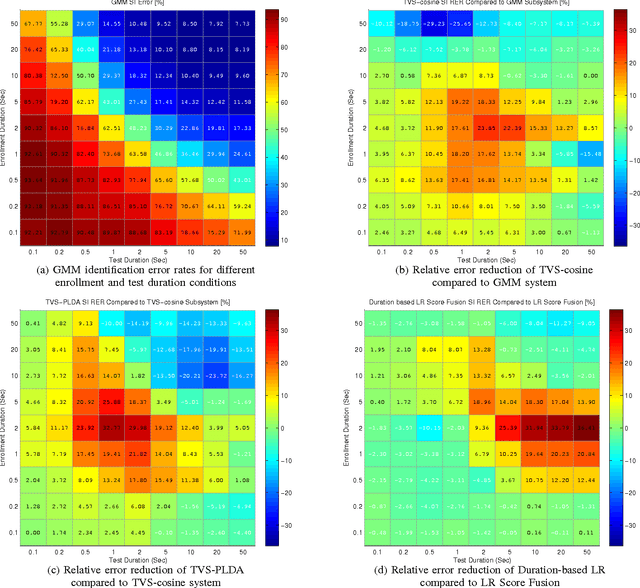

In recent years identity-vector (i-vector) based speaker verification (SV) systems have become very successful. Nevertheless, environmental noise and speech duration variability still have a significant effect on degrading the performance of these systems. In many real-life applications, duration of recordings are very short; as a result, extracted i-vectors cannot reliably represent the attributes of the speaker. Here, we investigate the effect of speech duration on the performance of three state-of-the-art speaker recognition systems. In addition, using a variety of available score fusion methods, we investigate the effect of score fusion for those speaker verification techniques to benefit from the performance difference of different methods under different enrollment and test speech duration conditions. This technique performed significantly better than the baseline score fusion methods.