 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEliciting Information with Partial Signals in Repeated Games
Sep 09, 2021

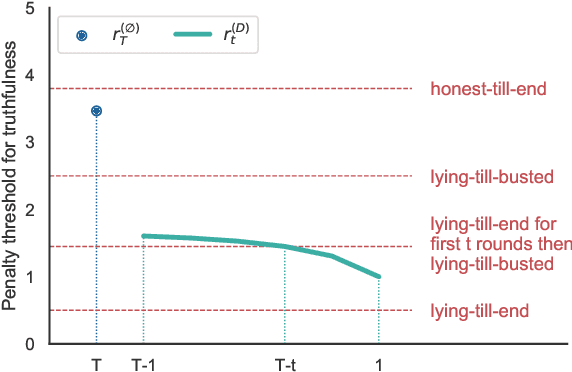
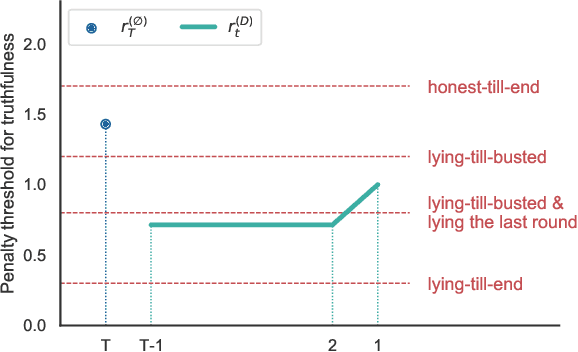
We consider an information elicitation game where the center needs the agent to self-report her actual usage of a service and charges her a payment accordingly. The center can only observe a partial signal, representing part of the agent's true consumption, that is generated randomly from a publicly known distribution. The agent can report any information, as long as it does not contradict the signal, and the center issues a payment based on the reported information. Such problems find application in prosumer pricing, tax filing, etc., when the agent's actual consumption of a service is masked from the center and verification of the submitted reports is impractical. The key difference between the current problem and classic information elicitation problems is that the agent gets to observe the full signal and act strategically, but the center can only see the partial signal. For this seemingly impossible problem, we propose a penalty mechanism that elicits truthful self-reports in a repeated game. In particular, besides charging the agent the reported value, the mechanism charges a penalty proportional to her inconsistent reports. We show how a combination of the penalty rate and the length of the game incentivizes the agent to be truthful for the entire game, a phenomenon we call "fear of tomorrow verification". We show how approximate results for arbitrary distributions can be obtained by analyzing Bernoulli distributions. We extend our mechanism to a multi-agent cost sharing setting and give equilibrium results.
Unknown Presentation Attack Detection against Rational Attackers
Oct 04, 2020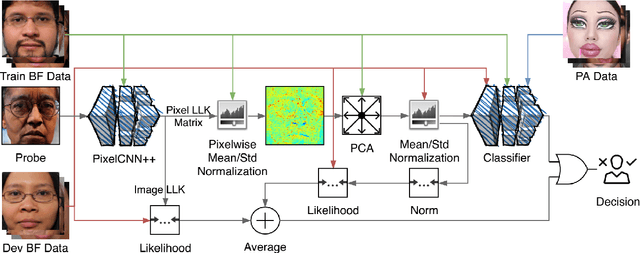


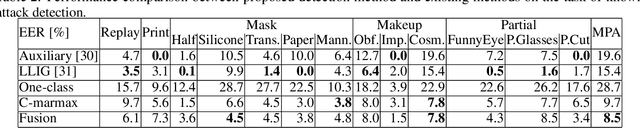
Despite the impressive progress in the field of presentation attack detection and multimedia forensics over the last decade, these systems are still vulnerable to attacks in real-life settings. Some of the challenges for existing solutions are the detection of unknown attacks, the ability to perform in adversarial settings, few-shot learning, and explainability. In this study, these limitations are approached by reliance on a game-theoretic view for modeling the interactions between the attacker and the detector. Consequently, a new optimization criterion is proposed and a set of requirements are defined for improving the performance of these systems in real-life settings. Furthermore, a novel detection technique is proposed using generator-based feature sets that are not biased towards any specific attack species. To further optimize the performance on known attacks, a new loss function coined categorical margin maximization loss (C-marmax) is proposed which gradually improves the performance against the most powerful attack. The proposed approach provides a more balanced performance across known and unknown attacks and achieves state-of-the-art performance in known and unknown attack detection cases against rational attackers. Lastly, the few-shot learning potential of the proposed approach is studied as well as its ability to provide pixel-level explainability.
Maximizing Non-Monotone DR-Submodular Functions with Cardinality Constraints
Sep 03, 2017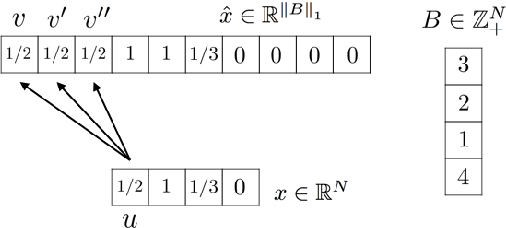
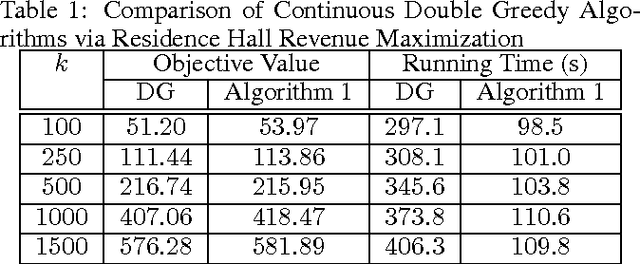
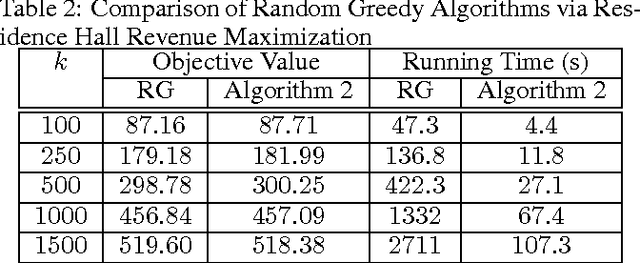
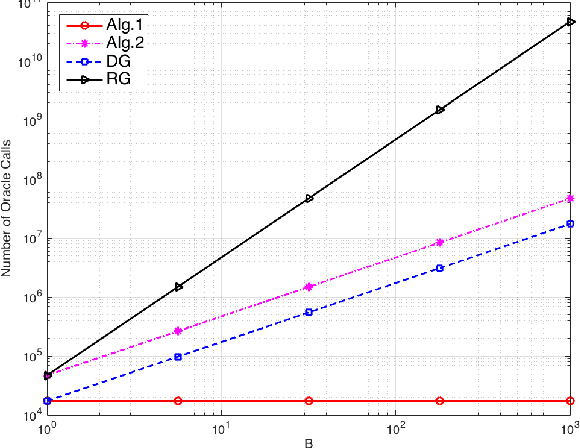
We consider the problem of maximizing a non-monotone DR-submodular function subject to a cardinality constraint. Diminishing returns (DR) submodularity is a generalization of the diminishing returns property for functions defined over the integer lattice. This generalization can be used to solve many machine learning or combinatorial optimization problems such as optimal budget allocation, revenue maximization, etc. In this work we propose the first polynomial-time approximation algorithms for non-monotone constrained maximization. We implement our algorithms for a revenue maximization problem with a real-world dataset to check their efficiency and performance.
Investigation of Synthetic Speech Detection Using Frame- and Segment-Specific Importance Weighting
Oct 10, 2016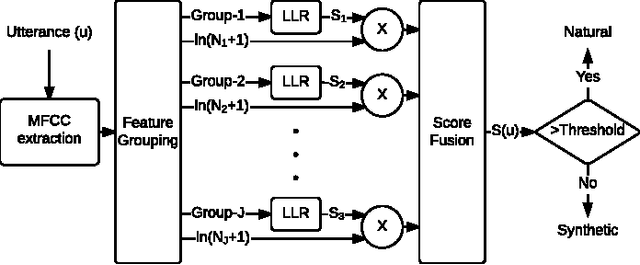
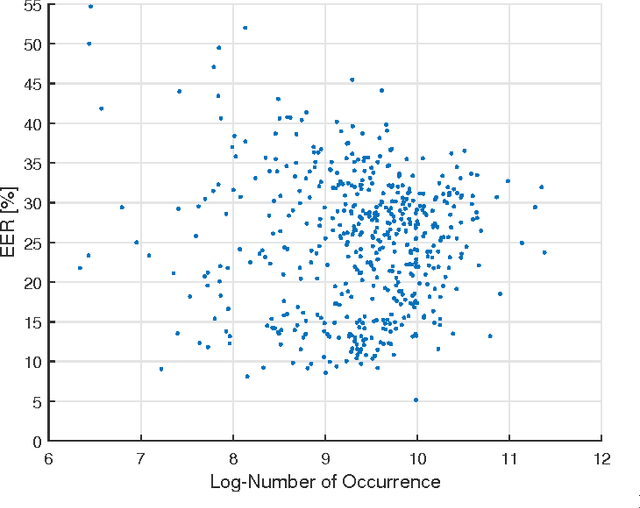
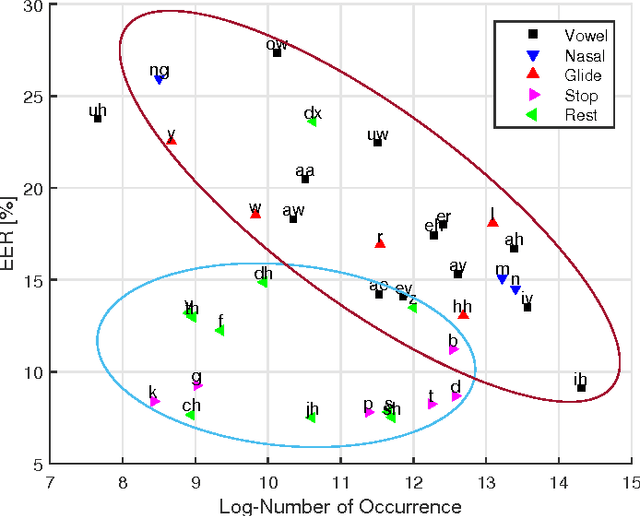
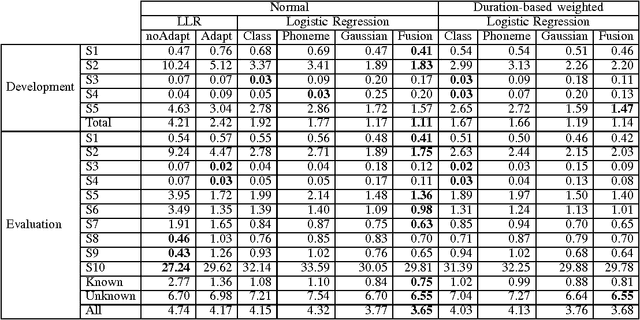
Speaker verification systems are vulnerable to spoofing attacks which presents a major problem in their real-life deployment. To date, most of the proposed synthetic speech detectors (SSDs) have weighted the importance of different segments of speech equally. However, different attack methods have different strengths and weaknesses and the traces that they leave may be short or long term acoustic artifacts. Moreover, those may occur for only particular phonemes or sounds. Here, we propose three algorithms that weigh likelihood-ratio scores of individual frames, phonemes, and sound-classes depending on their importance for the SSD. Significant improvement over the baseline system has been obtained for known attack methods that were used in training the SSDs. However, improvement with unknown attack types was not substantial. Thus, the type of distortions that were caused by the unknown systems were different and could not be captured better with the proposed SSD compared to the baseline SSD.
Incorporation of Speech Duration Information in Score Fusion of Speaker Recognition Systems
Aug 07, 2016
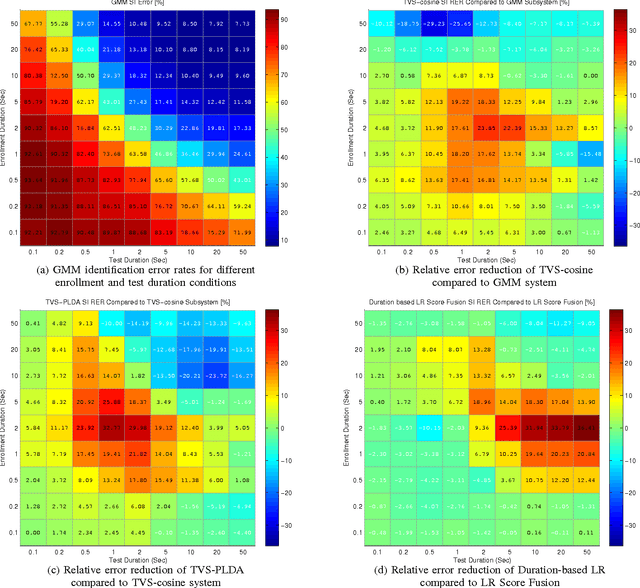

In recent years identity-vector (i-vector) based speaker verification (SV) systems have become very successful. Nevertheless, environmental noise and speech duration variability still have a significant effect on degrading the performance of these systems. In many real-life applications, duration of recordings are very short; as a result, extracted i-vectors cannot reliably represent the attributes of the speaker. Here, we investigate the effect of speech duration on the performance of three state-of-the-art speaker recognition systems. In addition, using a variety of available score fusion methods, we investigate the effect of score fusion for those speaker verification techniques to benefit from the performance difference of different methods under different enrollment and test speech duration conditions. This technique performed significantly better than the baseline score fusion methods.